
2025-02-14 機械学習勉強会
今週のTOPIC[blog] Open-source DeepResearch – Freeing our search agents[model]ModernBERT-Ja-130MVapi: Voice AI for developers[blog] Packing with Flash Attention で効率的に LLM のファインチューニングをするs1: Simple test-time scaling | Papers With Code[blog] Revolutionizing software testing: Introducing LLM-powered bug catchersメインTOPICDeepSeek-R1: Incentivizing Reasoning Capability in LLMs via
Reinforcement Learningサマリー1. IntroductionContributionSummary of Evaluation Results2. Approarch2.2. DeepSeek-R1-Zero: Reinforcement Learning on the Base Model2.3. DeepSeek-R1: Reinforcement Learning with Cold Start2.4. Distillation: Empower Small Models with Reasoning Capability3. ExperimentDeepSeek-R1 実験結果蒸留モデル 実験結果4. Discussion4.1. Distillation v.s. Reinforcement Learning4.2. Unsuccessful Attempts5. Conclusion, Limitations, and Future Work
今週のTOPIC
※ [論文] [blog] など何に関するTOPICなのかパッと見で分かるようにしましょう。
出典を埋め込みURLにしましょう。
@Naoto Shimakoshi
[blog] Open-source DeepResearch – Freeing our search agents
- OpenAIのDeep Researchの基盤となるAgent Frameworkを(発表から24時間以内に)明らかにしようとする試み。
- Agentを使用した場合に、普通に利用するよりパフォーマンスが上がるというのは既知の事実。(図の場合は単純にsmolagentsライブラリを使っただけ)

- 今回は、GAIAデータセットを用いてDeep ResearchのAgentシステムの再現を目指す
- GAIAデータセット
- 質問が難しい
- 制約された形式、マルチモーダルな情報収集、問題解決の順序を正しい順序で並べる、など高度な計画能力と厳密な実行能力が必要になる。
- 既存のAI Agentから改善するための最初のステップ「CodeAgent」の利用
- Agentのアクションをコードで表現できるようにすること。
- コードアクションはJSONよりも30%少ないステップ数で済む。
- 状態のメモリ管理なども簡単にできる

- Agentに適切なToolsを提供する。(まずはLightなものから)
- Webbrowser
- 完全にはOpenAIのOperatorなどを利用する必要があるが、簡単なテキストベースのブラウザから始めた。
- Text Inspector
- 24 時間以上の再現作業では、GAIA 上のエージェントのパフォーマンスが着実に向上していることがすでに確認されている。
- OSSでは今まで、Magentic Oneで46%だったのが55.15%まで向上
- この向上はアクションをコードにしたことによる貢献が大きい。JSONにすると平均33%低下する。
@Yuya Matsumura
[model]ModernBERT-Ja-130M
- 日本語コーパスで学習されたModernBERTをSB Intuitionsさんが公開
- モデルサイズが小さく、sequence length は 8,192
- ModernBERTが出た時点で待望だった日本語対応モデル!試してみるしかない。
@Tomoaki Kitaoka
Vapi: Voice AI for developers
- モデル概要

- モデルオーケストレーション
- Endpointing: ユーザーが話し終わったタイミングの感知と即座の返答。
- Interruptions (Barge-in): ユーザーの中断希望の識別と会話の途切れなし。
- Background Noise Filtering: 背景ノイズのリアルタイム除去と会話のクリア化。
- Background Voice Filtering: 主なスピーカーの声の抽出と背景音声の排除。
- Backchanneling: 会話の流れの維持と適切なタイミングでの確認の言葉挿入。
- Emotion Detection: ユーザーの感情の検出と応じた反応。
- Filler Injection: 自然な会話風のフレーズのリアルタイム追加。
- poly.aiのCTOのpodcastでもSpeech-to-text, LLM, text-to-speachすれば理論上はできるんだけどプロダクションレベルのクオリティを作るにはまだ大きな壁があると言っていた
- ‣
@Shun Ito
[blog] Packing with Flash Attention で効率的に LLM のファインチューニングをする
- padding vs. packing

- LLM訓練で、ミニバッチ内のトークン列の長さを揃えるための手法は、paddingが一般的だが計算リソースの使い方が効率的でない
- 代替案としてメモリをより効率的に使えるpackingが使われる
- 直列に繋げる&境界を渡して、exampleごとにAttentionを計算する
- Flash Attention
- GPUのHBMメモリへのIOアクセスを減らして高速化する手法
- 動画によるstep by stepの説明

- Packing with Flash Attention
- Hugging FaceのtransformersにはPackingしたデータをFlash Attentionに渡すためのDataCollatorWithFlatteningがある
- 前から順番にpackingしていくため結局バッチごとに不均衡になってしまう
- 複数GPUで並列学習させる際に早く終わるものと遅く終わるものが出てしまう
- ShardedMaxTokensCollator
- LMSYS - Chatbot Arena Human Preference Predictions コンペでのtascjらの実装
- DataLoaderから複数イテレーション分のデータをまとめて取り出し、ソートしてからある程度同じ長さになるようにpackingする
- 比較的ナイーブな手法だが十分均衡なバッチが作れる


- 最新のtransformers(v4.48.3, Feb 2, 2025)でもGemma2Modelのforwardに関連情報を渡せるようになっている
- MultiPackSampler
- https://github.com/imoneoi/multipack_sampler/tree/master
- Samplerの方でpackingする方法
- 全てのトークンの長さを事前にSamplerに渡す。全体を見れるためより大域的な最適になりそう
@qluto (Ryosuke Fukazawa)
s1: Simple test-time scaling | Papers With Code
Niklas Muennighoff * 1 3 4 Zitong Yang * 1 Weijia Shi * 2 Xiang Lisa Li * 1 Li Fei-Fei 1 Hannaneh Hajishirzi 2 3
Luke Zettlemoyer 2 Percy Liang 1 Emmanuel Candès 1 Tatsunori Hashimoto 1
Equal contribution. ZY and NM started the project. WS, NM and ZY collected the prompts, XL, ZY and NM, built the data pipeline, LZ and WS proposed using a 1K subset and ZY and NM built budget forcing. 1 Stanford University. 2 University of Washington, Seattle. 3 Allen Institute for AI. 4 Contextual AI.
- これはなに?
- OpenAI o1モデルが推論時の計算資源を増やすことによって性能を向上させたということを再現するような試みの一つ。とてもシンプルだと謳ったもの
- 手法
- まず、難易度、多様性、品質という3つの基準に基づいて検証した1,000問の問題とその理由付けの過程をペアにした小規模データセット「s1K」を厳選して作成する
- 次に、バジェットフォーシングと呼ばれる手法を開発し、モデルの思考プロセスを強制的に終了させたり、終了しようとする際に複数回「Wait」を付加することで思考時間を延長したりすることで、テスト時の計算量を制御する

- 結果
- Qwen2.5-32B-Instruct言語モデルをs1Kで教師ありファインチューニングし、さらにバジェットフォーシングを適用した結果、s1-32Bは競技数学問題(MATHやAIME24)においてo1-previewを最大27%上回る性能を示した
- さらに、バジェットフォーシングによるスケーリングを継続することで、テスト時の介入なしの場合の性能(AIME24において50%)を57%まで外挿することが可能となった
- DeepSeek R1 には勝っていないが、この研究のモチベーションはfine-tuningに少数のデータだけを用いることでtest-time scalingの性能をよく引き出せるか?という問いに向かったものなので、著者的には土俵違いではある


@Yosuke Yoshida
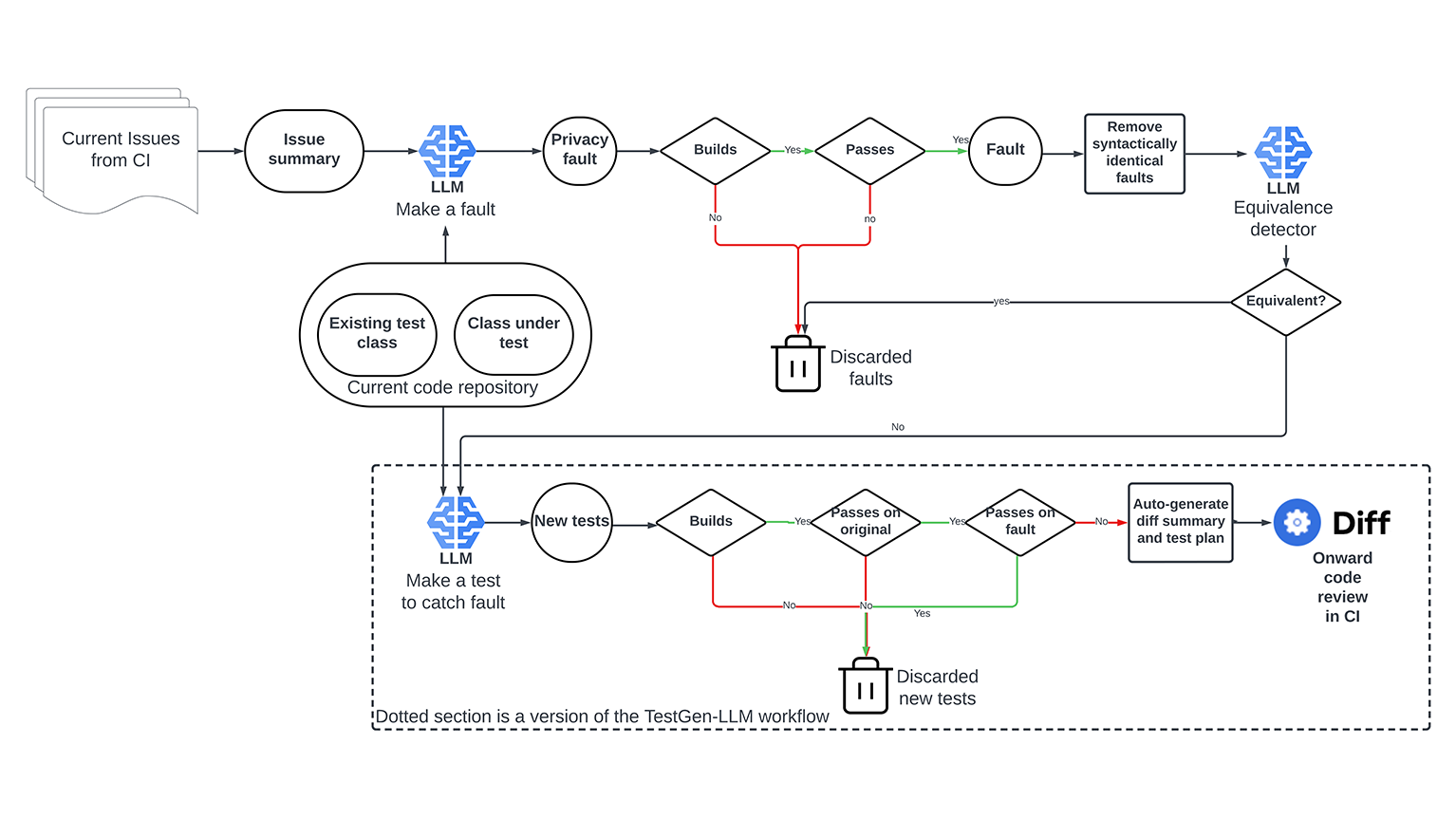
[blog] Revolutionizing software testing: Introducing LLM-powered bug catchers
- Meta社で運用されているACH (Automated Compliance Hardener) に関する記事
- ACHでは特定の懸念領域(ここではプライバシーに関する問題)に関わるバグとそのバグを検出するテストケースをLLMを用いて自動生成することで将来的なシステムへの混入を防ぐ
- エンジニアはACHの生成したテストの73%を受け入れ、そのうち36%をプライバシーに関連すると評価
メインTOPIC
DeepSeek-R1: Incentivizing Reasoning Capability in LLMs via Reinforcement Learning
DeepSeek-AI(具体的な著者の明記なし)
- DeepSeek-AI によるテクニカルレポート
おすすめ解説ブログ
サマリー
- DeepSeek-AI による第一世代reasoningモデルである DeepSeek-R1-Zero および DeepSeek-R1 の提案
- DeepSeek-R1-Zero は事前に教師あり学習(SFT)をせずに大規模な強化学習(RL)のみで学習したモデルであるが、高度な reasoning 能力を有する。
- 一方で、DeepSeek-R1-Zero には、出力の読みにくさの問題や複数の言語が入り混じってしまうという問題が存在した。
- DeepSeeek-R1 はこれらの問題を解決しさらなる reasoning 能力を獲得するため、RLの前に多段階学習とコールドスタートデータを組み込んだ。
- 結果として、DeepSeek-R1 はOpenAI o1 に匹敵する性能を達成。

- DeepSeek-R1-Zero および DeepSeek-R1、さらに DeepSeek-R1 を用いて Qwen と Llama をベースに蒸留を行った比較的小型な6つのモデル(1.5B, 7B, 8B, 14B, 32B, 70B)をオープンソース化した。
1. Introduction
- 近年の大規模言語モデル(LLM)は急速に進化しており、人工汎用知能(AGI)に近づくための重要なステップとして注目されている。
- これまでのLLMの発展は、主に大規模な事前学習と事前学習と比較すると小さな計算リソースのみで済む事後学習(post-training)によって進められてきている。LLMは事後学習により、reasoning タスクでの性能向上や社会的価値との整合、ユーザーの好みへの適合を行っている。
- reasoning 性能の向上という点においては、 OpenAI の o1シリーズモデルがチェーン・オブ・ソート(Chain-of-Thought, CoT)の推論過程を長くすることで推論時間のスケーリング(inference-time scaling)という概念を最初に導入した。
- 推論時間のスケーリングを効果的に行う方法はまだ研究の余地が大いにある領域であり、本研究の趣旨は、教師データなしで(教師あり学習なしで)純粋な強化学習のみでLLMの reasoning 性能を向上する可能性を見出すことである。
- 具体的には、DeepSeek-V3-Baseというベースモデルに対して、教師あり学習を行わずにGRPOを用いた強化学習を適用することで、reasoning 性能の向上を図る。
- その過程で得られた DeepSeek-R1-Zero は、AIME 2024(数学のデータセット)において、pass@1が15.6%から71.0%に向上し、 多数決(majority voting)ではOpenAI-o1 に匹敵する86.7%まで向上した。
- 一方で、DeepSeek-R1-Zeroには出力の読みづらさや、複数言語が混在するなどの問題が存在した。
- これらの問題を解決し、かつさらに reasoning 性能を向上するために、少量のコールドスタートデータを用いた、教師あり学習も組み合わせたマルチステージの学習パイプラインを導入した DeepSeek-R1 を提案。
- さらに、DeepSeek-R1-Zero および DeepSeek-R1 を用いて Qwen と Llama をベースに蒸留を行った比較的小型な6つのモデル(1.5B, 7B, 8B, 14B, 32B, 70B)をオープンソース化した。14Bモデルでは、オープンソースモデルのSoTaである QwQ-32B-Preview の性能を上回り、32Bと70Bは reasonig ベンチマークでSoTaを叩き出した。
Contribution
1. 事後学習における大規模な強化学習の活用
- 教師あり学習を一切行わず、純粋な強化学習のみで高い reasoning 能力を得ることを示した。
- DeepSeek-R1 で利用した、強化学習と教師あり学習を組み合わせたマルチステージ学習パイプラインの提案
2. 蒸留による小型モデルへの reasoning 能力の伝達
- DeepSeek-R1で得られた高度なreasoning 能力をより軽量な小型のモデルに蒸留できることを示した。それは小型モデルベースに強化学習を行うよりも高い性能を示した。
- 蒸留により得られた1.5B、7B、8B、14B、32B、70B各モデルのチェックポイントをオープンソースとして提供した。
Summary of Evaluation Results
Reasoning Task
- 数学:DeepSeek-R1 は AIME2024 にて Pass@1 が 79.8% であり、OpenAI o1 を僅かに上回る。MATH-500 ではo1と同等の97.3%を達成。
- コーディング:DeepSeek-R1 は Codeforces においてコンペに参加する人間の96.3%を上回る 2,029というレーティング。
Knowledge
- MMLU(Massive Multitask Language Understanding)
- DeepSeek-R1のMMLUスコアは90.8%(OpenAI-o1-1217は91.8%)。OpenAI-o1-1217には若干及ばないものの、他の閉鎖系モデルより優れた性能を示した。
- MMLU-Pro(より困難な問題を含むMMLUの拡張版)
- スコアは84.0%(DeepSeek-V3よりも向上)。
- GPQA Diamond(大学院レベルの知識を問うベンチマーク)
- Pass@1スコア71.5%であり、OpenAI-o1-1217(75.7%)にはわずかに及ばないものの、他の多くのモデルを上回る。
- SimpleQA(ファクトチェック型の質問応答)
- DeepSeek-R1はDeepSeek-V3よりも優れたスコアを記録し、事実に基づくクエリへの対応能力が向上。
2. Approarch
大きく以下の三部構成
- DeepSeek-R1-Zero: ベースモデルに対して教師あり学習(SFT)を用いたファインチューニングを一切行わず、強化学習のみを適用したモデル
- DeepSeek-R1: 数千のCoT教師データでSFTしたものに対して強化学習を適用したモデル
- DeepSeek-R1から小さなモデルへの reasoning 能力の蒸留
2.2. DeepSeek-R1-Zero: Reinforcement Learning on the Base Model
- 先行研究においても強化学習により reasoning 性能が向上することは示していたが、それらは収集コストの高い教師ありデータに大きく依存していた。
- 教師ありデータを一切使わずに強化学習のみによる reasoning 性能の向上がモチベーション
- DeepSeek-V3 については以前に勉強会でも簡単に取り上げられている。
Group Relative Policy Optimization(GRPO)
- 強化学習のコストを抑えるため、Group Relative Policy Optimization(GRPO)という手法を適用
- 一般的な強化学習手法(例えばPPO: Proximal Policy Optimization)では、Policyモデルとは別にCritic(Value)モデル(状態価値関数を予測するモデル、)を使用するが、GRPOではCriticモデルを使用せず、一群のサンプルに対する相対的なスコア をもとに学習を進める。
- 状態価値:ある状態における将来的な報酬総和の期待値。こいつとの比較によって、どんな行動をとっても良いケース・悪いケースにおける勾配の爆発を防ぐ

- 手順:
- 各質問 q に対し、旧ポリシー から複数の出力 を生成(このセットを「グループ」とする)。
- 各出力 に対する報酬 を計算。
- 報酬の平均値を基準にして各出力の「優位性(advantage)」を計算
- ポリシー更新の目的関数 を最大化
- クリッピングを適用したPPOに似た形の更新(元の方策との比率を計算して、指定した範囲を超えないように制約をかける)
- KLダイバージェンスによる正則化項により、モデルの過度な最適化を防ぐ(元々LLMが持っていた汎用的な知識や能力の喪失を防ぐ)



- 良さ
- Critic モデルが不要なので計算コストが大幅に削減
- グループ内の相対評価により報酬のスケーリングが不要
- PPOと同様のクリッピングにより学習の安定性向上
Reward Modeling(報酬モデル)
2週類の報酬モデルを利用
- 正確性報酬(Accuracy Rewards)
- 出力の「正しさ」を評価し、モデルの最適化方向を決定する。
- 例
- 数学の問題では、モデルが出力する最終的な答えを特定のフォーマットに従わせ、ルールベースで自動採点
- プログラミングの問題(LeetCodeなど)では、コードをコンパイルし、テストケースの正答率を報酬として計算
- フォーマット報酬(Format Rewards)
- モデルが明確な「思考過程」と「最終的な答え」を分けて出力することを促す。
- 例
- モデルに対し、「思考過程(CoT)」を <think> タグで囲み、最終的な答えを <answer> タグで囲むように指示。この形式を守ることで、出力が整理され、人間が解釈しやすくなる。
Training Template
- DeepSeek-R1-Zero を学習するにあたり、ベースモデルが指定された命令に従うように導く簡単なテンプレートの設計

- ざっくり言うと、最初に最初に思考過程を生成し、次に最終的な答えを生成させる。それぞれの形式も以下で指定
- 内に詳細な推論を記述。
- には簡潔な最終的な答えのみを記載。
- これにより、モデルが明確なCoT(Chain-of-Thought)を実行するよう促し、出力が読みやすく、人間が解釈しやすい形になることを期待。
Performance
- AIME 2024ベンチマークでのpass@1スコアが15.6% → 71.0%に向上。
- マジョリティ投票(多数決, cons@64)を適用すると、スコアが86.7%に到達し、OpenAI-o1-0912の性能を上回る


Self-evolution Process
- 学習の進行とともに、「思考時間」が自然に長くなる(長いCoTを生成する)。
- リフレクションであったり、代替アプローチの検討なども徐々に行うようになっていく。
- 以上が、強化学習だけで実現できるのがすごい!

Aha Moment
- 学習中、DeepSeek-R1-Zeroが突然「問題解決のアプローチを見直す」ことを学習した場面が観察された。
- 解き方を教えるのではなく、適切な報酬を与えるだけでモデルが自律的に進化いく瞬間とも捉えられ、強化学習の可能性を感じる。
- 以下のように、数学問題を解いている最中に、途中で「あれ?この計算はおかしいかもしれない」と考え直す様子がログから確認された。

2.3. DeepSeek-R1: Reinforcement Learning with Cold Start
さらにDeepSeekを進化させるために、教師ありファインチューニングもしてみるべく、以下の4段階のマルチステージ学習が考案された。
1. Cold Start
- DeepSeek-R1-Zeroでは、教師あり微調整(SFT)なしで純粋な強化学習(RL)のみを適用したが、以下のような問題が発生
- 出力の可読性が低い
- DeepSeek-R1-Zeroの生成テキストは「読みづらく」、「言語が混在」する傾向があった。
- Markdown形式の使用や、ユーザーにとって明確な答えの提示が不足していた。
- 学習の収束が遅い
- RLのみで学習を進める場合、適切な推論パターンを見つけるまでに非常に多くの試行が必要になる。
- これらの問題を解決するため、DeepSeek-R1では少量のコールドスタートデータを用いることで、初期状態での学習の不安定さを軽減し、可読性の向上を図る。
- 以下の方法を組み合わせて、「数千件の高品質なChain-of-Thought(CoT)」データを収集
- Few-shotプロンプティング
- 既存のLLMに長いCoTの例を与え、それを参考に回答を生成させる。
- 自己生成データ
- DeepSeek-R1-Zeroを用いて推論しやすい形式でCoTを生成させ、その中から適切なものを抽出。
- 手動アノテーション
- 一部のデータを人間が修正し、可読性の高い出力を作成。
- コールドスタートデータによる恩恵
- 読みやすいフォーマットの実現
- |special_token|<reasoning_process>|special_token|<summary> の形式を採用。
- にCoT(推論過程)、 に簡潔なまとめを記述。
- 今後の可能性
- 人間が頑張って作ったデータを食わせたら性能が上がった。もっと伸ばせるかも。
2, Reasoning-oriented Reinforcement Learning
- DeepSeek-R1のコールドスタートデータで微調整(SFT)した後、DeepSeek-R1-Zeroと同様の大規模強化学習(RL) を適用し、モデルの推論能力を向上
- 強化学習の主な変更点
- コールドスタートデータセットで学習済みのモデルを初期ポリシーとする
- DeepSeek-R1-Zeroでは純粋なRLのみで学習を進めたが、DeepSeek-R1では「コールドスタートデータで初期調整」されたモデルをRLの出発点とする。これにより、学習の収束速度が向上。
- 言語混在の問題への対応
- RLプロセスでは、特に異なる言語(英語・中国語)の混在が発生しやすいため、「言語整合性報酬(Language Consistency Reward)」を導入。
- 具体的には、出力中のターゲット言語(英語・中国語)の割合を計測し、一定の閾値以上で報酬を与える。
3 Rejection Sampling and Supervised Fine-Tuning
- 強化学習が収束した後に、さらなる性能向上・広いドメインの知識を得るために新たなデータを生成し、それを用いてさらにモデルを学習させる。
- Reasoningデータの生成
- RLによる学習後のモデルを使い、「リジェクションサンプリング(Rejection Sampling)」により高品質な推論データを収集。
- 各質問に対して複数の回答を生成し、最も優れた回答を保持するイメージ
- 数学などの問題に限らず、広いドメインのデータを生成。
- DeepSeek-V3使ってモデルの出力を評価。
- フォーマットが適切で、正確な回答のみを選択。
- 60万件のサンプルを収集
2. Non-Reasoningデータの追加
- DeepSeek-V3の学習データセットの中から、一般的な会話・文章生成タスクのデータ(20万件)も追加し、モデルの汎用性を向上。
- ライティング(Writing)、事実確認(Fact QA)、自己認識(Self-cognition)、翻訳(Translation) などのタスク。
3. 最終的なSFT
- これらのデータ(計80万サンプル)を用いて、DeepSeek-V3-Baseをさらに微調整。
- 2エポック分のSFTを適用し、より一貫した性能を持つモデルに仕上げる。
4 Reinforcement Learning for all Scenarios
- 最後の段階として、モデルの「有用性(helpfulness)」と「無害性(harmlessness)」を強化するためのRLを適用
2.4. Distillation: Empower Small Models with Reasoning Capability
- DeepSeek-R1は大規模なモデル(DeepSeek-V3-Baseをベースに訓練)であり、性能は非常に高いものの、推論速度や計算コストの観点から、すべての用途に適しているわけではない。
- 小型モデル(1.5B~70Bパラメータ)の計算効率を向上させながら、高度な推論能力を保持するために蒸留を行う。
- 蒸留後に強化学習することによるさらなる性能向上はスコープ外
- 学習プロセスの最適化:
- RLによる学習は計算コストが非常に高いが、一度学習したモデルを小型モデルに蒸留すれば、同様の推論能力をより低コストで再現できる。
3. Experiment
ベンチマーク
- 知識・一般論
- MMLU (Hendrycks et al., 2020)
- 一般知識を測る有名なベンチマーク(歴史、数学、物理、社会科学など57分野)。
- 評価指標: Pass@1(正答率)
- MMLU-Redux (Gema et al., 2024)
- MMLUの改良版で、質問フォーマットや難易度を調整したもの。
- 評価指標: EM(Exact Match、完全一致率)
- MMLU-Pro (Wang et al., 2024)
- MMLUの難問を集めたプロ版。
- 評価指標: EM(Exact Match)
- DROP(Discrete Reasoning Over Paragraphs)
- 段落内の数値・論理推論を評価するタスク。
- 評価指標: 3-shot F1スコア
- IFEval (Zhou et al., 2023)
- 指示に従った出力の適切性を測るタスク。
- 評価指標: Prompt Strict(厳密な評価基準)。
- GPQA Diamond (Rein et al.,2023)
- Google-Proof Question Answering(難解な事実質問)。
- 評価指標: Pass@1(正答率)。
- SimpleQA (OpenAI, 2024c)
- 一般的な事実質問応答(Google検索が得意なタスク)。
- 評価指標: 正答率(Correct)。
- FRAMES (Krishna et al., 2024)
- 長文読解を評価するタスク。
- 評価指標: Accuracy(正答率)。
- コーディング系
- SWE-Bench Verified (OpenAI,2024d)
- ソフトウェアエンジニアリングに関するバグ修正タスク。
- 評価指標: Resolved(解決したバグの割合)。
- Aider
- 多言語プログラミングスキルを評価。
- 評価指標: Accuracy(正答率)。
- LiveCodeBench (Jain et al., 2024) (2024-08 – 2025-01)
- コーディング問題の自動採点を行うベンチマーク。
- 評価指標: Pass@1(CoTを利用)。
- Codeforces 2
- 競技プログラミングの問題を解く能力を評価。
- 評価指標: パーセンタイル(Percentile)、Eloレーティング。
- 数学系
- Chinese National High School Mathematics Olympiad (CNMO 2024)
- American Invitational Mathematics Examination 2024 (AIME 2024) (MAA, 2024).
- MATH-500
- 中国語ベンチ
- CLUEWSC
- 中国語のWSC(Winograd Schema Challenge)。
- 評価指標: EM(Exact Match)。
- C-Eval (Huang et al., 2023)
- 中国語の大規模評価データセット。
- 評価指標: EM(Exact Match)。
- C-SimpleQA
- 中国語の事実確認タスク。
- 評価指標: 正答率(Correct)。
- CMMLU (Li et al.,2023)
- その他、LLMs as judge による評価( GPT-4-Turbo-1106でも利用されたもの)
- AlpacaEval 2.0 (Dubois et al., 2024)
- Arena-Hard (Liet al., 2024)
- 注意
- 出力長による影響・バイアスをなくすため、最終的な答えの部分のみを利用して評価を行う。
- 蒸留モデルは別途以下で評価
- AIME 2024
- MATH-500
- GPQA Diamond
- Codeforces
- LiveCodeBench
評価プロンプト
- 一般ベンチマーク(MMLU、DROP、GPQAなど)
- Simple-evalsフレームワークを使用。
- MMLU-ReduxではZeroEvalフォーマットを採用。
- コーディング・数学タスク
- Codeforcesでは、Div.2の10回のコンテストを利用し、Eloレーティングを計算。
- LiveCodeBenchではCoT形式での回答を使用。
- 出力設定
- 最大出力長: 32,768トークン。
ベースライン
- Claude-3.5-Sonnet-1022
- GPT-4o-0513
- DeepSeek-V3
- OpenAI-o1-mini
- OpenAI-o1-1217
- 中国ではo1使えないから公開のベンチを利用
- QwQ-32B-Preview(Qwen 32Bの事前学習済みモデル)→蒸留モデルの比較
実験設定
- 最大出力長: 32,768トークン。
- デコード戦略: Pass@k(温度0.6、top-p 0.95で複数回答を生成)。
- kはタスクのデータセットに応じて[4, 64]
DeepSeek-R1 実験結果

知識・一般推論タスク
- MMLU: 90.8%(OpenAI-o1-1217: 91.8%) → ほぼ同等の性能。
- GPQA Diamond: 71.5%(OpenAI-o1-1217: 75.7%) → わずかに劣るが競争力あり。
- FRAMES: 82.5%(長文生成で高評価)。
- SimpleQA: 30.1% (DeepSeek V3: 24.9) → o1 には劣る。元のDeepSeel V3は上回る(gpt-4o と o1 の関係と同じ)
- C-SimpleQA: 63.7% (DeepSeek V3: 68.0)→ 中国語データセットでは性能悪化
- safety RL を外せば 70%以上の精度(何を弾いてるんだろう、、)
コーディング・プログラミングタスク
- LiveCodeBench: 65.9%(OpenAI-o1-1217: 63.4%) → 競争力のある性能。
- Codeforces: Elo 2029(OpenAI-o1-1217: 2061) → 96.3%の人間参加者を超える。
数学タスク
- AIME 2024: 79.8%(OpenAI-o1-1217: 79.2%) → 若干上回る。
- MATH-500: 97.3%(OpenAI-o1-1217: 96.4%) → OpenAIモデルとほぼ同等。
蒸留モデル 実験結果

- 蒸留モデル(DeepSeek-R1-Distill-Qwen-32B)がQwQ-32B-Previewを大幅に上回る。
- 特に数学・推論タスクで蒸留の効果が大きい。
4. Discussion
4.1. Distillation v.s. Reinforcement Learning
- 強化学習(RL)のみで小型モデルの推論能力を向上させることができるか、または蒸留の方が有効なのかを検証
- 同じベースモデル(Qwen-32B)を2つの方法で学習して比較実験
- DeepSeek-R1-Zero-Qwen-32B: 強化学習
- DeepSeek-R1-Distill-Qwen-32B:蒸留

- 強化学習したものはPreviewと同等の性能だが、蒸留したものは大きく性能向上
- 小型モデルへの強化学習よりも、大型モデルを利用した蒸留の方が有効。
- RLを小型モデルに適用するためには、もっと膨大な計算が必要なのかもしれない。
4.2. Unsuccessful Attempts
Process Reward Model (PRM)
- PRMとは、モデルが推論プロセスの途中で正しいステップを踏んでいるかどうかを評価する方法。つまり、推論の「プロセス自体」に報酬を与えることで、より良い推論パターンを誘導しようとする手法。
- うまくいかなかった理由
- 推論の「正しい途中経過」を定義するのが難しい
- 一般的な推論問題では、どのステップが正しいのかを明確に定義することが困難。
- 数学問題では答えの正誤は簡単に判断できるが、途中経過の妥当性を評価するのが難しい。
- 自動アノテーションの限界
- モデルベースで途中経過を評価しようとすると、誤った報酬が与えられ、「報酬ハッキング(Reward Hacking)」が発生。
- 人手でアノテーションするのは非現実的。
- 計算コストの増大
- プロセスベースの報酬モデルを学習するには、大量のデータと計算資源が必要であり、スケーリングが困難。
Monte Carlo Tree Search(MCTS、モンテカルロ木探索)
- MCTSとは、AlphaGoやAlphaZeroなどで使われた「探索と評価を組み合わせた手法」。
- モデルの出力を部分ごとに分割し、探索を行いながら解を最適化する。
- うまくいかなかった理由
- 探索空間が広すぎる
- チェスや囲碁と異なり、自然言語の「トークン生成」は探索空間が爆発的に大きくなる。
- すべての可能な推論ステップを探索するのは現実的ではなかった。
- 局所最適解に陥る
- 限られた範囲での探索では、最適な解を見つけることが難しい。
- 結果的に、通常のRLよりも低い性能しか得られなかった。
- 価値モデルの学習が難しい
- AlphaGoでは「局面の良し悪し」を評価する価値ネットワークを学習できたが、言語生成では「途中の状態の良し悪し」を適切に評価するのが困難。
- 価値モデルの精度が低いため、MCTSの探索精度も向上しなかった。
5. Conclusion, Limitations, and Future Work
一般的な能力の不足
- DeepSeek-R1は、DeepSeek-V3に比べて汎用的なタスク(関数呼び出し、複雑なマルチターン対話、JSON出力など)が苦手。
- CoT をどれほど活かせるかの検証が必要。
言語混在の問題
- DeepSeek-R1は、英語と中国語の両方に対応しているが、他言語の処理は最適化されていない。例えば、フランス語、ドイツ語、日本語などの言語で質問すると、英語や中国語の混在した回答が生成されることがある。
プロンプト感度
- DeepSeek-R1は、プロンプトの書き方に敏感であり、Few-shotプロンプトを与えると性能が低下するケースがある。
ソフトウェアエンジニアリングタスクでの課題
- DeepSeek-R1は、数学・推論タスクでは強力なパフォーマンスを発揮するが、ソフトウェアエンジニアリング関連のタスクでは大きな向上が見られなかった。
- リジェクトサンプリングを頑張るか。