Branches Are All You Need: Our Opinionated ML Versioning Framework

概要
- Git ブランチを使用して機械学習プロジェクトをバージョン管理しよう
Introduction
- 機械学習プロジェクトが管理している、バージョン管理があるデータ
- モデルの種類 (Bert, LayoutLM, …)
- コード
- モデルの重み
- ハイパーパラメーター
- バイアス
- S3 url
- データ
- トレーニング
- 加工済み
- トラッキングデータ
- モニタリングデータ
これらはすぐに手に負えなくなる

オンプレミスプロジェクトだと顧客ごとにモデルのバージョンも異なって大変・・・!
Gitでデータバージョニング管理
- メリット
- データサイズに関係なく、コードと一緒にデータとモデルファイルをコミットできる
- すべてのファイルをバージョン管理することにより、データとモデル資産の管理の不便さを回避できる
主要な概念
- 全ての変更がコミットとして記録される
- データのアップロード
- 特徴量エンジニアリング
- モデル変更
- コード変更
- 実験結果マージ
- モニタリング
- アクティブなブランチとして残す:
- dev, prdを異なるブランチとして使う運用は一般的
- さらにデータ・コーディングブランチなどを残す運用の提案
- ブランチをチェックアウトすると必要なすべてのデータ、コード、モデル、ドキュメント、Readme、およびメトリクスを含むモデル カードを 1 か所に保管できる
🤯 リポジトリをBLOB ストアのように使ってしまう
(容量大きい時や機密性はどうすんの、とは思った
これにより、さまざまなプラットフォームやツールに依存するのではなく、さまざまな開発、実験、実稼働のニーズに応じてさまざまなブランチを使用できるようになる
- マージがワークフロートリガーになる
ブランチ運用

mainブランチ
- MLタスクの概要説明やディスカッションの場所として使う
- タスク・データの説明
- ドキュメント
- プロジェクトの構造を定義
- 実験結果管理にも使える
- 実験のトラッキングデータをmainブランチにマージする運用にすることで、簡易な実験結果管理場所として使える
- 例えばMLflow のmlruns フォルダーをマージするなど
- 後からMLflow サーバーや Weights and Biases などの追跡プラットフォームにアップグレードできる
Dataブランチ
- データを管理するためのブランチ。アクティブな更新され続ける
- 生のデータファイル(このブログではそうなっている)
- チェックアウトするとDLできるから良いとのこと(正気か?)
- ドキュメント
- 加工用のスクリプト
- Dataブランチから別のブランチを生やしてマージするのではなく、Dataブランチに直接コミット(アップロード) することがお勧めされている
- コミット履歴が更新履歴となる
- 信頼できる情報源、つまり決して編集または削除されない場所を作成するため
- データがどこから来てどこを通過するかを常に追跡できる
- 新しいフローの簡単な作成、監査、ガバネスも可能になる
- 派生したブランチ
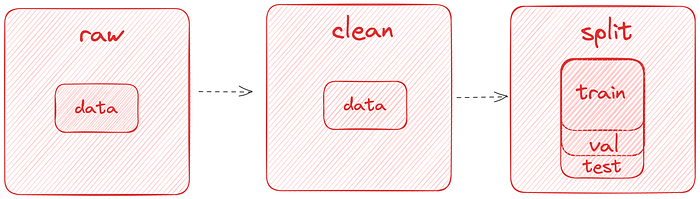
- cleanブランチ: 加工後のデータ
- 壊れた画像や空のテキストファイルが除外されている状態
- splitブランチ: トレーニング、テスト用の分割されたデータ
- training用
- validation用
- test用
- これによってすべてのチームと共同作業者が同じ土俵で作業することが保証されます。
- メリット
- データ漏洩を防止し、より堅牢な機能エンジニアリングとコラボレーションを可能にする
- テストセットの例がトレーニング段階に含まれる可能性を最小限に抑える
- ことで、バイアスが生じるリスクが軽減されます。さらに、すべての共同作業者が同じ分割に参加することで、実験において一貫性があり偏りのない結果が保証されます。
筆者の以前のプロジェクトでは、各人がパイプライン全体をゼロから実行していた。私たちはそれぞれ異なるデータ分割パーセンテージとシードを使用していたため、本番環境ではバグやデータのバイアスに基づいてモデルが脆弱になってしまいました。
stableブランチ
- トレーニングと推論のためのブランチ
- マージされると自動で学習・テストが走る
- Dockerイメージの構築
- トレーニング・テストの実行
- モデルの保存
- Tag付け
⚠️これらのブランチにはコードはコミットされません。
トレーニング後、トラッキングデータのみがメインブランチにマージ (コピー) されます。
(※mainブランチ≠本番環境のブランチ)
最も単純なケースでは、ハイパーパラメータと評価結果を含む JSON テキスト ファイルを使用できます。このファイルは、メインブランチのリストに追加されます。MLflow の場合、実験をmlruns フォルダーからメインブランチにコピーする必要があります。
codingブランチ
- コード開発と データ探索のためブランチ
- 動作するプログラムが完成するまで、サンプリングされたデータまたは小さなデータでトレーニングする
- 追加のデータが取り込まれた場合、コードをさらに変更する必要がない場合にのみ、stableブランチにマージする
- これらのブランチには、推論コード、サーバー、Dockerfile、およびテストが含まれている必要がある(stableブランチで学習を実行するため)
- アクティブなままの開発ブランチが常に少なくとも 1 つあり、すべての新機能、バグ修正、その他の変更がマージされる
💡 ML および MLOps エンジニアは、トレーニングと推論の面で共同作業できます。
ブランチ開発例
- ベースラインモデルを開発するdev/modelブランチを作成
- 安定してテストに合格したら、 stable/modelブランチを生やす
- モデル、コード、データをトレーニングしてリモートにコミット
- 開発タグ付け
- dev/modelブランチで改善版のモデルを開発
- 準備が整ったらStable/modelにマージ、トレーニング
- 本番リリースできそうであれば本番リリースタグ付けを行う
このアプローチにより、安定ブランチ内の以前のモデルの完全なコンテキストを保持しながら、モデルを段階的に改善する自由が得られます。
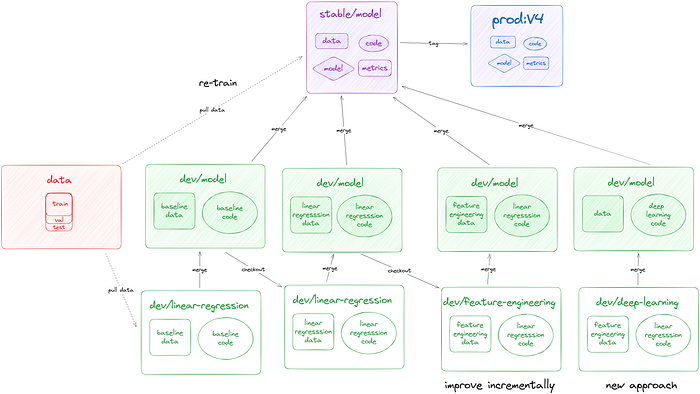
こんなこともできるよ
- データをstableブランチにプルすることで、自動で再トレーニングできる
- dev/linear-regressionブランチをはやして特徴量エンジニアリングの実験管理
- より洗練されたモデル用に新しい dev/new-approachブランチを作成できます。
Monteringブランチ
- データの分布、外れ値、予測分布に注目
- クエリされたデータ、コミットタグ、本番環境のモデル予測値をファイルとして保存
💡 環境ごとに複数の監視ブランチ (dev、stable、prod) を使用できます。
これにより、このブランチにもモデルを保存できるため、外れ値検出モデルなどのより高度なソリューションが可能になります。
