
2024-10-10 機械学習勉強会
今週のTOPIC[slide] 能動学習ライブラリ・ツールの紹介[blog] QueryGPT – Natural Language to SQL Using Generative AI[blog] 現場から学ぶMLOps: MonotaROでの実践的アプローチ~オンライン推論編~[論文] AHP-Powered LLM Reasoning for Multi-Criteria Evaluation of Open-Ended Responses[論文] COSMO: A Large-Scale E-commerce Common Sense Knowledge Generation and Serving System at Amazon[blog] Transformers KV Caching ExplainedEfficient Memory Management for Large Language Model Serving with PagedAttention概要LLM推論の課題非効率なKVキャッシュ管理メモリ共有ができないPagedAttentionの仕組み処理の流れメリットメモリ共有処理の流れ
今週のTOPIC
※ [論文] [blog] など何に関するTOPICなのかパッと見で分かるようにしましょう。
出典を埋め込みURLにしましょう。
@Naoto Shimakoshi
[slide] 能動学習ライブラリ・ツールの紹介
- Goの勉強会資料
- あまり体系的にまとまってない能動学習のライブラリなどについてまとめてくれている。

- スライドでではmodALとALiPy、Label-Studioについて紹介
- modAL
- sklearnのClassifierやRegressorと戦略を設定すれば、サンプリングできる
- Pytorch → sklearnへ変換するラッパーとかを使えば可能。(というのがある模様)
- サンプリング手法は不確実性サンプリングが実装されており、アンサンブル結果から不確実性サンプリングできたりもする。
- ベイズ最適化でサンプルを選べたりもする
- Alipy
- modelはラップしなくて大丈夫で、精度やモデルの予測値だけをSaverに保存する
- 色々と能動学習アルゴリズムがある (https://parnec.nuaa.edu.cn/huangsj/alipy/)
- アノテーションコスト(時間とか)を停止基準に入れれたり、ノイズが多いサンプルなどを考慮させたりできる。

- Label Studio
- Label StudioとLabel Studio Backend MLをインストールして使う。
- 無償版ではモデルの予測結果を使ってサンプリングできないが予測値などは見ることができる。
- 課題
- 全体として論文での手法の有効性を確かめるみたいな形に最適化されてしまっている。
- ここ数年の最新のアルゴリズムは載ってない。
- 能動学習が有効なのか
@Tomoaki Kitaoka
[blog] QueryGPT – Natural Language to SQL Using Generative AI
- QueryGPTは、大規模言語モデル(LLM)、ベクトルデータベース、および類似性検索を使用して、ユーザーが入力した英語の質問から複雑なクエリを生成する
- Hackdayz (version 1)
- QueryGPTの最初のバージョンは、シンプルなRAG(Retrieval-Augmented Generation)を使用して、クエリ生成呼び出しに必要な関連サンプルを取得するものでした(Few Shot Prompting)。ユーザーの自然言語プロンプトをベクトル化し、SQLサンプルとスキーマに対して類似検索(k-nearest neighbor検索)を行い、3つの関連テーブルと7つの関連SQLサンプルを取得していた。
- 課題
- 生成クエリの精度低下:
- 初期バージョンでは、スキーマとSQLサンプルを追加するたびに、生成されるクエリの精度が低下。
- 単純な類似検索だけでは、ユーザーの自然言語プロンプトに対して適切なスキーマやSQLサンプルを見つけられない場合があった。
- ユーザーの意図を適切に理解できない:
- ユーザーの自然言語プロンプトから適切なスキーマを特定することが困難で、直接的にユーザーの意図とスキーマの対応関係を結びつけるのがが難しかった。
- 大規模スキーマの処理が難しい:
- 一部のテーブルは200以上の列を持ち、1つのテーブルで大量のトークンを消費することがあり、特に大規模なテーブルを含むリクエストは、トークン制限によりLLM呼び出しが失敗することがあった。

- 現在の設計
- ワークスペースの導入による精度向上:
- 現在の設計では、ビジネスドメインごとにSQLサンプルとテーブルをまとめた「ワークスペース」を導入。これにより、特定のビジネス領域に関連するクエリ生成の焦点を絞り、生成されるクエリの精度と関連性が向上。
- インテントエージェントによる意図の理解強化:
- 「インテントエージェント」がユーザーのプロンプトを特定のビジネスドメインやワークスペースにマッピングすることで、適切なスキーマやSQLサンプルの特定が可能になり、これにより、ユーザーの意図に応じたクエリ生成が可能に。
- テーブルエージェントによる正確なテーブル選択:
- ユーザーがクエリ生成に使用するテーブルを手動で確認・修正できる「テーブルエージェント」を追加し、生成クエリの精度を向上。これにより、不正確なテーブル選択による問題を解決。
- カラムプルーンエージェントによるトークン制限問題の解決:
- 「カラムプルーンエージェント」を導入し、不要な列を削除してスキーマをスリム化。これにより、トークンサイズを減少させ、LLM呼び出しのコスト削減と待ち時間の短縮を実現。

- 評価
- 評価手順
- 評価手順は柔軟で、プロダクションおよびステージング環境におけるクエリ生成プロセスのシグナルをキャプチャできます。異なるプロダクトフローを使用して、QueryGPTの性能を測定します。
- プロダクトフローの例
- 評価項目
- Intent(意図の正確さ):質問に割り当てられた意図が正しいかどうか。
- Table Overlap(テーブルの重複度):生成されたクエリで使用されるテーブルが正しいか。
- Successful Run(クエリ実行の成功):クエリが正常に実行されるか。
- Run Has Output(出力の有無):クエリの実行結果にデータが含まれているか。
- Qualitative Query Similarity(クエリの類似度):生成されたクエリがゴールデンSQLとどれほど似ているか。
| Product Flow | Purpose | Procedure |
| Vanilla | QueryGPTのベースラインパフォーマンスを測定 | 質問を入力し、QueryGPTが意図と必要なデータセットを推論。推論したデータセットと意図を用いてSQLを生成し、意図、データセット、SQLを評価。 |
| Decoupled | ヒューマンインザループの体験での性能測定。コンポーネントレベルでの評価を実現。 | 質問、意図、データセットを入力し、QueryGPTがSQLを生成(実際の意図とデータセットを使用)。意図、データセット、SQLを評価。 |
- 結果


- 学び
- LLMは優れた分類機能を持つ:LLMは、特定の単位のタスクに集中させると非常に効果的に動作する。意図エージェント、テーブルエージェント、カラムプルーンエージェントは、それぞれ専門化されたタスクで精度向上に貢献した。
- 幻覚問題:LLMは時折、存在しないテーブルや列を含むクエリを生成する。この問題に対処するため、プロンプトの改善やチャット形式での反復的な修正、検証エージェントの導入を模索しているが、完全な解決には至っていない。
- ユーザープロンプトの質:ユーザーの質問は常に十分なコンテキストを含むとは限らず、単語数の少ない質問やタイプミスが含まれることがある。このため、質問をLLMに送る前に「プロンプトエンハンサー」で文脈を補強する必要があった。
- 高い期待値:ユーザーは生成されるSQLに対して非常に高い精度と信頼性を期待している。そのため、製品の初期ユーザー基盤は適切なペルソナに絞ることが重要だった。
@Yuta Kamikawa
[blog] 現場から学ぶMLOps: MonotaROでの実践的アプローチ~オンライン推論編~
- MonotaROのWebサイトにおける検索結果のパーソナライゼーションについてのMLOpsの取り組み
- 検索結果のパーソナライズドランキングがABテストで成果を残したので、恒久対応することになったのが背景
- MLOpsプロジェクトを0から始めた際の悩み事
- この辺困りそうというのは肌感でわかるが、今手を付けるべきかの判断が難しい
- 分析するための環境やサービスを動かす環境などのインフラ面
- 事業の差や、求められる機能の違いなどのサービス面
- MonotaROでは学習〜評価周りがデータサイエンティストの担当で、ユーザーに届ける実装部分は機械学習エンジニアが担当となっている
- お互いの理解度が低く、お互い課題が見えている状態ではない
運用中の機械学習モデルがまだ少ないこともあり、課題が明確化されていない
他社事例を参考にしようにも、自社環境との差分が大きくあまり参考にはならない
アルゴリズムを考えるデータサイエンス側と組織的に分かれていたこともあり、機械学習モデルの学習や評価周りには手を付けづらい
- 悩んだままだと時間が過ぎるだけなのでとりあえず始めた
- データサイエンス側が持つ機械学習モデルの学習、評価周りには一旦手を出さず、機械学習エンジニアが単独で触れるシステム(バックエンド、インフラ)の運用最適化に注力する
- モデルの定期更新や正常に動いているかの監視など、機械学習モデルの外側から埋めていく
- 今後運用する機械学習モデルが増えることも考えてシステムの横展開の準備を進めていく
- 確実な100点はわからないので、自分が思いつく100点を試してみる。「だめそうであればすぐやめる」をモットーに進める
この時の取り組みは以下のとおりです。
- MLOpsを取り組んでみての感想と学び
- 他社の取り組みとかを見てもそれが当社に合うのかが不明
- 明確になっている課題や、直近で課題になりそうな部分から潰していくしかない
- 事例が少ない状況で基盤を作ってもユースケースが増えていき、全てに対応出来るのかわからない
- 事例数も少ないのでが明確になりづらい
- これまではエンジニア側に近い部分しか触れていないが、学習〜評価周りにも課題はある
- アルゴリズム開発と連携し、お互いの困りごとを共有することが大事
- 何が正解かわからないのでとりあえずやってみる
- やってみてだめだったらすぐに捨てる(撤退のしやすさも大事)
MLOpsには正解がない
事例数が少ないタイミングで基盤化が難しい
MLOpsを進めるためにはアルゴリズム開発とエンジニアリングの両面に立つことが必要
とりあえずやってみる精神で進めていくことが大事
@Shun Ito
[論文] AHP-Powered LLM Reasoning for Multi-Criteria Evaluation of Open-Ended Responses

- EMNLP 2024 Findings
- 概要
- オープンエンド型の質問(例: 今日のランチはどこの店にする?)に対する回答を評価したい
- LLMで評価させるときに、AHP(Analytics Hierarchy Process)の仕組みを用いて評価の品質を改善する方法を提案
- AHPによって、Pairwise Comparisonなどの評価方法よりも人間に近い評価を出せることを実験的に示した
- AHPとは
- AHP: 複数の評価基準を使って意思決定を行う手法
- 各基準の重要性を評価し、それを用いて最終的なスコアを算出する
- 提案手法
- LLMを使い、AHPのプロセスに則って評価基準を生成し、回答を評価する
- 評価基準の生成
- データセット(質問 x 回答 x 評価スコア)の一部をランダムに抜き出し、その要素同士でペアワイズ比較させる。
- 「1つ目の回答が2つ目の回答より優れている理由」を2~3個抽出させ、すべてのペアに対して抽出した後最も頻度の高いかつ重要な理由k個を評価基準として採用する。
- 回答の評価
- k個の評価基準について、回答 i の回答 j に対する良さを5段階で評価
- 回答 i の 回答 j に対する良さの5段階それぞれにスコアを与え、k個の評価基準は上位のものほど大きい重みを与える。これらを用いて各回答に対するスコアを計算する。


- 実験(一部抜粋)
- RQ1. 提案手法がオープンエンド型の質問に対する回答を効果的に評価できるか
- 結果: AHPが比較手法と比べて、最も人間に近い評価を出せている
- 比較手法
- Pairwise Comparison: 単純に2つの回答のうちどちらが良いかを答えさせる
- Scoring: 個々の回答に100点満点で点数をつけさせる
- Few-shot: 良い例・悪い例を与えた上で点数をつけさせる
- level: CERF(英語ライティングの評価基準)を与えた上で評価させる
- 評価スコアの評価方法
- 正解の評価スコアとの一致度(concordance index): ある2つのアイテムの順序関係を見た時にどれだけ一致しているか
- データセットは4種類
- 評価基準の生成では、それぞれ回答を10個ずつサンプリング。生成された225の基準のうち上位10件を採用。


@qluto (Ryosuke Fukazawa)
[論文] COSMO: A Large-Scale E-commerce Common Sense Knowledge Generation and Serving System at Amazon
これまでの Knowledge Graphs では実現が難しかった、ユーザーの意図を踏まえたショッピング体験改善を行うためのシステム COSMO の紹介。
- ユーザの行動履歴を用いて Knowledge Graphを構築するためのデータを生成

- 生成されたデータに対してフィルタリングを行い品質を高めた
- Rule-based Filtering, Similarity Filtering, Human-in-the-loop Annotation
- 手に入ったデータを指示形式に変換した上で LLaMA 7bや13bをファインチューニング。COSMO-LMを作成

- 知識の構造化:
- 生成された知識を15種類の関係タイプ(usedFor, capableOfなど)に分類
- 製品カテゴリー、関係タイプ、タスクタイプなどの次元で知識を組織化
- 大規模な知識生成:
- COSMO-LMを使用して、18の主要カテゴリーに対して数百万の知識を生成
- 生成された知識の質をさらに評価し、高品質なものを選別
- 知識グラフの構築:
- 生成された知識を使って、階層的な知識グラフを構築
- 例: 大まかな概念(キャンプ)から詳細な概念(冬のキャンプ)へと展開
- 継続的な改善:
- オンラインでの使用結果をフィードバックとして活用
- 日々のユーザー行動データを基に知識を更新
結果として、以下のような体験向上を達成できた
- 検索関連性の向上:
- クエリと製品間の意味的なギャップを埋める
- 例: "冬服"というクエリに対して、"暖かさを提供する"という意図を理解し、適切な製品を推薦
- セッションベース推薦の改善:
- ユーザーの検索クエリや行動履歴から意図を推測し、より適切な製品を推薦
- 特に、電子機器カテゴリーなど、複雑な検索パターンを持つ分野での推薦精度が向上
- 多段階ナビゲーション:
- 広範な概念から具体的な製品タイプ、さらに細かい属性まで、段階的に絞り込むナビゲーションが可能に
- 例: "キャンプ" → "エアマットレス" → "キャンプ用エアマットレス" → "湖畔キャンプ用"と絞り込み
- 製品中心から顧客中心のアプローチへの転換:
- 従来の製品分類だけでなく、顧客の意図や行動に基づいた推薦が可能に
- クエリ理解の向上:
- 曖昧な検索クエリに対して、ユーザーの潜在的な意図を推測し、より適切な製品を提案
- 補完的製品の推薦:
- 共同購入データから、関連性の高い補完製品を推薦
- パーソナライズされた検索体験:
- ユーザーの過去の行動や意図を考慮した、よりパーソナライズされた検索結果や推薦を提供
- 属性ベースのリファインメント:
- ユーザーの好みに合わせて、製品の特定の属性に基づいて検索結果を絞り込む
事業インパクトとしても大きな成果が得られている
- 製品販売の0.7%相対的増加(年間数億ドルの収益増加に相当)
- ナビゲーション利用率の8%増加
- 検索関連性指標(Macro F1, Micro F1)の大幅な向上
@Yosuke Yoshida
[blog] Transformers KV Caching Explained
- メイントピックの事前知識としてKVキャッシュの仕組みがアニメーションで分かりやすい
Efficient Memory Management for Large Language Model Serving with PagedAttention
- Woosuk Kwon, Zhuohan Li, Siyuan Zhuang, Ying Sheng, Lianmin Zheng, Cody Hao Yu, Joseph E. Gonzalez, Hao Zhang, Ion Stoica
- SOSP 2023
概要
- LLM推論のスループットを上げるにはバッチサイズを大きくする必要があるが、既存の実装では、KVキャッシュを効率的に管理できておらず、メモリを無駄に消費し、バッチサイズを大きくすることができない
- この問題に対処するために、効率的なKVキャッシュや柔軟にメモリの共有を行うPagedAttentionとPagedAttentionを用いて高速にLLM推論、サービングを行うvLLMを開発
- HuggingFace Transformers(HF)とHuggingFace Text Generation Inference(TGI)とvLLMのスループットの比較
- vLLMはHFと比較して最大24倍、TGIと比較して最大3.5倍のスループットを達成
- 引用元 https://blog.vllm.ai/2023/06/20/vllm.html?utm_source=pocket_shared

LLM推論の課題
非効率なKVキャッシュ管理
- 下図は13Bパラメータを持つLLMで推論する際のメモリレイアウトと、バッチサイズを増やしたときのKVキャッシュメモリとスループットのグラフ
- モデルパラメータは一定であるため、KVキャッシュの管理方法がバッチサイズを決定するうえで重要
- 既存システムでは、バッチサイズの増加に伴い急激にKVキャッシュも増加し、バッチサイズを増やすことができず、結果としてスループットが低い

- KVキャッシュのサイズはシーケンスの長さに応じて変わり、その寿命や長さが事前にはわからないという問題があるため、次の3つの主要なメモリの無駄が発生する
- 予約 (reserved)
- 将来生成されるトークンのために予約されているメモリスロット
- 内部断片化 (internal fragmentation)
- 最大系列長を考慮して過剰にメモリが割り当てられ、実際には使用されないメモリ
- 外部断片化 (external fragmentation)
- メモリアロケータの影響による断片化
- 異なるサイズのメモリブロックの割り当てが何度も行われることで使用されなくなったメモリ領域が散在

- KVキャッシュの内訳を見ると、既存システムではKVキャッシュの20.4%~38.2%しか実際のトークンの保存に使用されていない

メモリ共有ができない
- LLM推論では、並列サンプリングやビームサーチのようなリクエストに対して複数の出力を生成するアルゴリズムが使用されるが、KVキャッシュがそれぞれ異なるメモリ空間に保存されているため共有することができない
PagedAttentionの仕組み
- OSの仮想メモリとページングのアイデアに着想を得たattentionアルゴリズム
- 従来のattentionアルゴリズムとは異なり、PagedAttentionでは連続したKeyとValueを非連続のメモリ空間に格納する
- PagedAttentionは各シーケンスの KVキャッシュをブロックに分割し、各ブロックには固定数のトークンのKeyとValueが含まれる
- シーケンスの連続した論理ブロックはブロックテーブルを介して非連続の物理ブロックにマップされ、新しいトークンが生成されるとオンデマンドで新しいブロックが割り当てられる
- attentionの計算中、PagedAttentionカーネルはこれらのブロックを効率的に識別して取得する
処理の流れ
- プロンプトには7つのトークンがあり、最初の2つの論理KV Block 0, 1 を、2つの物理KV Block 7, 1 にマッピングし、ブロックテーブルに記録する
- 新しく生成されたトークン fathers のKVキャッシュは論理KV Block 1の余っているスロットに保存され、ブロックテーブルの # filled が更新される
- 次に生成されたトークン brought のKVキャッシュは論理KV Block 1 が埋まっているので新しく論理KV Block2, 物理KV Block 3を割り当て、ブロックテーブルに記録する

メリット
- メモリの断片化の緩和
- 連続したメモリ空間が不要になるため、メモリ断片化の問題が軽減
- メモリの効率的な利用
- 各ブロックが小さな固定サイズのため、メモリの確保を動的に行え、必要なメモリだけを利用する
- メモリの無駄はシーケンスの最後のブロックでのみ発生
- 共有と管理の容易さ
- KVキャッシュをブロック単位で管理するため、複数のリクエストやシーケンス間で柔軟にメモリを共有できる
メモリ共有
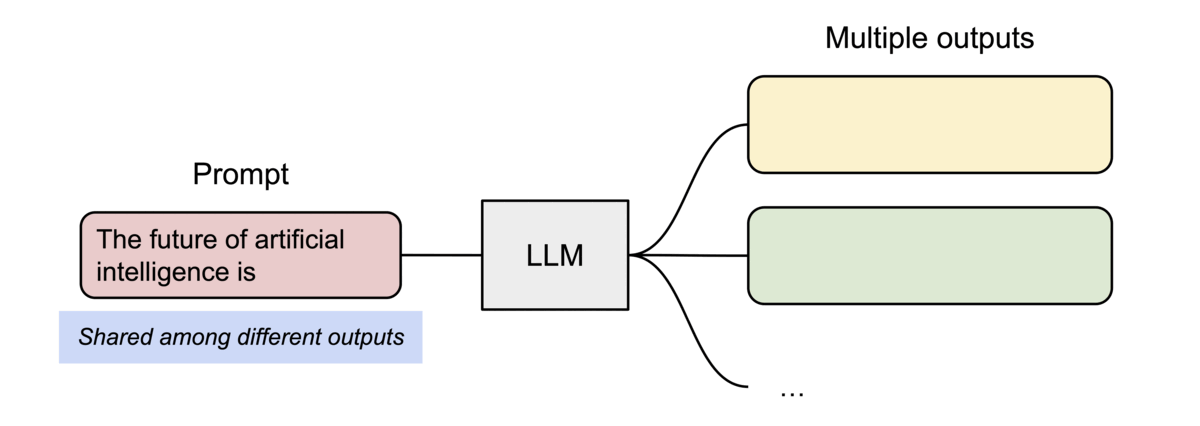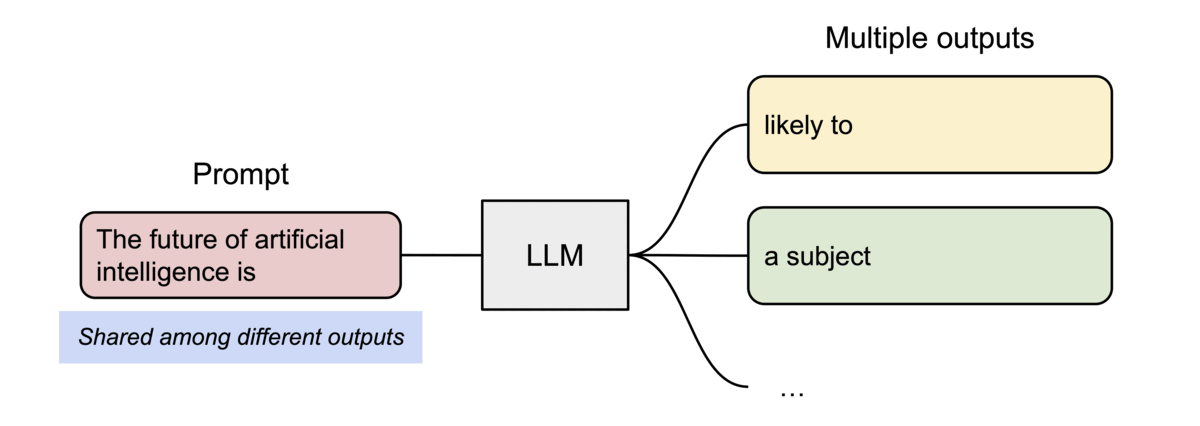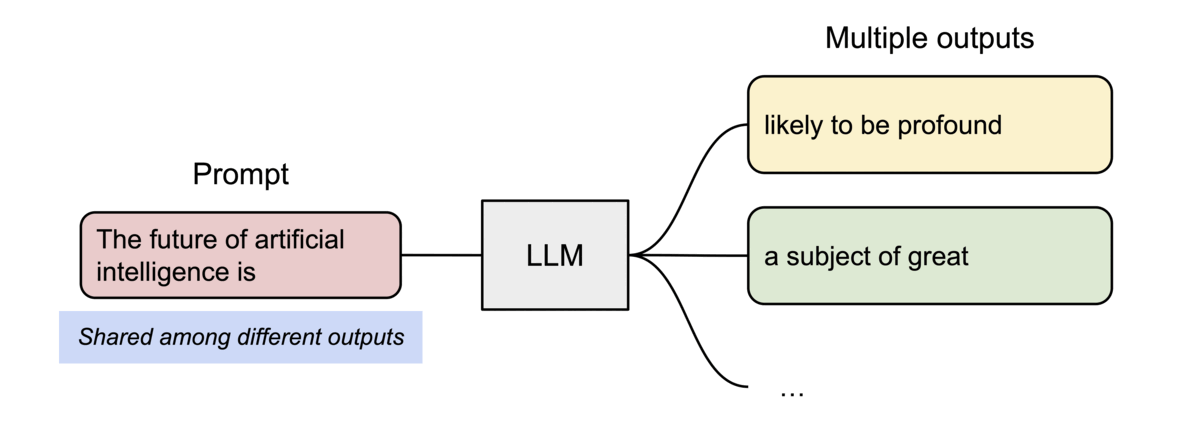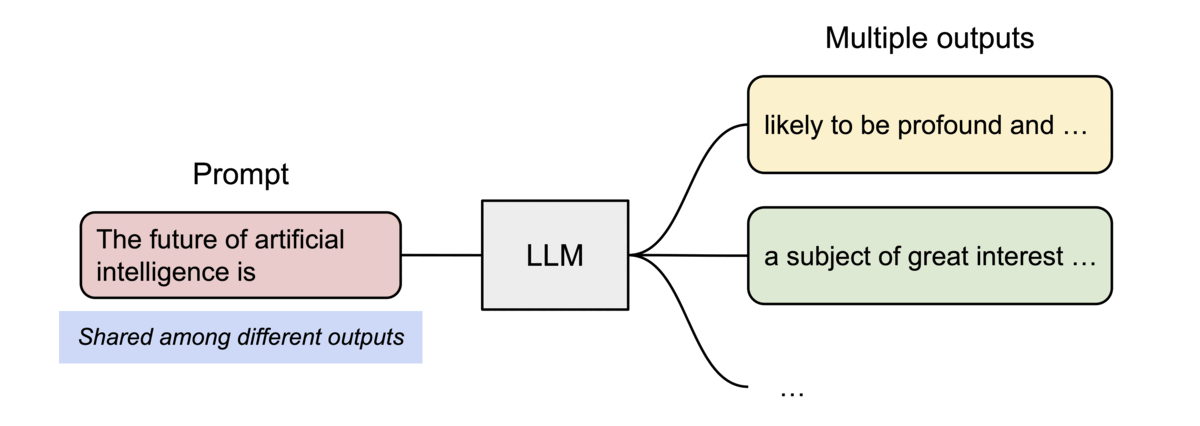
- 並列サンプリングのような複数の出力シーケンスがある場合、PagedAttention内の異なるシーケンスを、論理ブロックを同じ物理ブロックにマッピングすることでブロックを共有できる
- 安全な共有を保証するために、PagedAttentionは物理ブロックの参照カウントを追跡し、Copy-on-Writeを実装している
- PageAttentionのメモリ共有により、並列サンプリングやビームサーチなどのメモリ使用量が最大 55% 削減され、スループットが最大 2.2 倍向上する
処理の流れ

- 両方のシーケンスのプロンプトの物理KVブロックはBlock7, 1で共有される (参照カウントは2)
- Sample A1が次のトークン fathers を生成すると、Block1の参照カウントは2なのでBlock1からBlock3にコピーし、新しいトークンのKVキャッシュが追加され(Copy-on-Write)、 Block1の参照カウントを1に更新する
- Sample A2が次のトークン mothers を生成した際はBlock1の参照カウントは1なのでそのまま書き込む