
2025-02-25 機械学習勉強会
今週のTOPIC[blog] <think>...</think> QwQ-Max-PreviewIntroducing Mercury, the first commercial-scale diffusion large language model[blog] From RAG to Richness: How Ramp Revamped Industry Classification[論文] Mapping 1,000+ Language Models via the Log-Likelihood Vector[Interview] OpenAI’s Deep Research Team on Why Reinforcement Learning is the Future for AI Agents[blog] You could have designed state of the art positional encodingSmarter, Better, Faster, Longer: A Modern Bidirectional Encoder for Fast, Memory Efficient, and Long Context Finetuning and InferenceAIによる3行まとめIntroductionMethodsModern TransformerEfficiency ImprovementsModel DesignTrainingTraining SettingsDownstream EvaluationEvaluation SettingDownstream Results and DiscussionEfficiencyLimitations
今週のTOPIC
※ [論文] [blog] など何に関するTOPICなのかパッと見で分かるようにしましょう。
出典を埋め込みURLにしましょう。
@Naoto Shimakoshi
[blog] <think>...</think> QwQ-Max-Preview
お試し:‣
- このblog自体がQwQ-Max-Previewで書かれている
- Qwen2.5-Maxをベースに、思考プロセスを明示的に示す「thinking」機能を追加したモデル
- エージェント関連のワークフローで優れた性能を出せる
- どのように学習させてるかのTechnical Reportは出ていない
- 今後
- アプリのリリース
- 小型の推論モデル(QwQ-32B)をオープンソース化
- Apache 2.0ライセンスで公開される予定
@Yuya Matsumura
Introducing Mercury, the first commercial-scale diffusion large language model
- 拡散モデルを元にした初の商用レベル(d)LLMであるMercury
- 推論の仕方面白い。いっきにガッと生成した上で修正していっている。
- めっちゃ早い(10x)


- 画像と違って言語は離散的であり可変長であることから難しいと考えられていた部分。
- ノイズを除く、という挙動からすると、全体の一貫性が重要なコード生成などに強いか?一度生成してから前に戻る、みたいなお気持ちの生成ができる?
- もちろん画像には強いわけなので、マルチモーダル化が楽しみ
- 論文出たら読みたい
@Tomoaki Kitaoka
[blog] From RAG to Richness: How Ramp Revamped Industry Classification
- 業種の分類がビジネス上大事だが、業種の入力がセールスメンバーだったり顧客自身だったりサードパーティデータだったりバラバラで実際に入力されるデータも間違っていたり、抽象的すぎて有用でなかったり使える状態ではなかった
- 解決策
- standard taxonomiesの導入
- NAICSコード
- RAGを活用したClassification Model を作成
- 類似度計算と推薦生成
- ビジネスのベクトルと知識ベース間の類似度を計算し、最も関連性の高い上位k件のNAICSコードを推薦
- LLMによる最終選定
- 2段階のプロンプトを使い、まず推薦リストを絞り込み、その後で最適なNAICSコードを最終選定
- 検証とログ記録
- LLMの出力が有効なコードかをチェックし、Kafkaで各中間結果をログとして記録

@Shun Ito
[論文] Mapping 1,000+ Language Models via the Log-Likelihood Vector
- 数ある言語モデルの性能や特徴を比較したい
- ベンチマークタスクの評価 → モデル内部でどんな確率分布を持っているかまではわからない
- テキスト生成による比較 → pair-wiseの生成 & 比較が必要で計算コストが高い
- 提案手法
- 事前に用意した大規模テキストコーパスを使ってモデルの特徴ベクトルを計算する
- モデル特徴ベクトルの計算プロセス
- 大規模テキストコーパスそれぞれに対する対数尤度値(与えられたテキストを生成する確率の対数値)を
- 全て並べたものが対数尤度ベクトル
- これをKモデル分並べた対数尤度行列を作る
- 対数尤度行列を行方向に中心化
- さらに列方向に中心化
- 結果的に得られた各行がモデルの特徴ベクトルとなり、ベクトル間の距離でモデルの確率分布間のKL-divergenceが近似できるようになる








- 実験
- テキストコーパス: Pileデータセットから抽出した10,000テキスト
- 1018モデルで実験
- 二重中心化済みの対数尤度行列
- t-SNEの可視化
- 最も生成確率の高かったテキストカテゴリの分布
- モデルの特徴ベクトルからベンチマークスコアを回帰した実験 → 相関高く予想できる






@qluto (Ryosuke Fukazawa)
[Interview] OpenAI’s Deep Research Team on Why Reinforcement Learning is the Future for AI Agents
要約:
この動画では、OpenAIの新製品「Deep Research」について、開発者であるIssa FulfordとJosh Tobinがその背景や技術、用途について語っている。
- 機械学習の基本原則とDeep Researchの開発
- 機械学習の基本原則として、「最適化したものが結果として得られる」という考え方がある。
- モデルを手作業で作るよりも、強化学習を活用し、エンドツーエンドで最適化したほうが優れた結果を生む。
- Deep Researchは、強化学習を活用して高度なリサーチタスクを実行できるように設計されている。
- Deep Researchとは?
- オンライン検索を行い、包括的なレポートを作成するAIエージェント。
- 人間が何時間もかけるようなタスクを5~30分で完了できる。
- 既存のChatGPTよりも深い調査と詳細な情報提供が可能。
- 「Operator」に続くOpenAIの第2のエージェント型プロダクト。
- 開発の背景
- 1年ほど前から開発を開始。
- モデルに「事前に考える」ことを学習させる新しい推論アプローチを適用。
- 特に、**長期的な推論が必要なタスク(オンライン調査、情報整理など)**に最適化された。
- ユースケース
- ビジネス:市場調査、企業分析、不動産調査、医療研究。
- 個人用途:買い物、旅行計画、教育(学習支援)。
- 技術者向け:最新の技術文献・パッケージドキュメント検索、コードリサーチ。
- 技術的な仕組み
- 「o3」モデルをファインチューニングしたもの。
- エンドツーエンドの強化学習によって、より柔軟で適応的な検索と分析が可能に。
- 📝 実際のウェブの情報をみて都度戦略を変えるといったことが可能になるポイント
- ブラウジングツールとPythonツールを活用して、より正確な分析と情報整理を行う。
- 📝 隠れた鍵となったのは高品質なデータセット。しょっちゅう言われることだが学習データの質が最終的なモデルの質を決めるといってもいいほど重要だと強調されていた
エンドツーエンドの訓練をしていないサービスはいろいろありますが、そういうサービスでは新たに得た情報に合わせて戦略を柔軟に変更するとか、そういうレベルまでは難しいです。
多くの人がネットでやっている「エージェントのワークフローを人がグラフ上に定義して、各ノードで言語モデルを使う」という手法で開発していくと、最初のプロトタイプは作れても、現実の複雑なケースに対応するのがすごく難しいんですよ。あらゆる分岐や状況を人間が想定する必要があって、それはほとんど不可能ですし、モデルがノードごとに下す決定も、実はちゃんと訓練されているわけじゃないからうまくいかない。それよりも、「ユーザーが求めるタスクを直接解決できるよう最適化されたモデル」を作る方が圧倒的に良いんです。
- 他のAIと何が違うのか?
- 競合する他の「Deep Research」系プロダクトと比べて、より高度な分析能力と検索能力を持つ。
- 事前にユーザーの要件を明確にする「質問フロー」を導入しており、より精度の高い回答を提供。
- 今後の展望
- データソースを拡充し、個人のプライベートデータにも対応。
- 強化学習の活用をさらに拡大し、より複雑なタスクにも適応できるように。
- エージェント技術の進化により、様々な領域に適用可能な多機能AIの開発を進める。
- AIエージェントと強化学習の未来
- 2025年は「エージェントの年」になると予測。
- 強化学習(RL)が復活し、AIの高度化に重要な役割を果たす。
- 将来的には、現在の「Deep Research」のようなエージェントがより多くの作業を自動化し、生産性向上に大きく寄与すると期待される。
まとめ
Deep Researchは、強化学習を活用した高度な情報収集・分析エージェントであり、仕事や日常のリサーチタスクを大幅に効率化する。今後、エージェント技術の進化とともに、より多くの分野で活用が広がると予測される。
@Yosuke Yoshida
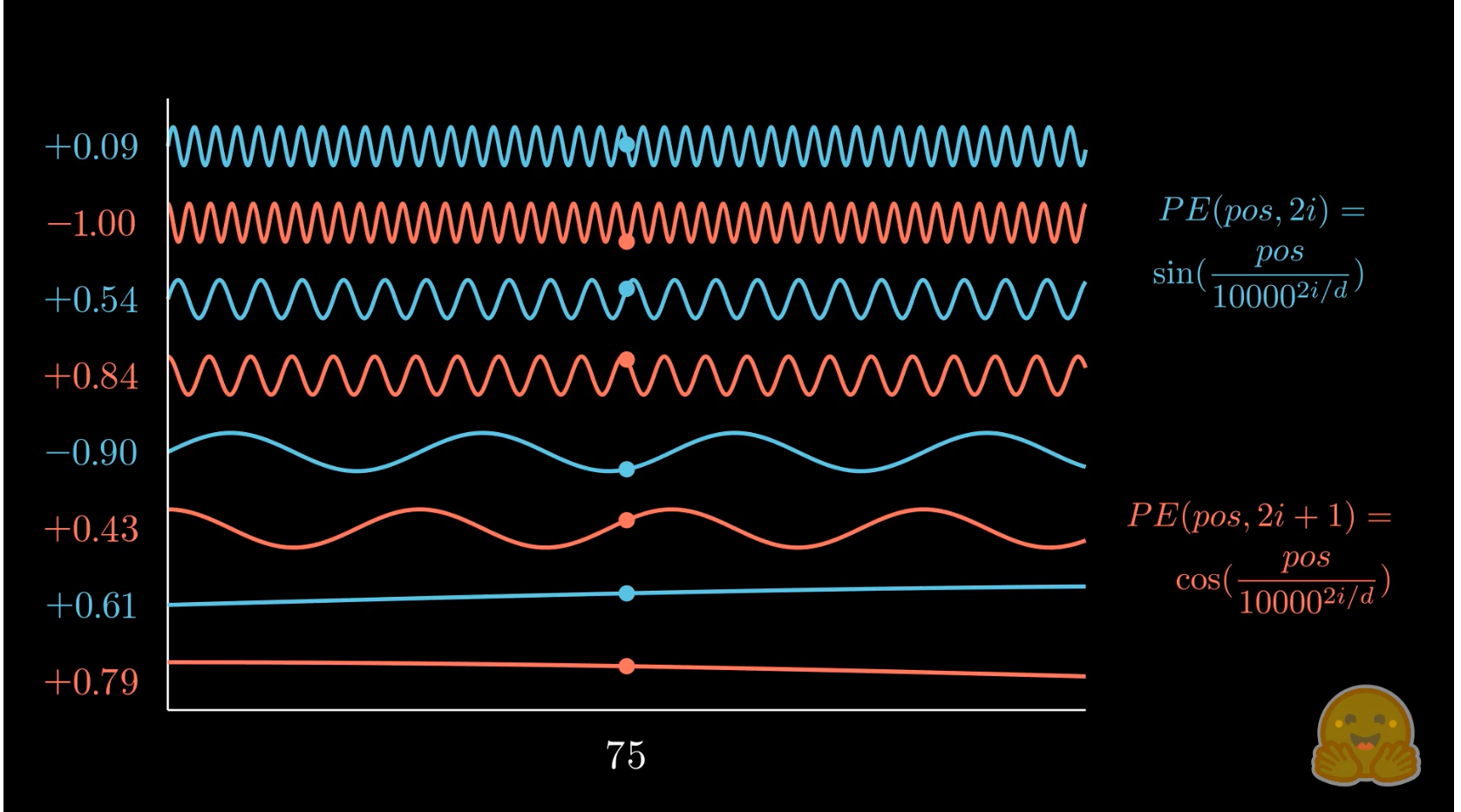
[blog] You could have designed state of the art positional encoding
- positional encodingの望ましい性質
- 各位置にシーケンスの長さに関わらず一意のエンコーディング
- 同じ位置のトークンはシーケンスの長さが変わっても不変
- 2つのエンコードされた位置間の線形関係
- 位置 のエンコーディングが分かっていれば のエンコーディングを容易に計算可能
- 学習時よりも長いシーケンスへ一般化可能
- モデルが学習できる決定論的プロセスによって生成される
- 複数次元に拡張可能
- マルチモーダルモデルが標準となる現代では、位置エンコーディング方式が1次元からn次元に自然に拡張できることが重要
- Integer Position Encoding
- トークン chased のインデックスからpositional encodingベクトルを作成し埋め込みに加算
- 位置の値の大きさが、実際の入力の値に比べてはるかに大きいため、信号対雑音比が非常に低くなり、モデルが意味的な情報と位置情報を分離するのが困難
- シーケンス長 とし、 で正規化することを考えるかもしれないが、この場合シーケンス長が異なるとエンコーディングが一意とならない

- Binary Position Encoding
- 位置の整数値を埋め込みの各成分に加算する代わりに、その整数値を2進数表現に変換する方法が考えられる
- 値の範囲の問題は解決され、異なるシーケンス長においても一意で一貫したエンコーディングが得られるようになった
- 低次元のトークン埋め込みをプロットし、異なる値に対してバイナリ位置ベクトルを加えた結果を視覚化すると結果が飛び飛びになってしまう
- 最適化プロセスは、滑らかで連続的、かつ予測可能な変化を好むため、同じ値域を持ちながらもスムーズな関数が求められる


- Sinusoidal positional encoding
- Attention Is All You Needで定義されたpositional encoding
- 前述のbinary position encodingのアニメーションと類似
- 望ましい性質の線形関係より、位置 だけシフトさせる線形変換行列 を求めると、以下のように回転行列となり、相対位置を回転としてエンコードしていることが分かる
- Rotary Postional Encoding
- これまでpositional encodingのベクトルを個別に生成し、それをトークン埋め込みに加えてからself-attentionのQ, K, Vの行列に渡してきたが、位置情報をトークン埋め込みに直接加えると、意味情報に位置情報が混ざり合い、埋め込みのノルムが変化してしまう
- ノルムを変更せずに情報をエンコードすべきであり、そのための鍵は乗法的なアプローチへのシフト
- あるトークンが他のトークンに与える影響は の内積よって決まるため、positional encodingはこの部分に焦点をあてるべき
- を2次元のペア毎に分解して各ペアに対して回転行列を乗算することでエンコードする


Smarter, Better, Faster, Longer: A Modern Bidirectional Encoder for Fast, Memory Efficient, and Long Context Finetuning and Inference
- Benjamin Warner, Antoine Chaffin, Benjamin Clavié, Orion Weller, Oskar Hallström, Said Taghadouini, Alexis Gallagher, Raja Biswas, Faisal Ladhak, Tom Aarsen, Nathan Cooper, Griffin Adams, Jeremy Howard, Iacopo Poli
AIによる3行まとめ
- ModernBERTは、BERTなどの従来のエンコーダーモデルに対して、最新のアーキテクチャ改善と大規模データ (2兆トークン) によるトレーニングを施し、下流タスクの性能を大幅に向上させた。
- 長文脈 (最大8192トークン) に対応し、分類、検索、コード理解など多様なタスクで従来モデルを上回る成果を達成している。
- ローカル・グローバル交互アテンションやunpadding技術により、メモリ効率と推論速度を大幅に改善し、一般的なGPU上で高速かつ効率的な推論を実現している。
Introduction
- 大規模言語モデルの人気が高まっているにもかかわらず、encoderモデルは分類や固有表現抽出などNLPのタスクに広く利用されている
- encoder-decoderやdecoderモデルと比較して、推論が高速で大規模な文書コーパスの検索や判別タスクの迅速な実行が可能であることが利点
- Retrieval-Augmented Generation (RAG) パイプラインにおいてencoderに基づく情報検索は中核的なコンポーネントとなっている
- しかし、これらのencoderモデルは改善されることなく、BERTなどの旧来のモデルに依存することで多くの欠点に直面している
- 制限された系列長や語彙サイズ
- 非効率な計算
- 狭いドメインに限定されたトレーニングデータ (コードデータや最新の出来事に関する知識の欠如)
- 下流タスクの性能
- ModernBERT
- 長い系列長において下流タスクの性能と効率を向上させるためにアーキテクチャを改良
- コードデータを含む2兆トークンで訓練
- ModernBERT-baseおよびModernBERT-largeの2種類のモデルをリリース
- 既存のすべてのencoderモデルに対して、幅広い下流タスクで最先端の性能を達成
- これらの成果は、従来のモデルよりも約2倍速く8192トークンのシーケンスを処理する非常に高い推論効率とともに実現
Methods
Modern Transformer
Bias Terms
- 最終のdecoder線形層を除くすべての線形層のバイアス項、正規化層における全てのバイアス項を無効化し、線形層により多くのパラメータ予算を割り当てることを可能とした
Positional Embeddings
- absolute positional embeddingsの代わりにrotary positional embeddings (RoPE) (Su et al., 2024) を採用
- RoPEは、トークン間の相対的な位置関係を回転行列の操作を用いて表現する手法で、短い文脈だけでなく長い文脈でも優れた性能を示している
- 多くの機械学習フレームワークで実装されており、コンテキストを拡張するのも容易
Normalization
- 学習の安定化のために、pre-normalizationを採用
- embedding layer の後に LayerNorm を追加しており、重複を避けるため最初の attention layer のLayerNormを削除
Activation
- BERTのGeLU活性化関数の上に構築された、Gated-Linear Units (GLU) ベースの活性化関数であるGeGLUを採用
Efficiency Improvements
Alternating Attention
- 最近の長文脈モデルの研究 (Gemma et al., 2024) に倣い、ModernBERT のアテンション層は、シーケンス内のすべてのトークンが互いにアテンションを行うglobal attentionと、トークンが小さなsliding window内でのみ相互にアテンションを行うlocal attentionとを交互に採用
- ModernBERT では、3層ごとに1層が RoPE theta 160,000 を用いたglobal attentionを、残りの層は RoPE theta 10,000 を用いた128トークンのlocal sliding window attentionを使用
Unpadding
- 従来のencoderモデルでは、短いシーケンスにpaddingトークンを追加することで並列計算を可能としていたが、これは意味を持たないpaddingトークンにも計算リソースが使われ無駄
- Flash Attentionの可変長アテンションを活用し、バッチ内のすべてのシーケンスを単一のシーケンスに連結して処理することで計算リソースを意味のあるトークンのみに集中
- ModernBERTではtoken embedding layerの前に入力をUnpaddingし、必要に応じてモデルの出力を再度paddingすることで、他のUnpadding手法に比べ10~20%の性能向上を実現
Flash Attention
- Nvidia H100向けの最新バージョンであるFlash Attention 3は、sliding window attentionに対応していなかったため、global attentionにFlash Attention 3を、local attentionにFlash Attention 2 を併用
torch.compile
- PyTorchが提供するコンパイル機能を活用し、互換性のあるすべてのモジュールをコンパイルすることで、訓練効率を向上
- コンパイルのオーバーヘッドはごくわずかで、スループットが10%向上
Model Design
- ModernBERT は、推論速度の大幅な低下を避けつつできるだけ Deep & Narrow にすることを目指して設計された
- モデルの内部パラメータは、GPUのテンソルコアやストリーミングマルチプロセッサの数に合わせて最適なタイル配置ができるように設計されており、ハードウェアのリソースを最大限に活用
- ModernBERT base
- 総パラメータ数: 149M
- 22層
- hidden size: 765
- GLU expansion: 2304
- ModernBERT large
- 総パラメータ数: 395M
- 28層
- hidden size: 1024
- GLU expansion: 5248
Training
Mixture
- ウェブドキュメント、コード、科学文献など、様々なデータソースから収集された主に英語のデータ2兆トークンで訓練されています
Tokenizer
- コード関連タスクにおいてより良いトークン効率と性能を提供する修正済みの OLMo トークナイザーを採用
- BERT モデルと同じspecial token (e.g., [CLS] [SEP])およびテンプレートを使用しており、後方互換性を保っています
- 最適な GPU 利用を実現するため、語彙数は 64 の倍数である 50,368 に設定され、下流アプリケーションをサポートするために 83 個の未使用トークンが含まれる
Sequence Packing
- 複数のシーケンスをどのように組み合わせるかを決定するために貪欲法を用いることで高効率なpackingを実現
Training Settings
MLM
- MosaicBERTで用いられたMasked Language Modelingの設定を採用
- Next-Sentence Predictionは、性能向上が見られずオーバーヘッドが大きいため削除
- 元々の15%のマスキング率は最適ではないことが示されたため30%のマスキング率を採用
Optimizer
- AdamWを改良したStableAdamW optimizerを採用
- パラメータごとの学習率調整としてAdafactorのアップデートクリッピングを追加
- StableAdamWの学習率クリッピングは、標準的な勾配クリッピングよりも下流タスクでの性能が優れており、より安定したトレーニングを実現
Learning Rate Schedule
- 事前学習はtrapezoidal Learning Rateを採用
- コールドスタートの問題なく任意のチェックポイントから継続学習が可能になるという利点がある
- ModernBERT-base
- 30億トークンのウォームアップに続き、1.7 兆トークンにわたって 8e-4 の一定学習率で訓練
- ModernBERT-large
- 20億トークンのウォームアップ後、9000億トークンに対して 5e-4 の学習率で訓練したが、数百億トークン分の損失が横ばいとなったため、残り8000億トークン分の訓練を 5e-5 で再開
Batch Size Schedule
- 初めは小さい勾配蓄積バッチから始まり、時間の経過とともにフルバッチサイズへと増加
- 単純にバッチサイズを増やすのではなく、各バッチサイズで行う更新ステップ数が同じになるように調整
- ModernBERT-base
- 初期バッチサイズ: 768トークン
- 最終バッチサイズ: 4,608トークン
- ModernBERT-large
- 初期バッチサイズ: 448トークン
- 最終バッチサイズ: 4,928トークン
Weight Initialization and Tiling
- ModernBERT-base
- Megatron の初期化手法 (Shoeybi et al., 2019) に従い、ランダムな重みで初期化
- ModernBERT-large
- Phi モデルファミリー (Li et al., 2023; Javaheripi et al., 2023) の手法に従い、ModernBERT-base の重みから初期化
- center tilingとwraparoundの利用
- baseの小さな重み行列を、largeの大きな重み行列の中央に配置 (center tiling)
- 行列の周辺の不足した部分はbaseの重みを再利用して埋める (wraparound)
- 中心に配置して周辺をランダムな値で初期化する方法や、行列の端から順にタイル状に埋める方法も試したが性能が劣ることが実験で確認
Context Length Extension
- 1024トークンのコンテキスト長とRoPE theta 10,000で1.7兆トークンの訓練の後、global attention層のRoPE thetaを160,000に増加することでコンテキスト長を8192トークンに拡張し、さらに3000億トークン分の追加学習
- 追加学習は2ステージで行った
- 低学習率での学習
- 一定の学習率 (3e-4) で2500億トークンの学習
- 8192トークン長のデータをサンプリング (元のデータセットから、Fu et al. (2024) に従ってサンプリング)
- 高品質なデータのアップサンプリングと学習率の減衰
- Gao et al. (2024) に基づき、高品質なデータソースをアップサンプリング
- 1 - sqrt 学習率スケジュールを用いて500億トークン分の減衰フェーズを実施
Downstream Evaluation
Evaluation Setting
Natural Language Understanding
- General Language Understanding Evaluation (GLUE) ベンチマークで評価
Text Retrieval
- 単一ベクトルを用いるDense Passage Retrieval (DPR) と複数ベクトルを用いるColBERTの両方でモデルを評価
- 評価指標はBEIR ベンチマークにおいてnDCG@10
- 単一ベクトル検索
- MS-Marcoデータセットから125万サンプル
- バッチサイズ16で全体の5% warmup
- sentence-transformersを用いてcontrastive learningでトレーニング
- 複数ベクトル検索
- MS-Marcoデータセットから81万サンプル
- バッチサイズ16で全体の5% warmup
- JaColBERTv2.5の訓練設定を採用し、知識蒸留による教師モデルからの学習
- 教師モデルとしてBGE-M3から得られたスコアを利用
- PyLateを用いてトレーニング
Long-Context Text Retrieval
- encoderを対象とした長文テキストの評価ベンチマークは比較的少ない
- 既存のベンチマークは主に生成タスク向けに設計されており、検索タスクに特化した評価が難しい
- MLDRデータセットで評価
- 長い文脈を対象としたretrievalベンチマークで、200,000件を超える長文ドキュメントを含む
- 以下の3つの設定で評価
- 単一ベクトル – ドメイン外
- 短文脈のMS-MARCOで訓練されたモデルは、追加のファインチューニングを行わず、長文脈MLDRで評価
- 単一ベクトル – ドメイン内
- MS-MARCOで訓練されたモデルは、評価前に長文脈MLDRの訓練セットでさらにファインチューニング
- 複数ベクトル – ドメイン外
- ColBERTモデルはトークン単位のMaxSimにより、特別な訓練を行わなくても長文脈に対応できる
- 最良のチェックポイントを、MLDRで追加のファインチューニングなしに直接評価
Code Retrieval
- 従来の多くのencoderは主にテキストデータのみで訓練されていたのに対しModernBERTはコードで事前学習され、コードに対応したトークナイザーを使用
- 以下評価データセットを用いてCoIRフレームワーク(Li et al., 2024)を用いて、単一ベクトル検索タスクとして評価
- CodeSearchNet
- 与えられたコードブロックに対して、関連するdocstringやコメントを識別
- StackOverflow-QA
- StackOverflow上の質問に対して、関連性の高い回答を識別
Downstream Results and Discussion

Short-Context Retrieval
- BEIRではDPRおよびColBERTにおいて、最新のGTE-en-MLMおよびNomicBERTモデルを含む既存のエンコーダを上回る
Long-Context Retrieval - Single Vector
- 長文ファインチューニングを行わなくても、ModernBERTは短文モデルや長文対応のNomicBERTを上回る性能を示す一方で、GTE-en-MLMに比べると明らかに劣る
- 評価をドメイン内で行うと、その性能差は大幅に縮小し、両モデルはほぼ同等のパフォーマンスを示す
- これは、ModernBERTが長い文脈のシーケンスを効果的に処理できるものの、より適応的なチューニングが必要である可能性を示唆
- local attentionの影響や、GTE-en-MLMが事前学習の計算予算の大部分をより長いシーケンス長に費やしていることなど、今後の研究の課題
Long-Context Retrieval - Multi-Vector
- 長文脈モデルの中でも、ModernBERTは他のモデルを上回り、両方のモデルサイズで少なくともNDCG@10は9ポイント上回る
- これらの大幅な向上が、長期間の事前学習によりほとんどトークンが十分に学習されない状態にならないことや、ColBERTスタイルの検索とlocal attentionとの間に相乗効果が生じたことに起因する可能性があると考えていますが、この現象のさらなる解明は今後の研究課題
Natural Language Understanding
- ModernBERT-baseは、すべての既存モデルを上回る性能を示す
- DeBERTaV3で使われているReplacedToken-Detectionの方が下流のNLUの性能を発揮すると考えられてたが、MLMで学習されたモデルとして初めてこれらの既存モデルを上回った
- ModernBERT-largeは、DeBERTaV3-largeとほぼ同等の性能を発揮しているが、パラメータ数は約10%少なくトークン処理速度は半分
Code
- CodeSearchNet、StackQAの両方で、ModernBERTは他のすべてのモデルを上回る性能を示す
- これは、プログラミングデータを含むデータミックスで訓練された唯一のモデルであるため、予想された結果
- 他のタスクにおけるModernBERTの優れた性能を合わせて考えると、ModernBERTは自然言語テキストの処理能力に影響を与えることなく、コードの理解力を向上させている
Efficiency
- モデルが異なる長さのテキストをどれだけ効率的に処理できるかを測定するため、異なる長さの文書セットを用いて推論速度を評価
- 固定長セット
- 短い文脈 (fixed short-context)
- 512 トークン
- 長い文脈 (fixed long-context)
- 8192 トークン
- 可変長セット
- 各文書のトークン数は、正規分布に従って決定
- 分布は最大シーケンス長の半分を中心としたものになり、それぞれ 256 トークンと 4096 トークンを中心とする設定
- 評価指標
- 10回の実行で平均した1秒あたりの処理トークン数
- ハードウェア
- NVIDIA RTX 4090

- 短いコンテキスト (512トークン) の場合
- ModernBERTは、短文入力(512トークン)において、最新のencoderと比較して高速に処理
- ただし、BERTやRoBERTaモデルよりは遅い
- 長いコンテキスト (8192トークン) の場合
- ModernBERTは、競合するすべてのencoderよりも高速に処理が可能
- baseでは、次に速いencoderの約2.65倍、largeサイズでは約3倍の速度で処理
- 可変長入力の場合
- 可変長入力においては、GTE-en-MLMモデルとModernBERTモデルは、他のすべてのモデルよりも大幅に高速
- この主な理由は、無駄なパディング部分を除去する(unpadding)処理により、計算効率が向上しているため
- GTE-en-MLMと比較して、短いコンテキストでは14.5〜30.9%多くのトークンを1秒間に処理、長いコンテキストの場合その差は98.8〜118.8%に達する
- この効率向上は、ModernBERTがlocal attentionを活用している点に起因
- また、ModernBERTは、両モデルサイズとも全体として最もメモリ効率に優れたモデル
- ModernBERT-baseは、両入力長とも他の全モデルの2倍のバッチサイズを処理可能
- ModernBERT-largeは、短文脈入力においてはBERT-largeよりもややメモリ効率が劣るが、他のすべての大規模モデルよりも少なくとも60%大きなバッチを処理することができる
Limitations
- 本研究は英語に特化しており、非常に大量のトークンを用いて学習が行われているため、他の言語、特にリソースが乏しい言語に対しては直接適用できない、または性能が低下する可能性がある
- DeBERTaV3が分類タスクでは強い結果を示す一方、検索タスクでは弱い結果となっていることから、MLMとRTDの両方を活用する訓練の方が分類タスクで最良の結果を得るのに適している可能性がある