
2024-09-26 機械学習勉強会
今週のTOPIC[blog] KPIのモニタリング自動化と運用体制の整備[slide] 研究の進め方 ランダムネスとの付き合い方についてGPU Puzzles[slide] ついに出た!OpenAIの最新モデル「o1」って何がすごいの?[blog] 名寄せの定量評価とGroup Sequential Test[論文] Retrieval Augmented Generation (RAG) and Beyond: A Comprehensive Survey on How to Make your LLMs use External Data More Wisely[blog] テキスト生成APIサーバのスループットを高めるbatching algorithmsPerformance of Human Annotators in Object Detection and Segmentation of Remotely Sensed Data概要関連研究実験実験条件結果考察
今週のTOPIC
※ [論文] [blog] など何に関するTOPICなのかパッと見で分かるようにしましょう。
出典を埋め込みURLにしましょう。
@Naoto Shimakoshi
[blog] KPIのモニタリング自動化と運用体制の整備
- ZOZO Techblog
- 背景
- 推薦システムごとにKPIを策定しているが、データの欠損やリリース時の不具合によってKPIが意図しない値を取ることがあるため定常的に確認する必要がある。
- Lookerで運用していたが、いくつか問題が出てきたので改善した話。
- 具体的な課題
- トレンドを考慮した異常検知が不可能
- モニタリングの設定が面倒
- yamlでやっていたが1個1個の指標に設定するの大変
- アラート対応フローが不明確
- 対応者がシステムを作った人に限られてしまうという属人化の問題
- サマリの定期配信が形骸化
- 解決案
- 異常検知の自動化
- BQで集計していたのをVertex AI Pipelinesに移行
- prophetを利用してトレンド、不確定区間などを考慮した動的な閾値を設定
- 設定を指標ごとに設定していたのをテーブルごとに変更
- アラート対応フローの整備
- 以下のように整理
- データに問題があるか、モデルに問題があるか、アラートの設定に問題があるかなどの切り分けを行う
- ダッシュボードを見る会の運用
- 形骸化しないように、週に1回ダッシュボードを見る会を開催することで積極的にKPIの状況を把握する体制を構築

@Yuya Matsumura
[slide] 研究の進め方 ランダムネスとの付き合い方について
- 研究の進め方とありますが、あらゆる不確実性を伴うプロジェクトに応用可能な考え方だと思いました。

- 不確実性には大きく2つある
- 認識的不確実性:データを増やせば消える不確実性 = コントロール可能
- 偶発的不確実性:データを増やしても消えない、環境自体の不確実性
@Tomoaki Kitaoka
GPU Puzzles

- GPUアーキテクチャは機械学習において重要ですが、GPUコードを使わずにエキスパートになることも可能です。
- このノートブックは、NUMBAを使ったインタラクティブな形式で初心者向けのGPUプログラミングを教えることを目的としています。
- パズルを通じて、GPUプログラミングの基本概念(例えば、スレッド、ブロック、共有メモリ)の学習やNUMBAを使ったCUDAカーネルの記述を通じてGPUでの並列処理の仕組みを体験できます。
@Yuta Kamikawa
@Shun Ito
[blog] 名寄せの定量評価とGroup Sequential Test
- Sansanさんのテックブログ
- 名寄せアルゴリズムの定量評価のはなし
- 既存手法・新手法の精度を比較して統計的検定で評価する際、サンプルサイズ(名寄せ対象のデータサイズ)を抑えたい
- Group Sequential Test (GST) を使って抑える
- GST: 逐次的に中間解析を行い、途中で有意となった時点で終了する
- 棄却域は ”アルファ消費” を利用する
- 中間解析の回数分だけアルファを分割し、中間解析ごとに「消費」していく方法
- k回目の解析の時のアルファは、α*(t_k) - α*(t_{k-1}) で定め、消費の仕方を決めるエラー消費関数が複数存在する

- 実際にリリース後の評価をGSTで実施

@qluto (Ryosuke Fukazawa)
[論文] Retrieval Augmented Generation (RAG) and Beyond: A Comprehensive Survey on How to Make your LLMs use External Data More Wisely
RAGといっても扱う問題の性質や、利用可能な外部データの事情によって解き方は様々だよねということをサーベイしてまとめた論文。
Microsoft Research Asia のメンバーによるプレプリント。
上記の様々だよねという話を4段階に分け、それぞれに対して各種アプローチを紹介している

- Level 1: 明示的な事実に対するクエリ
- 例: "Where will the 2024 Summer Olympics be held?"
- Level 2: 暗黙的な事実に対するクエリ
- 例: "What is the majority party now in the country where Canberra is located?"
- Level 3: 解釈可能な理論的根拠に対するクエリ
- 例:
- FDA(米国食品医薬品局) Guidance documents に合わせた薬の適用
- カスタマーサポートにおける定義済みワークフローに合わせた問い合わせ対応
- “Do I qualify to apply for a five-year Japanese tourist visa in Shanghai?”
- Level 4: 隠れた理論的根拠に対するクエリ(理論的根拠が明示的に記録されていないが、外部データに見られるパターンや結果から推測しなければならないような問題)
- 例:
- ソフトウェア開発における、過去バグ修正の意思決定履歴に基づいた問題に対する回答
- “How will the economic situation affect the company’s future development?”
各レベルに対するアプローチのサマリはこちら。

@Yosuke Yoshida
[blog] テキスト生成APIサーバのスループットを高めるbatching algorithms
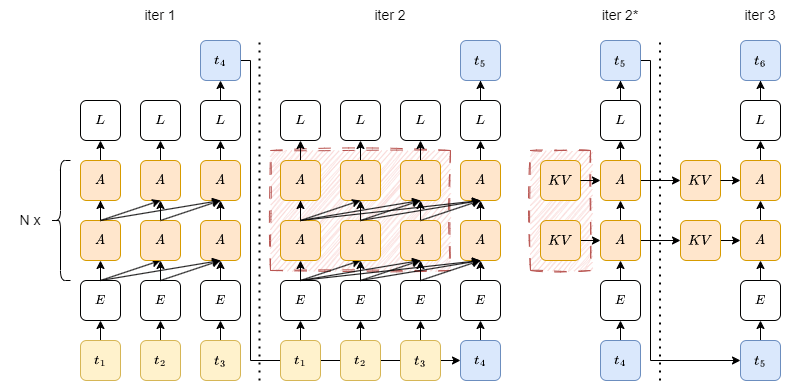
- causal language modeling
- iter2は中間の計算結果をキャッシュ(KV cache)しておくことでiter2*のように計算コストを削減できる
- iter1を prefill フェーズ、iter2*, iter3 を decode フェーズと呼ぶ
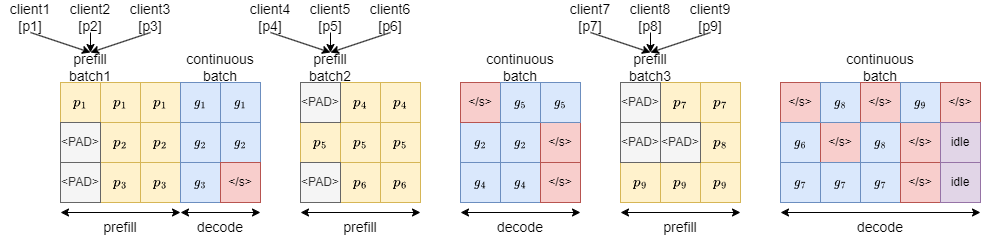
- Continuous batching
- クライアントからリクエストが来たら prefill フェーズのみ計算しそれぞれの KV cache を保存してキューに追加
- キューにある KV cache をバッチにまとめて decode フェーズを計算、1トークンだけ生成して KV cache を更新しキューに戻す
- 生成が終了した KV cache はキューに戻さずにクライアントに生成結果を送信する
- 生成されるトークンの長さが大きく異なる場合でも無駄なアイドルが発生しない
Performance of Human Annotators in Object Detection and Segmentation of Remotely Sensed Data
Roni Blushtein-Livnon , Tal Svoray , and Michael Dorman
‣
- 近年は高品質なデータの需要が高い → アノテーションの品質が重要視される
- どのようにアノテーションをすれば品質高くアノテートされたデータが得られるかを知りたい
→ アノテーション時のどの条件が制度に影響するかを調査した
概要
アノテーターのパフォーマンスが何に左右されるかを評価したい
- リモートセンシング分野の、航空写真からソーラーパネルを検出するというタスクを採用
- 物体検出とセグメンテーションを同時にやるタスク
- 同じ画像中でもソーラーパネルの見え方は変わってくる
- アノテーションタスクとしては複雑・難しい
…通常のアノテーションタスクと異なる点
- 切り口は3点
- アノテーションの内容
- 物体検出 or セグメンテーション
- 個人 or グループ、独立 or 従属
- アノテーションするデータの特性
- アノテーターの経験
- ドメイン知識の有無、アノテーションをやったことがあるか等
- 結論
- 物体検出タスクの方が、セグメンテーションタスクよりも品質が高い
- アノテート対象の密度は、高い方が品質が高い
- アノテーターの経験はあまり大きな影響はない
関連研究
- ‣
- クラウドソーシングによるラベリングの品質についての調査
- ラベリング対象の研究領域に関して専門的な知識があるかどうかは、アノテーションの精度に影響する(専門家によるラベリング精度>非専門家のラベル精度)
- 同時に、モデルの精度にも影響する
- ‣
- どのようにアノテーションさせるのが効果的かを調査
実験
実験条件
- 被験者(アノテーター):24人
- 学部1,2年生、男女比ほぼ1:1
- リモートセンシングに関する素養を全員持っている
- うち、6人はアノテーションの専門家
- 平均で22ヶ月、アノテーションの経験があり
- アノテーション内容は2つ
- 物体検出
- セグメンテーション(ピクセル)

例えばAは1つ検出漏れ(FN)、Bは1つ余計なものを検出している(FP)、Cはセグメンテーション範囲が足りない(FN)、Dはセグメンテーション範囲が広い(FP)
- アノテーション戦術
- 2グループに分ける
- 1グループには独立にアノテーションをしてもらい、最頻値を最終的なアノテーション結果とする(物体検出では 2人以上がラベル付けしたもの、セグメンテーションでは2人以上が選択したピクセルを選ぶ)
- 1グループには依存する形でアノテーションをしてもらう。初めのアノテーターのアノテーション結果を、他の人間が順々にレビューする。最後のレビュー結果をアノテーション結果とする。
- タスク条件
- データの性質で2種類に分ける
- 検出したい物体が密集しているか、していないか
- アノテーション経験
- グループでアノテーションしてもらう、最頻値をアノテーション結果とするが、経験者のアノテーション結果に重みつけ(2票分)する

結果
- セグメンテーションより物体検出タスクの方が良いスコア(精度高い)

- 個人 or グループ、独立or従属、密or疎
- (Precision, Recall の順)

- t検定によるp値(*は有意、**は特に有意)
- 密or疎、個人orグループ、独立or従属で特に有意

考察
- 物体検出の精度・再現率 > セグメンテーションの精度・再現率
- セグメンテーションはより複雑なタスクで、認知的要求がより高い
- 要求されるスキルがそれぞれ異なる
- FPよりもFNのエラーを起こす傾向がある(=間違うリスクをとりたがらない)
- 不確実な物体を避ける傾向
- プロスペクト理論に一致する
‣
→ これを緩和するためには、リスクをとることにインセンティブを与えるような設計にする
or 確信度低くマークしたものを、次のアノテーターにレビューしてもらうような設計にする
- 多数決の形式をとった方が品質がよい
- レビューする人間がバイアスを受ける
- 自分の役割を正当化するために、確信度低い物体でもマークする、など
- 一方で、消すことはためらう傾向
- レビュー形式をとっても、見逃しは避けられない
→ 同じアノテーションタスクを並行して行うことが推奨される
- アノテーション対象が分散していない方が品質高くアノテーションできる
- 広範囲を探索すると誤検出が増える(疲れるので)
- 密集していれば同じ視界で比較しやすく、アノテーションに周囲のコンテキストを活用できるようになって、品質が高くなる
→ばらけるような場合には、分割すると良い
- アノテーションの経験の有無で有意な差がない
- 逆に、無意識や注意散漫な状態でアノテーションを実行して、パフォーマンスが落ちていることもある
→「専門家」のアノテーション結果を優先する利点はない