
2025-03-21 機械学習勉強会
今週のTOPIC[blog] Sarashina2-Vision-8B, 14Bの性能評価[論文] LLM 推定ラベルと弱教師あり学習による 反復的アノテーション更新[論文] Gemini Embedding: Generalizable Embeddings from Gemini[slide] 日本語ModernBERTの構築メインTOPIC概要1. Introduction2. 関連研究3. Introducing the AI co-scientist3.1 The AI co-scientist system overview3.2 From research goal to research plan configuration3.3 The specialized agents underpinning the AI co-scientist3.4 Expert-in-the-loop interactions with the co-scientist3.5 Tool use in AI co-scientist4. Evaluation and Results5 Limitations6 Safety and Ethical Implications7 Future Work8 Discussion9 Conclusion
今週のTOPIC
@Yuya Matsumura
[blog] Sarashina2-Vision-8B, 14Bの性能評価
- SB Intuitionsさんのリリースした日本語向けオープンVLM Sarashina2-Vision-8B, 14B の性能評価についてのブログ
- 以下のベンチマークを利用して評価。それぞれ既存のものに対して一工夫してより正確な評価を行おうとしている。
- JMMMU:学術的なドメインの多様な画像、多肢選択回答形式と、少量の自由記述回答形式
- 選択肢の記号であるA,B,C,Dのような記号をVLMが回答できなかった際に、従来はランダムに回答を選んで評価していたが、これを不正解に。(1000ちょっとしかサンプルないのにランダムにするのけっこうブレそうでそれは良くないよねって思った)
- Heron-Bench:自然画像やアニメ画像、自由記述回答形式
- LLM-as-a-Judge でスコアリングしているのだが、従来は を利用していたところを を利用するように。
- JDocQA:官公庁の公開資料などの、図表を含むPDF画像、多肢選択回答形式と自由記述回答形式
- 複雑図表ベンチマーク:独自に作成した日本語を含む模式図などの図表画像、自由記述回答形式
- 結果(ブログ本文参照)
- v.s. 日本語VLM
- Sarashina2-Vision-14B が基本強い
- 特に図表ドメインであるJDocQAや複雑図表で強い。
- Heron-Benchで14Bより8Bの方が強いんだ〜(まあ誤差かな)
- v.s. 日本語生成可能なオープンVLM(Qwenとかllavaとか)
- JMMMUやJDocQAではQwen2-VL-7B-Instructが強い。
- JMMMUの中でも日本文化カテゴリ(Art, Heritage, History)ではSarashina2が強い。
- Heron-Benchと複雑図表ではSarashina2-Vision-14Bが強い。
- 平均ランクはSarashina2-Vision-14Bが優勝
- 生成例(写真はブログ参照)
- Xでも見た人多いかもだが、写真から撮影場所当ててるのすごい
- 東京タワーと赤白クレーンを別で認識できていそうなのすごい。
- 図の読み取りも可能性を感じる。
@Shun Ito
[論文] LLM 推定ラベルと弱教師あり学習による 反復的アノテーション更新
- NLP2025
- 動機
- テキスト分類で、LLMアノテーションを使いたい
- 間違いが多く含まれるため、そのまま正解ラベルとして使ってしまうと、学習のノイズになる
- 弱教師あり学習の枠組みを使い、反復的にラベルを修正しつつ分類器を学習する手法を提案
- LLMでアノテーションした正例・負例データセットそれぞれを用意
- 仮定: 前者の方が、後者よりも正解データの割合は大きい
- 既存手法: Unlabeled-Unlabeled (UU) Learning
- 間違ったラベルのリスクを含めた損失
- a, b, c, dは「正解データの割合」から計算されるパラメータ
- b, cの負の項が大きくなりすぎて学習に悪影響することがある
- 既存手法: Robust UU Learning
- f = Leaky ReLU を使って負のリスクを過剰に低減しないよう調整
- 提案: Robust UU Learningを使って反復的に分類器を学習
- 現時点のアノテーションを使って、LLM分類器をRobust UU Learningで学習
- 学習したLLMで再度アノテーション


- 結果
- 分類器: Llama3.2-1B + affine layer
- 3種類のデータセットで、提案手法が最も安定して良い結果に
- 元のラベルを完全に信用して学習(PN)すると、最終的に良い結果にならない
- Ablation Study: 与える正解データの割合が精度に与える影響
- 訓練データのうち50, 100件のみ真のラベルを付与して、それを元に正解データの割合を計算
- 50, 100件でもfull annotationに近い精度が出る → 少量でも正しいアノテーションをしておけると有効


@qluto (Ryosuke Fukazawa)
[論文] Gemini Embedding: Generalizable Embeddings from Gemini
多言語かつ多様な問題設定において、既存のembedding手法を大きく上回った汎用性の高いもの

- Gemini LLMのパラメータによる強力な初期化
- Geminiは多言語・コード対応能力を持つ強力なLLMであり、その事前学習済みパラメータをそのまま初期化に使用。
- 従来のBERT/T5ベースのモデルよりもスケーリングベネフィットが大きく、強力な汎化性能を発揮。
- Geminiによる高品質な合成データ生成
- 分類・検索タスク用のデータをGemini自身が生成。
- 多段階プロンプト設計により、レビュー・感情・反事実データなど多様な合成分類データをゼロから生成。
- 実データを用いずに生成したにも関わらず、Geckoなどのin-domainモデルを超える性能
- Geminiによる自動データフィルタリング
- Geminiを用いた低品質データ(誤ラベル・ノイズ)の自動削除により、学習効率と性能を両立
- 特にretrieval系データで有効。
- Geminiによるハードネガティブマイニング
- Retrieval性能向上のために、Geminiを使って「似ているが不正解な文(hard negatives)」を自動選別
- RRF(Reciprocal Rank Fusion)でスコア統合し、最も難しいネガティブ例を使用。
- 適切な数(1〜3個)では性能向上(Figure 3)、多すぎると逆に過学習する傾向。
- モデルスープ(Model Soup)による汎化性能強化
- 複数のfine-tuningチェックポイントを単純平均(Model Soup)することで、過学習を抑えつつ性能向上
- 同一訓練ラン内・別ラン間の平均を比較し最適構成を選定。
- MRL(Matryoshka Representation Learning)対応による多次元最適化
- 埋め込みを複数次元(768, 1536, 3072)で同時最適化することで、多様なアプリケーションへの転用が容易。
- 一つのモデルで複数の次元に最適化可能
- Pre-finetuningによるパラメータ最適化
- 大規模Webコーパスで事前fine-tuning(Pre-finetuning)を行い、自己回帰型LLMからエンコーディング型モデルへの適応を促進
- ノイズが多いペアでも大規模バッチサイズとシンプルな損失で対応。
@Yosuke Yoshida



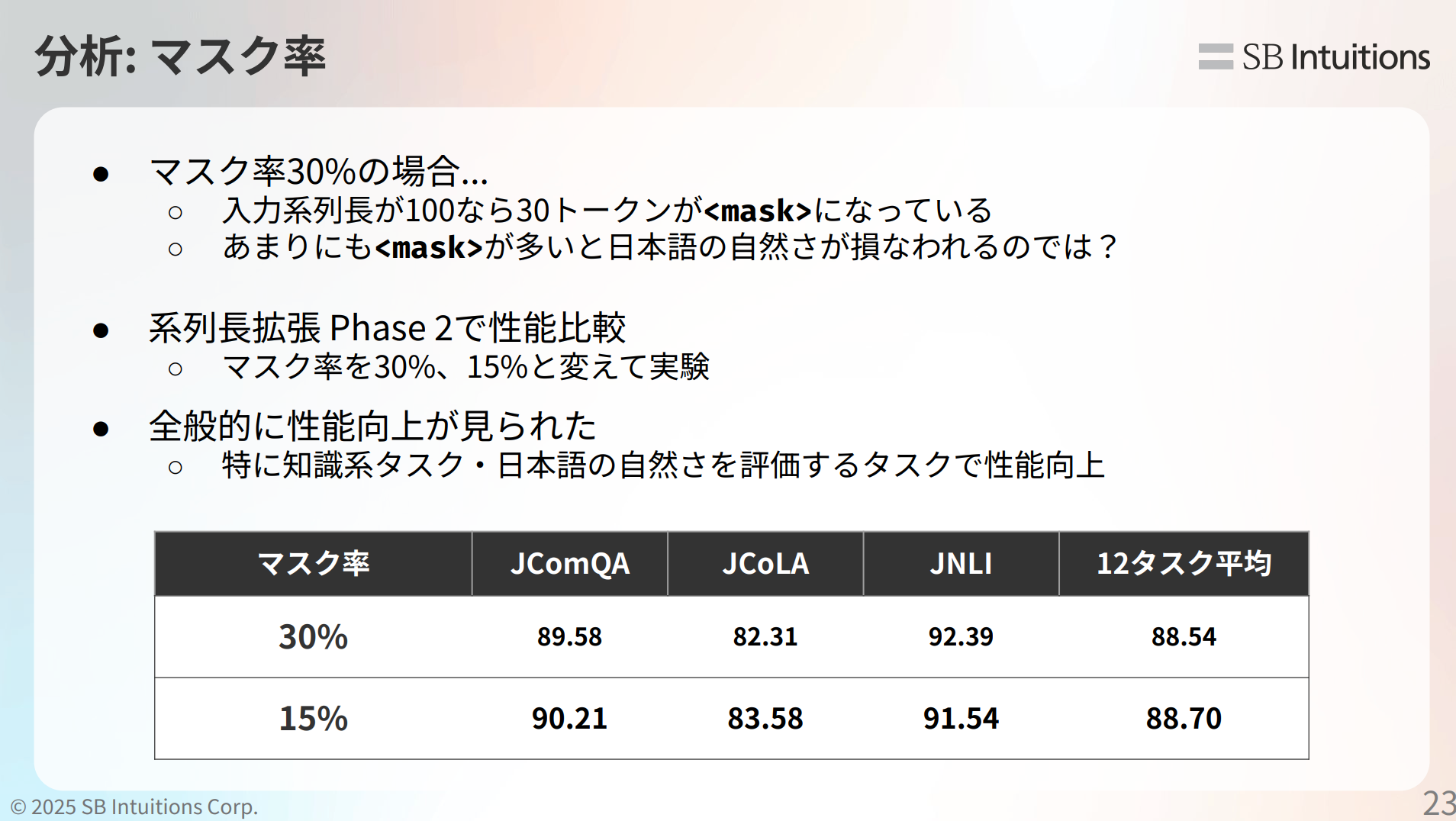

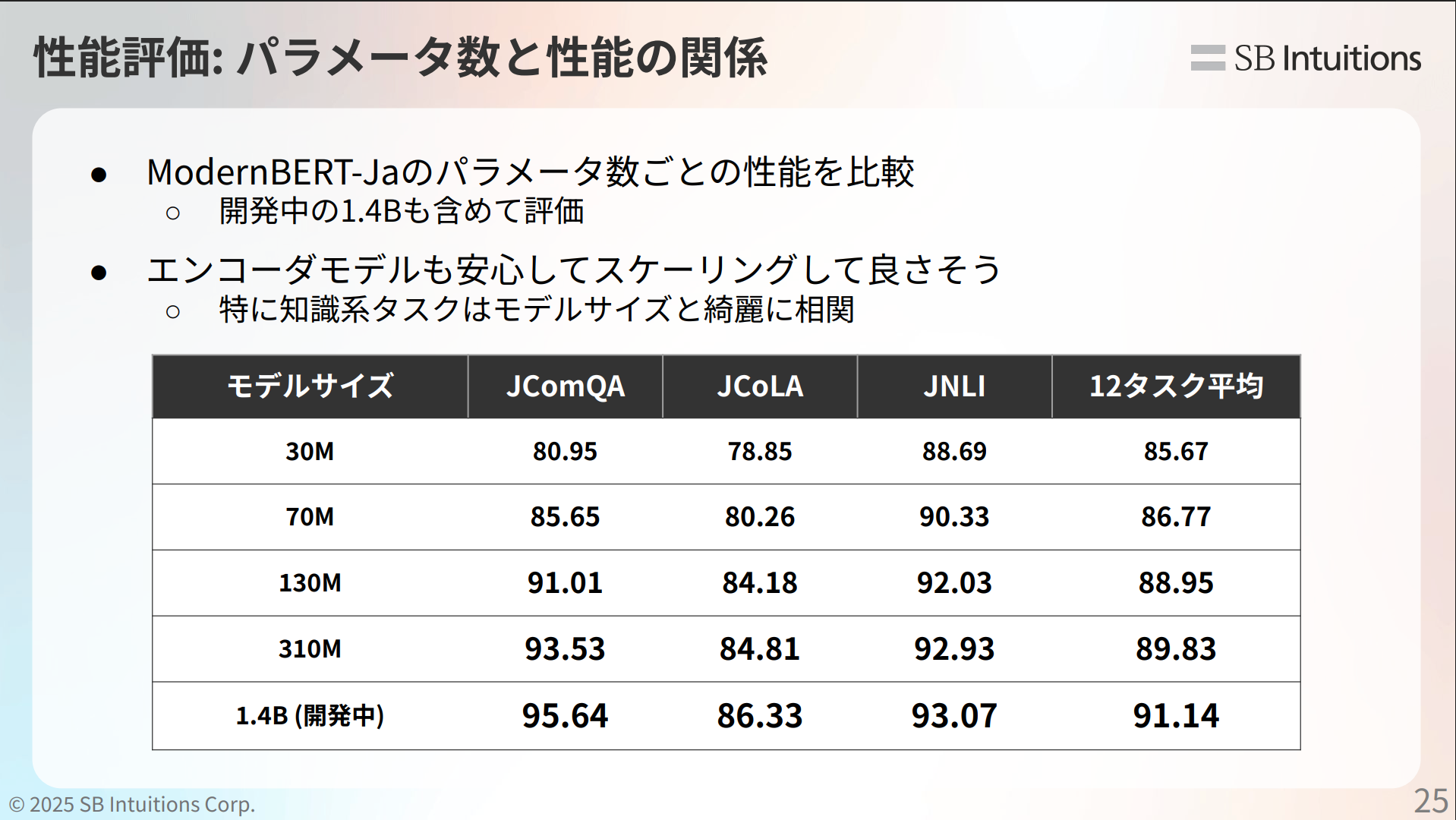

メインTOPIC
Juraj Gottweis, Wei-Hung Weng, Alexander Daryin, Tao Tu, Anil Palepu, Petar Sirkovic, Artiom Myaskovsky, Felix Weissenberger, Keran Rong, Ryutaro Tanno, Khaled Saab, Dan Popovici, Jacob Blum, Fan Zhang, Katherine Chou, Avinatan Hassidim, Burak Gokturk, Amin Vahdat, Pushmeet Kohli, Yossi Matias, Andrew Carroll, Kavita Kulkarni, Nenad Tomasev, Yuan Guan, Vikram Dhillon, Eeshit Dhaval Vaishnav, Byron Lee, Tiago R D Costa, José R Penadés, Gary Peltz, Yunhan Xu, Annalisa Pawlosky, Alan Karthikesalingam, Vivek Natarajan
Google Cloud AI Research, Google Research, Google DeepMind, Houston Methodist, Sequome, Fleming Initiative and Imperial College London, Stanford University School of Medicine
概要
科学研究における新規仮説生成を支援するための「AI共同科学者(AI co-scientist)」システムを提案した論文。
gemini 2.0 を使ったマルチエージェントアーキテクチャによって構成されている。このシステムのための学習は行っておらず、特に重要な推論部分での性能をあげるために test-time scaling が利用されている。
1. Introduction
本研究の主な貢献
- AI共同科学者の導入
- 単なる文献要約や「高度なリサーチ」ツールを超えたAI共同科学者を開発・導入した
- 新たな知識の発見、独創的な仮説の生成、実験計画の策定を支援するもの
- 科学的推論のためのテスト時計算パラダイムの大規模拡張
- Gemini 2.0のマルチエージェントアーキテクチャ上に構築され、非同期タスク実行フレームワークを活用している。
- システムは科学的推論のために計算資源を柔軟に割り当てることができ、科学的方法の重要な側面を再現する。
- 具体的には、科学的議論やトーナメント形式の進化プロセスを含む自己対戦戦略を活用し、仮説や研究提案を反復的に洗練する自己改善型のループを構築している。 (いわゆる test-time scaling)
- さらに、専門家が選定した15の複雑な科学課題に対する自動評価を行い、AI共同科学者が他の最先端(SOTA)のエージェントや推論モデルを上回る高品質な仮説を生成できることを実証した。
- 専門家と連携する科学ワークフロー(Expert-in-the-loop)
- 科学者との協働を前提に設計されている。
- 科学者は自然言語による対話型フィードバックを柔軟に取り入れることができ、共同でアウトプットの開発、進化、洗練を行える。
- バイオメディシン分野におけるAI共同科学者のエンドツーエンドの検証
- バイオメディシンにおける重要なテーマに関して、AIが生成した新規仮説をエンドツーエンドで検証した。具体的には、以下の3つの複雑性の増す分野で新たな知見を得た
- 薬剤再利用(ドラッグリポジショニング):AML(急性骨髄性白血病)に対する新規再利用薬を予測
- 新規標的の発見:肝線維症に対する前臨床エビデンスに基づいた新規エピジェネティック治療標的を特定
- 抗菌薬耐性:細菌の進化と抗菌薬耐性における遺伝子移行の新たなメカニズムを提

2. 関連研究
- 2.1 推論モデルとテスト時計算のスケーリング
- 事前学習技術の進歩によってLLMは画期的なパフォーマンスを発揮している
- 推論能力の強化が重要な課題となっているが、それに対応する有望な方向性のひとつに test-time compute パラダイムがある。事前学習によって獲得した知識に依存するだけではなく、推論時に追加の計算資源を与えることで熟考による推論を可能にし、不確実性を減らしながら最適な目標達成を目指すもの
- 最近では Deepseek-R1のように、強化学習を活用してchain-of-thoughtを洗練させ、より長期的な複雑な推論能力を向上させる手法も登場している
- 本研究では、科学的方法に基づく帰納的バイアスを活用したマルチエージェントフレームワークを設計することで、追加の学習手法を用いることなく、科学的推論や仮説生成を可能にすることを提案している
- 2.2 AIによる科学的発見
- (この機械学習勉強会の趣旨とやや遠い話題なので、本手法と関連の強いものだけをピックアップ)
- Boikoらの「Coscientist」は、GPT-4を活用して化学実験を自律的に遂行するマルチエージェントシステム
- ウェブ検索やコード実行の機能を統合し、独立した実験計画の立案や実施を可能にしている
- しかし、このシステムは化学分野に特化しており、私たちのシステムのように幅広い科学領域に適用可能なものではない。また、Coscientistは、研究の自律的な実行を重視しており、実験機器との直接的な連携を前提としている
- 私たちのシステムは「科学者との協働」を目的とし、研究プロセスの認知的側面に重点を置いている
- Luらの「The AI Scientist」は、研究課題の定義から文献調査、実験設計、結果の記述までを担う完全自動化された研究システム
- このシステムは私たちのアプローチと類似点を持つが、私たちは特にテスト時計算のスケーリングに焦点を当て、高品質な仮説や研究提案の生成を重視している。
- また、彼らのシステムは自動評価が限定的であるのに対し、私たちは自動評価、人間の専門家による評価、実験室での検証を組み合わせた包括的な評価を行っている。
- 私たちの最終的な目標は科学的発見の完全自動化ではなく、科学者を支援するAIの共同研究者を構築することである
- 2.3 バイオメディシンにおけるAIの活用
- GPT-4やGeminiのような汎用LLMだけでなく、Med-PaLM、Med-Gemini、Galactica、Tx-LLMといった専門特化型LLMも、バイオメディシンにおける推論や質問応答のベンチマークで優れた性能を示している。
- バイオメディシンにおけるAIは通常、特定分野に特化することが求められるが、最先端AIモデルの急速な進化により、この境界が曖昧になりつつある。モデルの規模が拡大し、学習データの多様性と複雑性が増すにつれて、これまで専門AIでなければ不可能と考えられていた領域でも、画期的な成果が得られるようになった。
- 本研究においては、薬剤再利用を重要な検証対象としている。従来、これには計算的手法と実験的手法の両方が必要であり、疾患と薬剤の相互作用に関する包括的な理解が求められてきた。知識グラフとグラフ畳み込みネットワーク(GCN)を用いた手法は有望視されているものの、初期の知識グラフの範囲に依存するため、適用範囲が限られるという課題がある。
- 最先端のLLMを活用し、よりスケーラブルな手法を実現している。本研究では、専門家による評価とウェットラボ実験を組み合わせた検証を実施し、システムの予測精度を評価する
3. Introducing the AI co-scientist
3.1 The AI co-scientist system overview
ハイレベルでは下記のコンポーネントを備えている。また、Gemini 2.0を基盤となるLLMとして採用し、全てのエージェントがこのモデルを活用している。
- Natural language interface
- サイエンティストは自然言語でリサーチゴールを定義し、リファインし、どんなタイミングでもフィードバックを行える
- Asynchronous task framework
- 監督者エージェントがタスクキューを管理し、専門エージェントをアサインする非同期処理を基本としている
- Specialized agents
- 科学的方法に基づく帰納的バイアスと科学的な先行知識を活用し、科学的推論や仮説生成のプロセスを細かいサブタスクに分割する。それぞれのサブタスクは、特定の指示(プロンプト)に最適化された専門エージェントによって処理される。
(難しい言葉で書いてあるが、科学的方法の効果的なやりかたをマルチエージェントにあったタスク設計に落とし込みましたという話)
- Context memory
- 長期的な科学的推論と反復的な計算を可能にするために、コンテキストメモリを活用している。
3.2 From research goal to research plan configuration
- 研究目標
- 科学者が設定する研究目標は、AI共同科学者システムの出発点となる。
- このシステムは、Gemini 2.0モデルのマルチモーダル能力と長文コンテキスト処理機能を活用し、単純な研究目標の記述から、数万トークンに及ぶ詳細な文書、さらには数百件の関連論文PDFなどの多様なデータを効率的に処理する。
- 研究目標には、特定の研究室環境や専門分野に関連する制約、属性、優先事項も組み込むことができる。
- 研究計画
- システムはこの研究目標を解析し、それに基づいた研究計画の構成(research plan configuration)を生成する。
- 研究計画の構成には、提案する研究内容の種類や基準、制約条件が含まれる。
- 例えば、システムが完全に新規の仮説のみを提案すべきかといった指示や、仮説の評価基準(新規性、実験の実現可能性など)も設定できる。
- これらの評価基準は、システムが自動評価や改善フェーズで活用するため、研究目標ごとに柔軟にカスタマイズが可能である。
3.3 The specialized agents underpinning the AI co-scientist

監督者エージェント(Supervisor agent)によって調整される複数の専門エージェントがAI co-scientistの中核
- 生成エージェント(Generation Agent)
- 研究プロセスの起点として、研究の焦点領域を設定し、研究目標に応じた初期の仮説や提案を生成する。この過程では、関連文献を探索し、既存の知見を統合して新たな方向性を示すだけでなく、科学的議論をシミュレートすることで、仮説の精度を向上させる。
- 文書検索の機能、自己批判や自己対戦を活かした複数回のプロセスなどを持つ
- 省察エージェント(Reflection Agent)
- 科学論文の査読者の役割を模倣し、生成された仮説や研究提案の正確性、品質、新規性を批判的に評価する。また、仮説が既存の研究結果(文献調査で特定された知見)にどの程度適合し、特に十分に説明されていない観察結果に対する改善された説明を提供できるかを検証する。
- 仮説の検証ステータスにあわせた複数のレビュー手法を持ち、使い分ける
- ランキングエージェント(Ranking Agent)
- トーナメント形式による研究提案の評価が重要な手法となっている。このエージェントは、Eloレーティングを用いたトーナメントを実施し、生成された仮説を評価・ランク付けする。仮説同士をペアで比較し、シミュレーションされた科学的議論を通じて、それぞれの提案の相対的な価値を詳細に評価する。
- Eloレーティングベースのトーナメント方式とは、「対戦結果に応じてプレイヤーの実力(レーティング)を更新しながら、より公平・効率的にマッチングや順位付けを行うトーナメント方式
- 近接エージェント(Proximity Agent)
- 非同期に生成された仮説の近接グラフ(プロキシミティ・グラフ)を計算し、類似したアイデアのクラスター化、重複の排除、仮説空間の効率的な探索を可能にする。
- 進化エージェント(Evolution Agent)
- 仮説改善機能の中核を担うエージェントであり、トーナメントで上位にランク付けされた仮説を継続的に洗練する。具体的には、以下の戦略を用いて仮説を改良する。
- 既存のアイデアの統合
- 類推(アナロジー)を用いた新たな発想の導入
- 文献の活用による補強
- 従来のアプローチにとらわれない独創的な推論
- 明確な理解を促すための概念の単純化
- メタレビューエージェント(Meta-Review Agent)
- 継続的な改善を支援するエージェントであり、以下の役割を果たす。
- すべてのレビューを統合し、主要な知見を抽出
- トーナメント議論のパターンを分析し、他のエージェントの性能向上に活用
- 次の反復での仮説やレビューの質と関連性を高める
- トップランクの仮説やレビューを統合し、科学者が評価できる包括的な研究概要を作成
監督者エージェントは下記例のように専門エージェントを動作させる
- Generationエージェントが研究目標を満たす仮説の初期リストを作成
- Reflectionエージェントがそれを査読
- Rankingエージェントがトーナメント形式で仮説を評価し、順位付け
- Evolution、Proximity、Meta-reviewエージェントがトーナメントの進行状況をもとに仮説の改良を行い、システムの出力品質を向上させる。
また、監督者エージェントは下記のような包括的統計情報をコンテキストメモリに書き込み管理する
- 生成された仮説の数
- レビューが必要な仮説の数
- トーナメントの進行状況
- 仮説生成の手法ごとの有効性の分析(例:Generationエージェントによる新規アイデア生成 vs. Evolutionエージェントによる既存アイデアの改善)
特に重要なのは、メタレビューエージェントによるフィードバックの伝播である。本システムでは、ファインチューニングや強化学習といった従来のバックプロパゲーション技術を用いることなく、学習と改善を実現している。
メタレビューエージェントが生成したフィードバックは、各エージェントのプロンプトに追加される形で次の反復に反映され、Gemini 2.0の長文コンテキスト処理能力を活かしてシステム全体の推論精度を向上させる。このフィードバックループによって、計算資源のスケーリングに応じてAI co-scientistは継続的に学習し、改善されていく。
3.4 Expert-in-the-loop interactions with the co-scientist
科学者は、以下の方法でAI co-scientistと対話し、研究プロセスを調整できる。
- 研究目標の洗練(Refining the Research Goal)
- 生成された仮説や研究概要を考慮しながら、研究目標を柔軟に調整する。
- 初期設定した研究目標の範囲を広げたり、特定の方向性に絞り込んだりすることが可能。
- 仮説の手動レビューの提供(Manual Reviews of Hypotheses)
- 科学者はReflectionエージェント(3.3.2参照)による自動レビューに加えて、独自の専門的見解を反映したレビューを提供できる。
- 人間のレビューを活用することで、AI co-scientistは仮説や研究提案の評価・改善をさらに洗練する。
- 科学者自身の仮説や提案のトーナメント参加(Contributing Their Own Hypotheses and Proposals)
- 科学者は、自身の仮説や研究提案をトーナメントに追加し、AIが生成した仮説と並べて評価できる。
- 科学者の仮説とAIの仮説を組み合わせることで、より強力な研究提案を生み出せる。
- 特定の研究方向へのフォーカス指示(Directing Research Focus)
- 科学者は、AI co-scientistに対して特定の研究領域や参考文献に基づいた探索を指示できる。
- 例えば、「過去の特定の論文群に限定して研究を進める」ような制約を設けることで、特定の分野の知識を活かした仮説生成が可能となる。
- 研究目標に特定の文献を明記すると、AIはそれを優先的に参照し、統合する仮説生成手法を選択する。
3.5 Tool use in AI co-scientist
オープンデータベースなどのドメイン固有ツール、科学者が指定するプライベートな論文リポジトリ、AlphaFoldのような専門AIモデルのフィードバックなどから情報を得るように構築されている
4. Evaluation and Results
- Eloレーティングのスコアが高ければ高いほど正しい回答を得る可能性が高くなっているかを確認した
- GPQAベンチマークデータセット(生物学・物理学・化学の専門家によって開発された、難易度の高い多肢選択式質問応答ベンチマーク)の中でも特に難易度が高いとされる「GPQAダイヤモンドセット」により評価。
- 素のGemini 2.0に32回応答を生成させた時の平均正答率をベースラインとし、Eloレーティングを使った応答の正答率を測定し、Eloレーティングと正答率には一致性がみられることが確認できた。

- test-time scalingが性能を上げているのかを確認した

- その他出力結果が人間の科学者から見てどのように評価されうるかというような話を多方面から展開しているが、やや専門性(化学)が高い話なので割愛
5 Limitations
- オープンアクセス文献に依存しているため、
- 重要な先行研究を見落とす可能性がある
- 否定的な実験結果や失敗した研究データにアクセスできる可能性が低い
- 科学論文の最も重要なデータの一部はテキストではなく、図やグラフとして示されているが、ドメイン特化型のマルチモーダルデータセットから情報を統合して推論する能力は未評価であり、今後の課題である。
- 既存のLLMやWeb検索に依存しているため、それらのソースに含まれる誤情報やバイアスを引き継ぐ可能性がある。
- Eloレーティングは自己改善のための評価指標として有効だが、自動評価としての限界があり、より客観的で専門家の視点を反映できる評価指標の開発が求められる。
6 Safety and Ethical Implications
(重要な話ではあるが提案手法の内容とは離れた話なので、ここでは割愛)
7 Future Work
- 即時的な改善点
- 文献レビューの強化
- 外部ツールとのクロスチェック
- 事実検証の向上
- 引用の網羅性向上
- 一貫性チェック
- 評価手法の拡張
- 自動文献ベースの検証
- シミュレーション実験の導入
- LLMに起因するバイアスの軽減
- エージェントの最適な組み合わせ分析
- 能力の向上
- 強化学習
- データの多様化(テキスト中心の評価を拡張)
- 実験デザインの高度化(より複雑な実験設計、ラボとの接続による仮説の実験検証の自動化など)
- ユーザーインターフェースの改善(フリーテキストだけではないフィードバックを受け取れるように)
8 Discussion
(重要な話ではあるが提案手法の内容とは離れた話なので、ここでは割愛)
9 Conclusion
多様な科学・生物医学分野にわたって新規かつ検証可能な仮説を生成し、その一部は実験的な裏付けを持っている。また、計算リソースの増加に伴って自己改善を繰り返す能力も備えており、これは人類の健康・医療・科学における大きな課題解決を加速する力を持っていることを示している。
人間中心かつ協調的なAIシステムが、人間の創造性を拡張し、科学的発見のスピードと質を高める未来に向けた基盤が、今まさに築かれつつある。
Note: 具体的なプロンプトやその結果は付録として論文に大量に添付されているので、興味があれば。