
2025-04-04 機械学習勉強会
今週のTOPIC[OSS] trustcall[blog] 検索失敗から学ぶUX改善の旅 ~ データドリブンなユーザー体験向上の事例をご紹介 ~[blog] Improving Recommendation Systems & Search in the Age of LLMs[論文] Survey on Evaluation of LLM-based Agents[doc] Model Context Protocol QuickStart[論文] VGGT: Visual Geometry Grounded TransformerメインTOPICTableLlama: Towards Open Large Generalist Models for TablesAbstractIntroductionTableInstruct BenchmarkData CollectionTask Formulation and Challenges Experimental SetupResult AnalysisIn-domain ResultsOut-of-domain ResultsAblation StudyRelated WorkTable Representation LearningInstruction TuningRandom Thoughts
今週のTOPIC
@Naoto Shimakoshi
[OSS] trustcall
- LLMの構造化データ出力を改善するライブラリ
- JSON Patchを複数回行うことで解決。Pydanticなどでの定義にも対応。
- こんな感じにかける
- before
- スキーマ
- after
- スキーマの更新とかもできる
- 普通にやると既存のスキーマの値がなくなってしまったりした
@Yuya Matsumura
[blog] 検索失敗から学ぶUX改善の旅 ~ データドリブンなユーザー体験向上の事例をご紹介 ~
- NewsPicksでの検索体験をどのように改善しているかについてのブログ
- 検索ワードごとに”検索の失敗”(コンテンツを開かずにアプリから離脱)率をモニタリングし、対応を練っている。
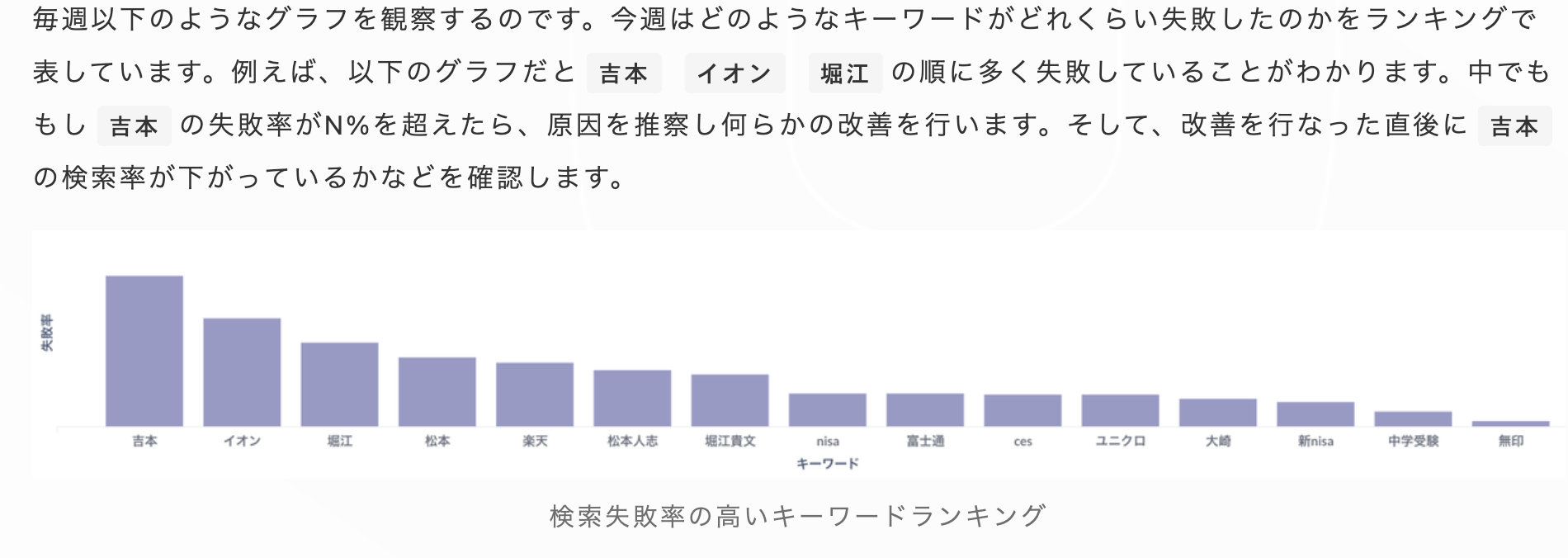
- プッシュ通知やサムネイル画像を見た後で検索してくれているユーザーのことを想像して検索システムを作ろうぜという話。マーケなどとの連携も大切。
- 以下ブログのまとめより引用
- 失敗パターン① プッシュ通知文言で探せない
- 取り組み① DBに「検索用キーワード」を設け、検索にヒットさせる
- 取り組み② 検索の最初の段階に見せる「検索ホーム画面」を作り、通知済みコンテンツを検索しなくても探せるようにする
- 失敗パターン② サムネイル画像のテキストで探せない
- 取り組み① コンテンツ制作チームが手動で「検索用キーワード」を登録し、検索にヒットさせる
- 失敗パターン③ 人気のある古いコンテンツが探せない
- 取り組み③「公開してからの経過日数」と「人気度合い」をバランスよく考慮したランキングロジックにする
@Shun Ito
[blog] Improving Recommendation Systems & Search in the Age of LLMs
- LLM x 推薦・検索のサーベイ記事
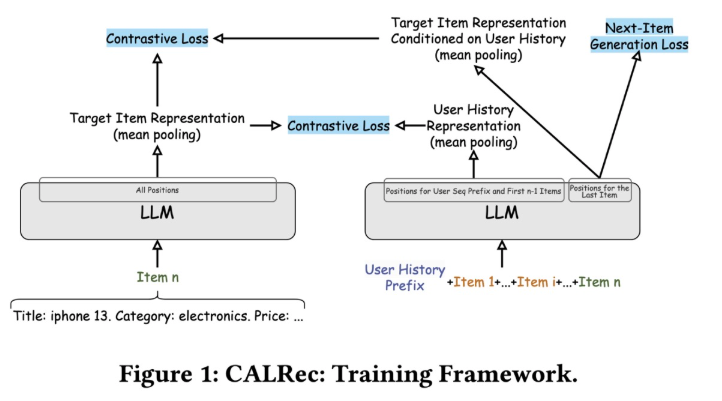
- CALRec: LLMを逐次的な推薦向けにfine-tuning
- マルチモーダルな情報をテキストの属性情報として渡してしまう
- 学習時は、ユーザーのhistoryから次のアイテムをテキストで生成しつつ、そのアイテムのrepresentationが別のLLMから出たitem representationと近づくようにする
- 推論時は、候補を複数生成し、BM25で実際のカテゴリとマッチさせて推薦
- Amazon Review Dataset 2018で既存のID-based・text-basedを上回ったらしい

- Yelpの事例
- 検索のQuery UnderstandingにLLMを利用
- Query segmentation: クエリを意味のある要素に分割(同時にtypo修正も入れる)
- Review highlights: レビューの中からクエリと関連性のある部分をハイライト
- 検索精度の改善 & ハイライトでCTR改善

- Amazonの事例
- playlistのdescription生成、query-playlistのペアとそのpos/negラベル付け、学習後の評価でLLMを利用

@qluto (Ryosuke Fukazawa)
[論文] Survey on Evaluation of LLM-based Agents
the first comprehensive survey of evaluation methodologies for these increasingly capable agent と謳っていたのでチェックしてみた。

- 主だったベンチマーク、リーダーボード、評価方法、評価のためのフレームワークなどが並べられている
@Yosuke Yoshida
[doc] Model Context Protocol QuickStart
- 天気予報の結果を返すMCPサーバをFastMCPで実装するチュートリアル
- MCPクライアントは手元でClaude for Desktop使えばさくっと試せる
- Anthropic API Keyが必要なMCPクライアントの方は課金が必要だった・・
@Takumi Iida (frkake)
[論文] VGGT: Visual Geometry Grounded Transformer

- 読んだモチベ:アニメ画像でやってみてる動画を見てみて、凄そうだと思ったのでシェア
- 概要
- 単一画像、少数枚画像、多数枚画像のいずれかの入力から、多くの3D情報を抽出するVGGTを提案。一発で、カメラパラメータ、点群マップ、深度マップ、3Dトラッキングができる。
- 超高速。1msec以内で全部出せる
- ‣
- 手法
- 学習可能なカメラトークンおよびレジスタトークン(もろもろの出力をするためのトークン)を各画像トークン先頭にくっつけて特徴抽出器に入力
- 特徴抽出機
- Global Attention 画像間でアテンション(マッチング的なことをしてる)
- Frame Attention フレーム内でアテンション
- 出力
- Camera Head カメラパラメータを推定
- DPT
- 深度マップ
- 点群マップ
- トラッキング
- 学習データ
- 一覧 Co3Dv2 [88], BlendMVS [146], DL3DV [69], MegaDepth [64], Kubric [41], WildRGB [135], ScanNet [18], HyperSim [89], Mapillary [71], Habitat [107], Replica [104], MVS-Synth [50], PointOdyssey [159], Virtual KITTI [7], Aria Synthetic Environments [82], Aria Digital Twin [82], Objaverse [20]
- GT座標の正規化
- 結果
- カメラ姿勢推定の定量評価。速い。
- 推定された点群マップを使って、単一画像で3次元再構成をした結果。
- 入力枚数に応じた計算速度と使用メモリ量




- 読みたくなった論文
- DUSt3R
- CoTracker2
メインTOPIC
TableLlama: Towards Open Large Generalist Models for Tables
Tianshu Zhang, Xiang Yue, Yifei Li, Huan Sun
NAACL 2024
Abstract
- Geminiに生成させたまとめ (たまに論文に書いてないこと書いたりするので、自分でHTML修正する必要あり)

半構造化テーブルは普遍的に存在し、その解釈・補強・クエリに関する様々なタスクがある。従来手法は特殊な事前学習やアーキテクチャを必要とし、特定のテーブルタイプや単純化された仮定に限定されていた。本研究では、多様なテーブルタスクに対応するオープンソースLLMの開発を目指す。
我々はInstruct Tuning用のデータセットを構築し、Llama 2 (7B)をLongLoRAで微調整してを開発した。8つの領域内タスクのうち7つでSOTAと同等以上の性能を達成し、6つの領域外データセットでは5-44ポイントの改善を示すことでTableInstructの重要性を示した。
データセットとモデルはオープンソースとして公開し、今後の研究発展を促進する。

Introduction
- テーブルベースのタスクの既存手法は以下の少なくとも一つの制限を加えている。
- テーブルの事前学習 or テーブルのための特別なモデルアーキテクチャ
- テーブルとタスクの限られた特定のタイプのサポートのみ
- テーブルとタスクについて強い単純化仮定を置いている
- 一方でFlan-T5のような言語モデルは構造化された知識と言語を紐づかせるのに優れていることがわかっている。
- また、Instruction Tuningもさまざまなタスクを完了するために命令に従わせる重要な技法である
- これらの背景から本研究ではLLMとInstruct Tuningを用いることで、さまざまなテーブルベースのタスクを処理するジェネラリストモデルを構築できるのか?という問いに答えていく。
- 多様なテーブルベースのタスクでうまく機能するだけでなく、未知のタスクにも汎化できるか
- 新しいテーブルのデータとタスクは新しい情報が到着すると動的に構築されるため、すべてのタスクとすべてのデータをカバーする学習データを収集することは困難
- 実世界のテーブルや現実的なタスクで動作する。
- 上記の課題を解決するために包括的なデータセットがないため、広くデータセットから代用的なテーブルベースのタスクを集めてきて手動で命令をアノテーションすることでを構築した。
- In-DomainとOut-of-Domainで12タスクと14のデータセットを持っている。
- 学習データには8つのタスクと8つのデータセット。
- 評価データには6つのデータセットと学習に含まれない(Out-of-Domain)4つのタスク
- Out-of-DomainにはTable QAやセル記述などより高度な推論能力を必要とするタスクを選択する
- 単純化された合成データではなく実世界データセットを用いる。
- 統計科学レポートと多数のWikipedia table、Freebaseなどの現実的で複雑なテーブル。
- 階層的なテーブル構造を持つ複雑な数値推論タスクなども

- TableInstructはロングコンテキストに対応できるモデルが必要なため、backboneとして Llama2に基づくLongLoRAを採用。
TableInstruct Benchmark
- モデルの特別な設計をすることなしに、すべてのテーブルベースのタスクに対応できる1つのジェネリストモデルを作成するために、以下のようなことを遵守している。
- taskとテーブルの種類を多様化する。taskとしては異なる能力が必要になる表の解釈、表の補強、表のQA、表の事実検証などのtaskを用いる。
- 現実的なタスクを選択し、仮定を置いて単純化せずに高品質なInstructionデータセットを構築する。
Data Collection
TableInstructのデータセット構成
- 11の特徴的なテーブルベースのデータセット(表1)を使
- 8つのタスク:学習・In-Domain評価用データセット
- 4タスク:Out-of-Domain評価用データセット(6つのデータセット)
タスクのカテゴリー
- テーブルの解釈 (Table interpretation):データの意味属性を機械的に理解しやすい知識に変換
- テーブル補強 (Table augmentation):追加データによる部分テーブルの拡張
- 質問応答 (Table QA):テーブルを証拠として回答を生成。ハイライトされたセル、またはpassageを抽出することを目的とする
- 事実検証 (Fact Verification):テーブルによって主張を支持、または反証すること
- 対話生成 (Dialogue Generation):テーブルと対話履歴からの応答生成
- Data-to-text:ハイライトセルからの説明生成
In-Domainタスク(8種類)
列タイプアノテーション
- 候補の中から選択させる

関係抽出
- name, partyの関係性を候補から選択させる

Entity Linking
- テーブル内の「highest club」という列に「Melbourne Victory」というエンティティがあり、それがどういうエンティティかを知識の中の候補と繋げる

行追加 (Row Population)
- カラムの意味を理解して、候補の集合が行として追加できるかを判断する

スキーマ拡張
- Tableの注釈と一つのヘッダーが与えられて、候補のヘッダーを並び替えるタスク

階層型テーブルQA
- 与えられた表に基づいて与えられた質問に答える
- 下の例では数値計算が必要な質問をしている。

ハイライトセルQA

テーブルファクト検証
- Tableの内容に基づいて質問が正しいのかどうかを答える

データセットの特徴
- Freebase:複雑な意味タイプと関係タイプを含む
- Wikidata:豊富なメタデータを持つエンティティ
- 階層テーブル:多層構造と数値推論タスク
Out-of-Domainデータセット(6種類):
- HybridQA (Chen et al., 2020b)
- KVRET (Eric et al., 2017)
- FEVEROUS (Aly et al., 2021)
- ToTTo (Parikh et al., 2020)
- WikiSQL (Zhong et al., 2017)
- WikiTQ (Pasupat and Liang, 2015)
Task Formulation and Challenges
- 下の図のように、3つのコンポーネントに全てのタスクをマッピングして扱えるようにした。
- <命令、表入力、質問>
- 課題
- テーブルの長さが数行から数千行まで様々ある。
- 多岐選択肢型の分類やランキングを行うタスクでは、候補自体が数千まで非常に大きくなることがある。さらに、各候補は のように長いこともある。
- そのため、長いコンテキスを扱うモデルが必要になる。

Experimental Setup
- 既存のLLMでいくつかは4k以上のコンテキストを扱えるがその学習時間はコンテキストの長さに対して2次関数的に増加する。LongLoRAはを使うことで、効率的に学習を行える。
- Shift short attentionはコンテキストをいくつかのグループに分割してグループごとにAttentionを行う。グループ間の情報も伝達するために半分のグループサイズだけシフトさせる。
- LongLoRAはグループサイズ2048で8196コンテキストの学習を行うことができる。
- 既存のSoTAモデル
- 事前学習 or 特化型モデルアーキテクチャを持ってるもの
- 評価指標
- タスクに応じてMicro F1スコア、ACC、MAP、execution accuracy、BLEUなどを用いる。
- 訓練と推論の詳細
- LongLoRA 7Bを完全にFine-tuningしたものをベースライン
- batch_size 3でA100 x 48で学習
- Zero-2ステージを使って入力は8192とした
- クローズドLLM
- gpt-4-1106-preview
- gpt-3.5turbo-1106
Result Analysis
In-domain Results
- ベースライン を大幅に上回る性能。
- 8タスク中7タスクでタスク特化SOTAモデルと同等以上の性能を達成。
- 特にテーブルQA、要約、データ操作タスクで強力な性能を発揮。
- タスク特化設計なしで、単一モデルが高い汎用性能を持つことを実証。

Out-of-domain Results
- 6つの外部公開データセットで汎化能力を評価。
- ベースのLlama 2モデルに対し、平均+20ポイント以上(5〜44ポイント) の大幅な性能向上を確認。
- TableInstructでの多様なタスク学習が、未知のデータへの汎化能力向上に寄与。
- WikiTQ, FeTaQA (QA), ToTTo (Text Gen) などで顕著な改善。
- SOTAには流石に学習もしてないので及ばず

Ablation Study
- TableInstructデータセット内のタスク多様性の影響を分析。
- 全8タスクで学習させたモデルが、全体として最良の性能を示す。そのタスクだけで学習させても微妙。
- タスク数を減らして学習すると、学習に含まれなかったタスクの性能が低下。
- 汎用的なテーブル処理能力の獲得には、多様なタスクに関するインストラクション学習が重要。

Related Work
Table Representation Learning
- , , , Table position encodingなどテーブル特化の事前学習モデル (Attention)が存在。
- TURL: Structure-aware attention
- TUTA: tree-based attention
- TaBERT: vertical self-attention
- 多くはテーブル固有の特殊なアーキテクチャや事前学習目的を持つ。
- 大規模なテーブルコーパスでの事前学習を必要とする。
- 多くは、特定のデータだけに特化したり特定のタスクだけに特化している。
- 合成データでGPT-3.5をFine-tuningするという研究もある。
- という似たアプローチで汎用性を持たせる研究はあるが、それはDBや知識グラフ、Web Tableなどの異なる知識ソースを用いることで解決しようとしており、Instruct Tuningに焦点は当てていない。
Instruction Tuning
- ClaudeなどでもInstruct Tuningモデルは事前学習済みモデルより優れているという話は出てきている。
- LLMがテーブルベースのタスクを完了するように、命令チューニングをどのように利用するかは、まだ十分に研究されていない。
Random Thoughts
- 業務とかでタスクを幅広く解かせたいとかでなければ普通にInstruction Tuningしてタスク特化モデル作るのがいい気がする。
- GPT-4とか普通にあまり解けてない。目指すはSOTAか。
- Instruct Tuningデータセットの書き方とかは参考になる。