
2025-03-06 機械学習勉強会
今週のTOPIC[blog] The State of Machine Learning Competitions[blog] Clineに全部賭ける前に 〜Clineの動作原理を深掘り〜[repo] Eino: The ultimate LLM/AI application development framework in Golang.[blog] Sarashina2.2:数学・コーディングタスクの性能を向上させた日本語言語モデル[blog] Deep research System Card | OpenAI[blog] GraphRAG Toolkit を使って Amazon Bedrock で GraphRAG を構築するメインTOPICRegMix: Data Mixture as Regression for Language Model Pre-training3行まとめ by Claude 3.7 Sonnet背景既存手法提案手法:RegMix実験コメント
今週のTOPIC
@Naoto Shimakoshi
[blog] The State of Machine Learning Competitions
- 2024年に開催された機械学習コンペの概要や優勝手法などについてまとめてくれているブログ
- 使用言語的には基本的にPython、Pytorch。Tensorflow, JAXは1割程度。
- 最適化コンペなどだとRustなどの利用も目立つ
- accelerateなどで分散学習を行うようになってきている。

- ハードウェア
- A100がめっちゃ使われている

- NLPの手法
- EncoderモデルからDecoderモデル
- Llama、Mistral、Gemma、Qwen、および DeepSeek モデル
- Encoderの使い方
- 検索にはEncoderモデル (ColBERT → Phi2など)
- DeBERTaのようなEncoderモデルをDecoderモデルの出力を使って微調整する手法なども
- アンサンブル要員
- 今後はDeBERTaよりModernBERTが流行るのではないかと予想
- 量子化などの高速化も重要になってきている。
- AutoGPTQを用いて8bitに
- 時系列データ、テーブルデータの手法
- 勾配ブースティングが依然として人気
- 推論時はXGBoostはGPUを使い果たす傾向にあるが、CatBoostはGPUの消費量が少なく高速、などといった知見も
- DeepLearning系の手法
- アンサンブル要員
- マルチターゲット回帰とかだとMLPの方が良かったり
- Pandas → polarsへの移行
- ARC Prize 2024のテクニカルレポートから効果的なアプローチ
- LLMでソリューションを解くPythonプログラムを生成させる。反復デバッグやDSLでプログラムを指定。
- Private test dataset全体 or 特定のタスクを使ってテスト時にFine tuningを行い、テスト時に重みを更新する。In Context Learningよりパフォーマンスが大幅に向上する。
@Yuya Matsumura
[blog] Clineに全部賭ける前に 〜Clineの動作原理を深掘り〜
- 最近改めて盛り上がっていますね。Cursorに1年課金しちゃったよ。
- Cline は Cursor などに比べて、勝手に行動する割合が非常に大きい(その分リスクもあり、パンドラの箱とか呼ばれたり)。
- 業務の自動運転化を達成したい我々として、人間とのインタラクションをできるだけ少なくして精度高くタスクを遂行することには強い関心があり、いろいろ調べている。
- このブログは Cline を題材にしつつ一般的なAIエージェントの裏側についてざっと理解できる良コンテンツだと感じた。
- ブログでピックされていた部分だけでも面白い。
- 会話の効率化を図るため、アシスタントに冗長な会話をさせないような指示
- 無駄な対話の排除
- ユーザーからの入力を少なくしたいため、ユーザーに追加質問をする、のツール定義において
@Tomoaki Kitaoka
[repo] Eino: The ultimate LLM/AI application development framework in Golang.
- ByteDanceが開発しているオープンソースのLLMアプリケーション開発フレームワーク

- ドキュメント
- API
- Chain example
- Graph example
| API | Characteristics and usage |
| Chain | Simple chained directed graph that can only go forward. |
| Graph | Cyclic or Acyclic directed graph. Powerful and flexible. |


@Shun Ito
[blog] Sarashina2.2:数学・コーディングタスクの性能を向上させた日本語言語モデル
- 数学・コーディングのベンチマークで既存モデルを大きく上回るSarashina2.2を公開

- 数学・コーディングの性能向上のためのアプローチ
- ウェブ文書から数学・コーディングタスクに貢献すると考えられる文書を抽出
- Qwen-MathだとURLを見たりFastTextで数学データかを分類したりした上で、言語モデルを使って余分なデータを排除して収集
- 抽出したデータを元に、質問応答形式の文書をLLMで生成してデータ拡張
- 性能比較

@qluto (Ryosuke Fukazawa)
[blog] Deep research System Card | OpenAI
Deep researchのシステムカードも公開されていたので、先週のインタビューに続いて紹介。
インタビューでは高品質なデータセットが成果の鍵だと話されていましたが、より具体的なことが記されています。
- データセットについて
- 訓練データセットには、正解が明確で自動採点可能なタスクから、採点基準(ルーブリック)を伴うより自由度の高いタスクまで、さまざまな課題が含まれています。訓練中、モデルの応答は、チェイン・オブ・ソート(思考の連鎖)モデルを用いた採点プロセスにより、正解やルーブリックと比較して評価されます。
- 学習データには、安全性に関する既存のデータセット(OpenAI o1から流用)に加え、新たに作成されたブラウジング特化の安全性データも使用されました。
- 対応したリスクについて
- プロンプトインジェクション
- 悪意あるページに誘導され、意図しない命令を実行しないように
- 対策
- 追加トレーニングで耐性を強化
- モデルが任意のURLへ移動することを制限
- ユーザーのデータが漏洩しないように制御
- 各種攻撃の成功率が事前テストでは約3〜10%だったが、対策後は0%に低下。
- 禁止コンテンツ
- 危険な情報を提供する可能性を下げる
- 対策
- 出力フィルター(禁止コンテンツの検知・拒否)
- モデルの学習データに安全性の指標を追加
- 従来のGPT-4oやo1と比較して、不適切なコンテンツへの応答をより適切に制限。
- プライバシー
- 個人情報をウェブ上から収集・統合することによるプライバシー侵害リスクを下げる
- 対策
- 個人情報関連の検索・回答を拒否するようにトレーニング
- システムレベルでのブロックリスト導入
- コード実行
- Pythonのコード実行機能を悪用される可能性を下げる
- 対策
- インターネットアクセスを禁止
- サンドボックス環境でのみ実行可能に制限
- バイアス
- モデルが特定の偏見を持つ可能性を下げる
- 対策
- 追加トレーニングによりバイアスを低減
- BBQ評価(バイアス評価指標)において、OpenAI o1-previewと同等の結果。
- ハルシネーション
- 実際には存在しない情報を生成する可能性を下げる
- 対策
- 検索結果に基づく回答を強化
- 出典リンクを提供
- 従来のモデルと比較して正確性が向上し、ハルシネーション率は13%に低下。
@Yosuke Yoshida
[blog] GraphRAG Toolkit を使って Amazon Bedrock で GraphRAG を構築する
- GraphRAG Toolkit は AWS が提供するオープンソースの GraphRAG 用ライブラリで、 GraphRAG を使ったシステムの構築を簡易化する機能を多く提供している
- Amazon Neptune Database をグラフ DB として、 Amazon OpenSearch Serverless をベクトル DB として使用可能
- このツールキットを使用することで、非構造化データからエンティティとそのリレーションを抽出し、ナレッジグラフとして保存、ユーザーの質問に対してこのナレッジグラフをクエリすることで、より関連性の高い情報を提供するアプリケーションを構築できる


- ドキュメント取り込みの手順
- ドキュメントを細かい単位に分割する(チャンキング)
- チャンクをLLMに渡して、命題(proposition)を抽出する
- 命題を LLM に渡して、トピック、文言、事実、エンティティを抽出する
- 抽出されたエンティティなどからナレッジグラフを構築し、グラフ DB に取り込む
- 文言を LLM に渡してエンベディングを行い、ベクトル DB に取り込む

メインTOPIC
RegMix: Data Mixture as Regression for Language Model Pre-training
ICLR2025 Spotlight
OpenReview: https://openreview.net/forum?id=5BjQOUXq7i
3行まとめ by Claude 3.7 Sonnet
- データミクスチャーの回帰による最適化: 言語モデル事前学習のためのデータミクスチャー選択を回帰問題として定式化し、小規模モデルの訓練結果を使って大規模モデルの最適データ混合比を予測する「RegMix」を提案。
- スケーラビリティと効率性: 1Mパラメータの小さなモデルを複数訓練して回帰モデルを構築することで、1Bや7Bのような大規模モデルの最適データミクスチャーを予測可能であり、従来手法(DoReMi)と同等以上の性能を10%の計算リソースで達成。
- 実証的発見: データミクスチャーは下流タスク性能に最大14.6%の影響を与え、高品質と認識されるWikipediaよりもCommonCrawlなどのWebコーパスが下流タスク性能と最も高い相関を示すことを発見。またドメイン間の相互作用は複雑で直感に反することが多く、自動最適化の必要性を裏付けている。
背景
- LLMの事前学習には多様なデータセットが必要
- 事前学習データの混合(data mixture)の仕方が性能に大きく影響する
- 例)Wikipedia、Github、Booksをそれぞれどれくらいの割合で含めるのが最適なのかを考えたい
- 最適なデータミクスチャーを決定する方法は確立されていない
- GPT-3では、人間の直感に基づいてWikipediaを過剰サンプリング (Brown et al., 2020)
- 手動によるデータ選択は拡張性に欠け、最適でない可能性が高い (Albalak et al., 2024)
既存手法
- トークンレベル選択
- 学習中に学習効果の低そうなトークンを動的に取り除く
- サンプルレベル選択
- 最適化アルゴリズムやperplexity、別のLLMを使って学習に使うサンプルを選ぶ
- グループレベル選択
- DoReMi (Xie, 2024): 100B tokens で訓練し、ドメインごとの損失を見て比率を決める
- 利用するモデル・データセットが大きく、計算コストが高い
提案手法:RegMix
アイデア: rank invariance of data mixtures

- 小さいモデル・少ないデータで最適な比率は、大きいモデル・多くのデータでも最適
RegMixの流れ

- Train small-scale proxy models
- ディリクレ分布から混合比率を複数パターンサンプリング
- 小さいモデルでそれぞれ学習・推論して評価値を計算
- Regression
- 混合比率を特徴量、評価値をラベルとして回帰モデル(線形モデルやTreeモデルなど)を学習
- Simulation
- 回帰モデルを使って未見の混合分布に対する評価値の分布を推定
- 推定された分布から最適な比率を特定
- Train a large-scale model
- 特定した最適な混合比率で大規模モデルを訓練
実験
実験設定
- データセット: Pile データセットから利用可能な17ドメインを利用

- 線形回帰モデル: 一般的なL2正則化付き線形回帰
- Treeモデル: LightGBM
回帰予測の評価
- 回帰データセット
- 訓練
- 1Mモデルを1B tokensで学習した時の評価値(Pile-CC Validation Loss)
- 混合比率は512パターン
- 評価(未知の混合比率で学習した時の評価値を当てられるか評価する)
- 1Mモデルを1B tokensで学習した時の評価値 x 未知の混合比率256パターン
- 60Mモデルを1B tokensで学習した時の評価値 x 未知の混合比率256パターン
- 1B モデルを25B tokensで学習した時の評価値 x 未知の混合比率64パターン
- 評価指標
- スピアマン相関係数、MSE(1Mモデル同士の比較のみ)
- 結果
- 予測性能は線形回帰 < LightGBM → 予測ではLightGBM、分析では線形回帰を使う
- プロキシモデル数は訓練トークン数よりも重要


混合比率が下流タスクの性能に与える影響

- 1Bパラメータモデルを64種類の異なるミクスチャーで訓練
- 最高スコアと最低スコアの差は、最大14.6ptになった → 比率が性能に大きく影響する
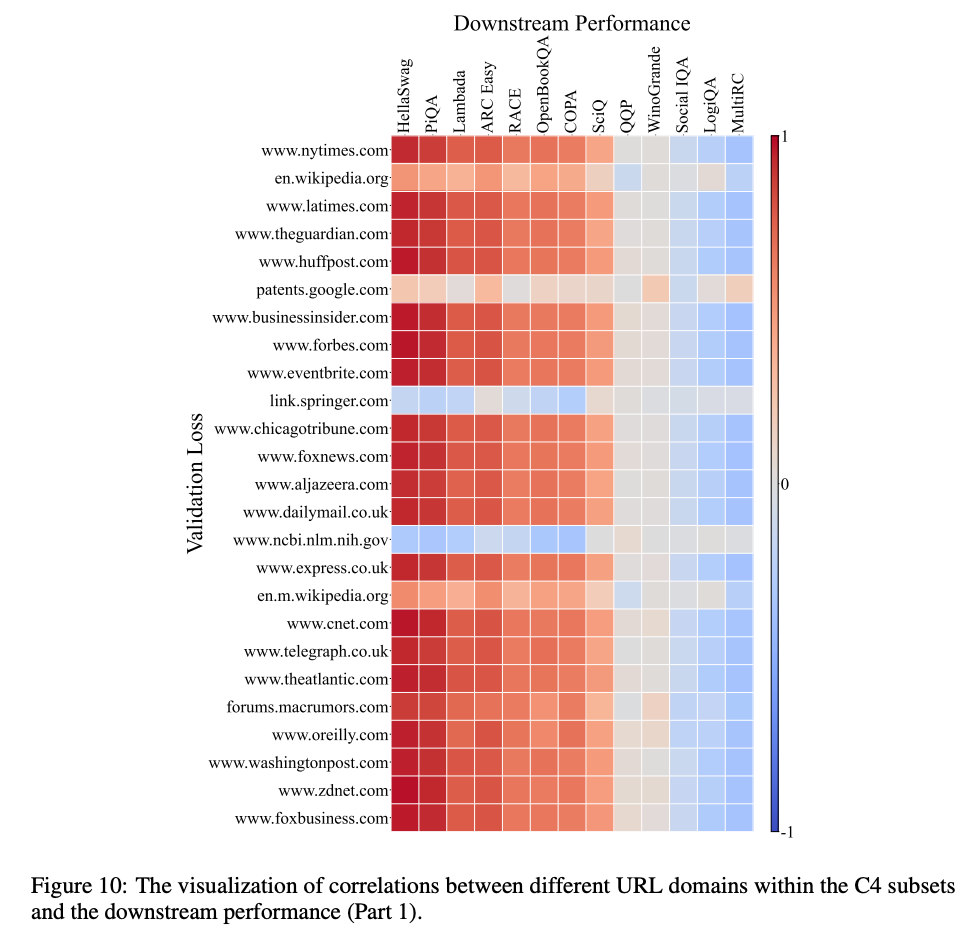
データのドメインごとのvalidation loss vs. 下流タスク性能の相関

- 定番のWikipediaデータセットはあまり相関が高くなかった
- Webコーパスの Pile-CC が最も相関が高くなった
- Webドメイン(一部抜粋)ごとの比較: 多くのドメインでPile-CCと同様の相関
- diverse coverage across various topics and domains が効いてそう
ドメイン full versionの表
RegMixによる混合比率設定の評価
- 比較手法
- Human: Pileデータセットを使っていた過去論文 (Gao, 2021)で決められていた比率を利用
- DoReMi: 論文内で示されていた最適な比率を利用
- PPL: perplexity-based filtering method
- ODM: 論文内で示されていた最適な比率を利用
- Pile-CC: (上で有効だと示されたので)Pile-CCだけを使ったデータセット
- RegMIX: 提案手法
- 結果
- 平均的にはRegMIXが最適な結果。次点でPile-CC。
- Estimated FLOPsは既存手法の10%程度。
- Training Tokensを変えても一貫して提案手法が良いValidation Loss (Pile-CC) になった


ドメイン間の相互作用
- ドメインごとに、Validation Lossと線形回帰の係数との相関を比較
- あるドメインが別のドメインに影響を与えることがあり、人間の直感で最適な混合を選ぶのは難しい
- 例えばPhilPapers(哲学分野の文献)が多くのドメインのValidation Lossと強い相関にある

コメント
- 提案手法はわかりやすく、効果も出ていてよい
- Wikipediaがあまり効果的でないのは意外
- 事前学習する時に試してみる価値はあるかも