
2024-11-19 機械学習勉強会
今週のTOPIC[blog] How to generate text: using different decoding methods for language generation with Transformers[slide][CV勉強会@関東 ECCV2024 読み会] オンラインマッピング x トラッキング MapTracker: Tracking with Strided Memory Fusion for Consistent Vector HD Mapping (Chen+, ECCV24)[library] pdf2htmlEX: Convert PDF to HTML without losing text or format.[blog] MPLUG-DocOwl2[論文] Classification Done Right for Vision-Language Pre-Training[論文] DocLayout-YOLO: Enhancing Document Layout Analysis through Diverse Synthetic Data and Global-to-Local Adaptive Perception[blog] Vision-Language Modelを活用した「見た目が近い商品」レコメンド改善の取り組みBetter & Faster Large Language Models via Multi-token PredictionAIによる3行まとめIntroductionMethodMemory-efficient implementationInferenceExperiments on real dataBenefits scale with model sizeFaster inferenceLearning global patterns with multi-byte predictionSearching for the optimal nTraining for multiple epochsFinetuning multi-token predictorsMulti-token prediction on natural language
今週のTOPIC
※ [論文] [blog] など何に関するTOPICなのかパッと見で分かるようにしましょう。
出典を埋め込みURLにしましょう。
@Naoto Shimakoshi
[blog] How to generate text: using different decoding methods for language generation with Transformers
- Hugging Faceのtext generation時のサンプリングについてまとまっている記事。
- 2020年の記事 (2023年最終編集) だが、ここら辺曖昧だったので改めて。
- 近年ChatGPTやLLaMAなどの登場によって、優れたデコード方法も重要な役割を果たしている。
- ここではGreedy Search、Beam Search、Samplingについて説明。
- モデル準備
- Greedy Search
- 単純にその分岐で一番高い確率のものを選んでいく
- 以下のように試せる
- 早い段階で繰り返しが発生してしまっている。二層目で、高い確率を持っている’has’を見逃してしまっている

- Beam Search
- num_beamsだけ結果を保持する。その際確率はp1 * p2 * pnと計算していく。
- num_beams=2の場合は、The, dog, hasとThe, nice, womanを保持している。
- 以下のように試せる
- この場合も繰り返しが発生してしまっているので、n-gram ペナルティというのをつけることができる。既に登場したn-gramの文章の確率を強制的に0にする
- 繰り返しはなくなったが、New Yorkのような固有名詞が登場しなくなったりするので注意が必要。
- また、を設定することで、複数のbeamの結果を見ることができる。
- しかし、生成結果に多様性が全くない。機械翻訳や要約などの長さが決まっているようなものならBeamSearchは有効だが、文章生成などでは人間にとって退屈な結果になることが知られている。

- Sampling
- それぞれの確率分布に従ってサンプリングする。
- 以下のように試せる。
- しかし、これだと支離滅裂な人間っぽくない文章になってしまう
- softmaxの温度パラメータを設定することで、各確率の山をはっきりさせることができる。
- まだマシになった


- Top-K Sampling
- 各stepでTop-Kだけ保持する。
- 以下のように試せる。
- 良い感じに生成できてるが、各ステップが平坦な分布かどうがで結果が変わってしまう。
- t = 0のpeople, big, house, catは使っても良さそうだが、t=1のdown, aは確実に使わない方が良さそう。

- Top-p (nucleus) sampling
- 累積確率が閾値を超えるまでサンプリングに含める。
- 次のように試せる
- を設定しても多様性がある

- 他にもDiverse beam searchやDoLa Decodingなどといった手法が実装されている。
- ‣
- ちなみに訓練時には、実際の教師信号を一つ手前にずらしたものを訓練したりする。
- これをteacher forcingと言ったりするが、あまりに教師信号によってしまうため、生成する時と分布が異なってしまう問題がある。そのため、徐々に実際の生成した結果を使って学習させるようなScheduled Samplingといった手法がある。
- https://github.com/rasbt/LLMs-from-scratch/blob/bb31de89993441224e9005926dedad95395bb058/ch04/01_main-chapter-code/gpt.py#L26
@Yuya Matsumura
[slide][CV勉強会@関東 ECCV2024 読み会] オンラインマッピング x トラッキング MapTracker: Tracking with Strided Memory Fusion for Consistent Vector HD Mapping (Chen+, ECCV24)
- オンラインマッピングタスクについて気になったので取り上げた。
- 自車を中心として鳥瞰図の地図を作成するタスク

- 従来のセグメンテーションベースの手法の課題

- Decorderベースで地図(ベクトル表現)を直接予測する手法が生まれてきた
- が、単フレームごとの入出力だと今現在見えている部分しか推定が難しい

- 過去情報を利用するため、地図要素をトラッキングして学習・予測したい
- 時系列で一貫した形状・IDが付与された地図要素を予測する
- ある地図要素は複数のフレームに跨って存在するよねという話。

- 提案手法の全体像は以下。
- 過去情報をうまく扱うためのメモリバッファ
- 過去情報から引っ張ってきた情報をうまいこと初期クエリや特徴抽出(cross attention)に利用


@Tomoaki Kitaoka
[library] pdf2htmlEX: Convert PDF to HTML without losing text or format.
- は、科学論文のような複雑なPDFの正確なHTML変換を実現する
- 主な機能:
- 精度の高いテキスト保持:選択、コピー、検索が可能。
- 柔軟な出力形式:単一HTML、オールインワン、ページごとHTMLを選択可能。
- リンク機能:ドキュメント内外リンクに対応。
- その他:印刷、背景画像(SVG)、Type 3フォント対応。
@Yuta Kamikawa
[blog] MPLUG-DocOwl2
- マルチページドキュメント理解手法の の紹介
- マルチページドキュメント理解なので思い処理ではあるが、OCRにかけずに画像のまま処理を行うことができる
- マルチページドキュメント理解の課題
- OCR技術の非効率性: マルチページドキュメント画像から文字単位で解析するので処理負荷高い
- ページ数が多いドキュメントのコンテキスト: マルチページにわたる情報の整合性の保持
- 高解像度画像の処理負荷: GPUメモリや推論速度の負荷
- 手法の特徴
- 効率的なビジュアルトークンの圧縮: 1ページあたり324トークンという効率性を実現
- 高解像度画像の解析: クロッピングや圧縮技術により、計算コストを削減
- マルチページ対応: ページ間の文脈を把握し、総合的な理解を可能に

- 他のマルチページドキュメント理解手法との比較
- OCRフリー、トークン数が少ない、複数ページ対応という既存手法が一部カバーしていた強み3点全てカバーした手法であり、実応用に適した手法であるという主張

- transformersで簡単にVQAなどの検証ができる(CPUでも動くっぽい)
@Shun Ito
[論文] Classification Done Right for Vision-Language Pre-Training

- NeurIPS2024 from ByteDance Research
- Vision-Language Model の Pre-Trainingを提案
- 提案手法
- 入力: (image, text) のペア
- 概要
- input: image tokens
- backbone: Vision Transformer (ViT)
- global average pooling + linear で分類ヘッドとする
- textから作ったマルチラベルを予測する
- 予測ラベルの作成
- 長さ V(subword tokenizerのvocabulary)
- あるimageと対応するtextに含まれるtoken部分が1になった K-hot ベクトル
- 損失関数: Softmax loss
- 5種類試して一番良かったのがSoftmax loss
- tokenの登場頻度によって正解ラベルの重みが異なる


- 実験

@qluto (Ryosuke Fukazawa)
[論文] DocLayout-YOLO: Enhancing Document Layout Analysis through Diverse Synthetic Data and Global-to-Local Adaptive Perception
MinerU の開発と同じ組織体 OpenDataLab による論文。
- 解決する課題:
- LLMを用いたRAGを構築するに当たっては、高品質な document content parsing が重要。その中核をなすのが Document Layout Analysis (以下DLA)
- 従来のDLAには速度と精度のトレードオフ問題が存在
- マルチモーダル手法(テキストと画像特徴を使用)は精度は高いが遅い
- ユニモーダル手法(画像特徴のみ使用)は速いが精度が低い
- 提案手法「DocLayout-YOLO」の特徴:
- 事前学習とモデル設計の両面で最適化を実施
- YOLOv10をベースに文書解析に特化した改良を加えた
- 高速性を保ちながら高精度を実現

- 主な技術的貢献:
- a) DocSynth-300Kデータセットの作成:
- Mesh-candidate BestFitアルゴリズムを開発
- 2次元のビンパッキング問題として文書合成を定式化
- 多様なレイアウトと要素を含む大規模データセットを生成
- one column, two columns, multiple columns, newspaper, paper, and magazine など
- b) Global-to-Local Controllable Receptive Module (GL-CRM):
- 文書内の様々なスケールの要素(小さい見出しから大きな表まで)に対応
- グローバルからローカルまでの階層的な特徴抽出を実現
- Ablation studies によると block level (中サイズ)のものを採用したことによる改善幅がいちばん大きかったとのこと




- 評価結果:
- 複数のベンチマークデータセットで最高性能を達成
- 処理速度85.5 FPSを実現(既存のマルチモーダル手法より14.3倍高速)
- 学術文書、教科書、市場分析、財務文書など多様な文書タイプに対応

@Yosuke Yoshida
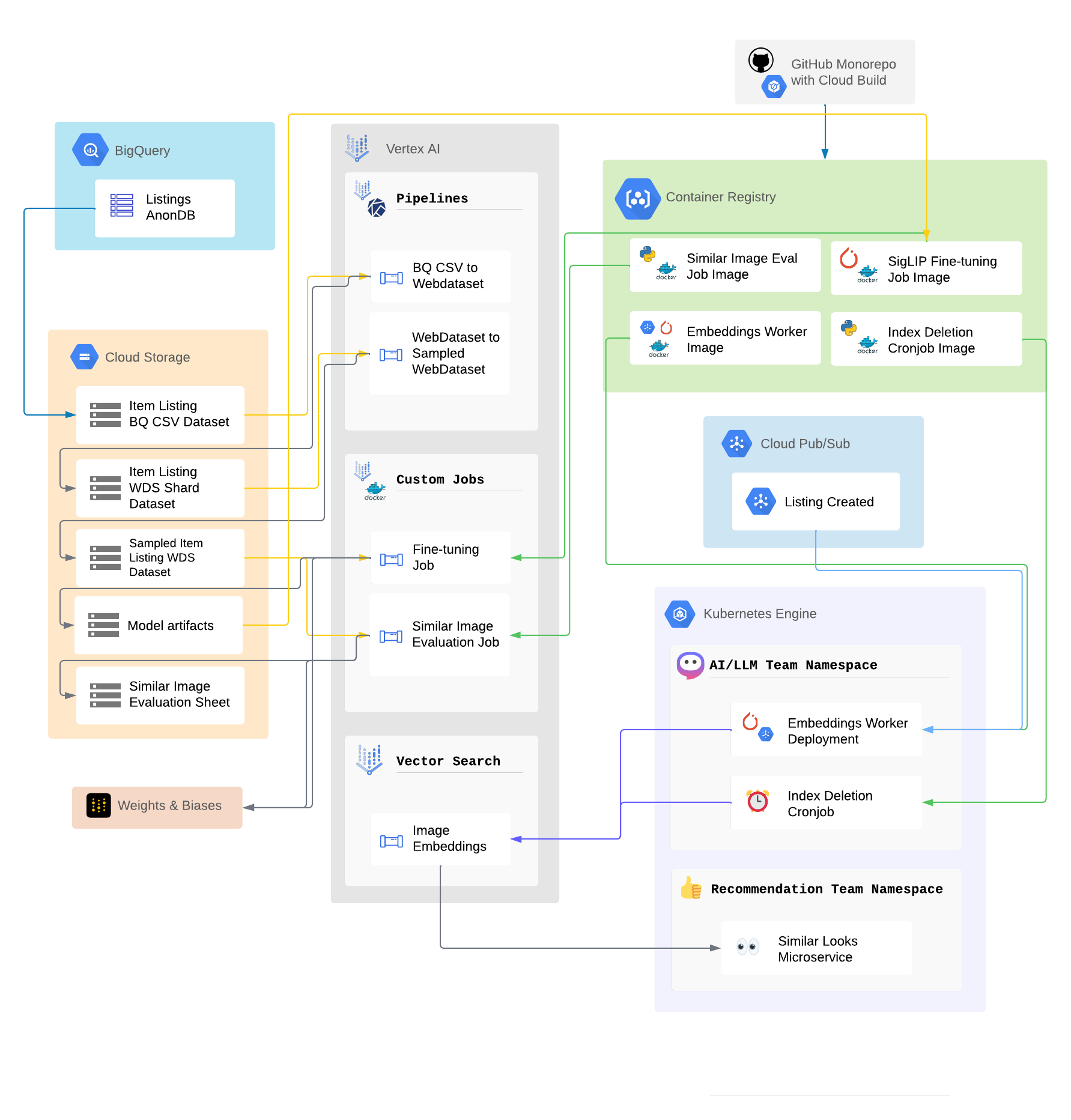
[blog] Vision-Language Modelを活用した「見た目が近い商品」レコメンド改善の取り組み
- SigLIPを、メルカリの商品データでファインチューニングし、メルカリの商品画像Embeddingの性能を大幅に改善

- オフライン評価の結果
- ベースライン
- ランダム推薦
- MobileNet (PCAで128次元に圧縮)

- ABテストの結果
- 「見た目が近い商品」のタップ率が1.5倍増加
- 商品詳細ページ経由の購入数が+14%増加
- データセット
- ランダムに抽出した約100万件のメルカリの商品データ
- お客さまが出品時に作成した商品タイトルと商品画像
- SigLIPモデルをTensorRTに変換し推論が5倍高速化
- 推論時間を数百ミリ秒から数十ミリ秒程度に削減
Better & Faster Large Language Models via Multi-token Prediction
- Fabian Gloeckle, Badr Youbi Idrissi, Baptiste Rozière, David Lopez-Paz, Gabriel Synnaeve
AIによる3行まとめ
- 言語モデルを複数トークンを同時に予測するように訓練する「マルチトークン予測」は、サンプル効率を向上させ、より高性能なモデルを構築するのに有用です。
- この手法は特にコード生成タスクで効果が顕著で、ベースラインモデルと比べて解決率が大幅に向上し、推論速度も最大3倍高速化します。
- マルチトークン予測は、より大きなモデルサイズで効果が大きく、推論時の自己推測デコーディングを活用することで効率的なトレーニングと推論を実現します。
Introduction
- next-token predictionによる大規模言語モデル(LLM)の学習の課題
- サンプル効率が悪く大量のコーパスが必要となる
- Teacher Forcing は局所的なパターンにとらわれてしまい重要な判断を見逃す傾向がある
- 本研究では、LLMを一度に複数のトークンを予測 (multi-token prediction) するよう訓練することでサンプル効率を向上させると主張
- multi-token prediction では、学習時は shared trunk と複数のheadを用いて、同時に複数のトークンを予測する
- 推論時には、通常は次のトークンを予測するheadのみを使用するが、必要に応じて他のheadを利用することで、推論時間を短縮することが可能

- 本研究の貢献
- 学習時間やメモリへの負荷を増やすことなく実現できるシンプルな multi-token prediction アーキテクチャの提案
- 大規模モデルにおける有効性の実証
- 推論時間の大幅な短縮
Method
- 通常の next-token prediction では を対象に次のトークンを予測し、以下のクロスエントロピー損失を最小化する
- multi-token prediction では一度に 個のトークンを予測し、以下のクロスエントロピー損失を最小化する
- が以下の構造を採用すると仮定
- shared trunk を用いて、 から潜在表現 を生成し、 個の独立したheadに入力し、並列に 個のトークンを予測する
- このとき、クロスエントロピー損失は以下のようになる
- このアーキテクチャを用いて 個のトークンを予測する場合以下の計算を行う
- shared transformer trunk
- transformer layer head
- shared unembedding matrix
- ここで、 であり、 はnext-token prediction headに相当
Memory-efficient implementation
- LLMで multi-token predictors を訓練する際の大きな課題は、語彙 が潜在表現の次元 よりもはるかに大きく、logitベクトルがGPUメモリ使用のボトルネックとなること
- ナイーブな実装では、全てのlogitおよびその勾配を の形状で保持するため、バッチサイズ が大幅に制限される
- 以下の方法でピーク時のGPUメモリ使用量を から に削減する
- shared trunk の順伝播の後、head の順伝播および逆伝播を順次計算し、trunkで勾配を累積
- この方法では、 に対応するlogitおよびその勾配が生成されるが、次のhead に進む前に解放される
- その結果、長期的に保持が必要なのはトランクの 次元勾配のみとなります

Inference
- 推論時は、基本的に next-token prediction head を用いて通常の次のトークン予測を用いる
- しかし、他のheadを活用することで、self-speculative decodingを用いてデコード速度を向上させることが可能
Experiments on real data
Benefits scale with model size
- 0.3 ~ 13Bパラメータの6種類のモデルを、91Bトークンのコードで訓練を行い、MBPPおよびHumanEvalで評価
- 小規模モデルではベースラインの性能を下回るが、モデルサイズを大きくするにつれて、multi-token prediction の有効性が増す
- このようにスケールに依存する点が、これまでmulti-token predictionがLLMの有望な損失関数としてあまり注目されてこなかった理由の一つと考えられる

Faster inference
- xFormersを用いて self-speculative decoding を実装し、コードおよび自然言語のテストデータセットから取得したプロンプトを用いて推論速度を測定
- 評価対象は、パラメータ数が7Bある4-token predictionモデル
- 結果
- コードデータは、平均して3つの生成候補のうち2.5個のトークンが採用され、推論速度が3.0倍に向上
- テキストデータは、推論速度が2.7倍に向上
- 8-byte predictionモデルでは推論速度は6.4倍に向上


Learning global patterns with multi-byte prediction
- next-token predictionタスクが局所的なパターンにとらわれることを示すために、極端なケースとしてバイトレベルのトークン化を用いて実験
- 8-byte predictionモデルは、next-byte predictionと比較して、MBPP pass@1で67%多くの問題を解決し、HumanEvalのpass@1では20%多くの問題を解決した
Searching for the optimal n
- 200Bトークンのコードで訓練された7Bモデルを用いて で実験
- のモデルが、HumanEvalおよびMBPPにおいて、全ての指標で他のモデルを一貫して上回る
- APPS/Introでは が最も優れた結果となり、最適なウィンドウサイズが入力データの分布に依存する可能性が高いことを示す
- バイトレベルモデルに関しては、これらのベンチマーク全体で最適なウィンドウサイズがより一貫しており(8バイト)、その安定性が確認された

Training for multiple epochs
- マルチトークン学習は、同じデータを複数エポックでトレーニングした場合でも、next-token predictionにおいて、改善幅は減少するものの、MBPPのpass@1で+2.4%、HumanEvalのpass@100で+3.2%の向上が見られ、その他のパフォーマンスも同程度を維持
Finetuning multi-token predictors
- CodeContestsデータセットのファインチューニング性能の比較
- 4-token predictionモデルのファインチューニングが、next-token prediction ベースラインモデルを上回る性能を示した
- 特に、4-token prediction モデルをベースにしたnext-token predictionファインチューニングが、最良の方法となった

Multi-token prediction on natural language
要約
- 200Bおよび500Bのデータセットサイズで、 の multi-token prediction モデルがnext-token predictionモデルを上回る性能を示した
- ただし、データセットが大きくなるにつれて性能差は縮小した

数学
- GSM8Kベンチマークを使用し、8-shotで事前学習モデルを評価
- 200Bトークンでトレーニングした場合、 モデルはnext-token predictionモデルを明確に上回った
- しかし、500Bトークンでトレーニングすると、逆にnext-token predictionモデルが優位となり、 モデルは一貫して低い性能を示した
