
2025-04-08 機械学習勉強会
今週のTOPIC[blog] ハルシネーションを制する者がAIを制する:幻覚対策の最新テクニック集[paper] PaperBench: Evaluating AI's Ability to Replicate AI Research[論文] WebLLM: A High-Performance In-Browser LLM Inference Engine[論文] Multi-Token Attention [blog] 画像に対する自己教師あり表現学習手法について(2記事)FFN Fusion: Rethinking Sequential Computation in Large Language ModelsAIによる3行まとめIntroductionPreliminariesFFN FusionProducing Large-Scale Models with FFN Fusion
今週のTOPIC
※ [論文] [blog] など何に関するTOPICなのかパッと見で分かるようにしましょう。
出典を埋め込みURLにしましょう。
@Naoto Shimakoshi
[blog] ハルシネーションを制する者がAIを制する:幻覚対策の最新テクニック集
- ハルシネーションを防ぐための手法をまとめた記事
- ハルシネーションの要因
- トレーニングデータの限界
- トレーニングデータに存在しない情報に対して「創作」してしまう。
- パラメータの不確実性
- パラメータが完璧に調整されていないため、特定の入力に対して予測できない出力が生成される (?)
- 確率的生成プロセス
- 知識の不確かな領域で起きやすい
- Context-Windowの制限
- 忘れてしまうことで一貫性のない回答になる
- 技術トレンドの概観
- ブログにそれぞれの手法について詳細な手法が書かれているが、そこまで真新しくはない。
- 面白そうなもの
- セマンティックグラウンディングスコア:出力分の各部分に対して、どの程度事実に接地してるかを示すスコアを付与
- Counterfactual Debating:AIに意図的に異なる立場をとらせ、複数の視点から検証させる
- マルチモーダルグラウンディング:画像・音声も用いることでハルシネーションを抑えられる。

- 2025年は「多層防御」アプローチが主流
- データとモデル両面からのアプローチ
- ヒューマンインザループを組み合わせる
- 特定ドメインに特化した対策手法の発展
- 検出ツール
- KnowHalu
- UNIHD
- LogicCheckGPT
- TLM Method
- 三つの言語モデルを用いて検出する手法で、2024年のベンチマークでは最も効果的
疑似コード
- ヒューマンインザループによる検証手法
- 専門家アノテーションガイドラインでハルシネーションに気をつけるためのガイドなどを作る
- 複数の人間評価者の判断を集約する
- AIが一段階目である程度検出した上で最終判断を人間に行わせる
- 実装パターンとベストプラクティス

- コスト効率の高い対策手法
- 以下のトレードオフを意識
- 精度と応答速度のバランス
- 汎用性と専門性のバランス
- 自動化と人間レビューのバランス
@Yuya Matsumura
[paper] PaperBench: Evaluating AI's Ability to Replicate AI Research
- AI系の論文の再現能力を評価するベンチマーク PaperBench についてのOpenAIからの論文

- ICML2024を対象。それぞれの論文をいい感じに分割して、8316個の評価可能なサブタスクに分解して評価

- 評価自体はLLM-as-a-Judge
- Claude 3.5 Sonetが強い

- 時間をかけるとトップレベルの人間の方が強い

@Tomoaki Kitaoka
[論文] WebLLM: A High-Performance In-Browser LLM Inference Engine

- ちょっと古いけど、ブラウザでLLM動かそうぜ〜〜〜ってやつ
- デモはこちら
- 初回の実行はかなり遅いけど軽量モデルなら2回目以降は結構早い
- MLCEngine
- 初回のみ「モデルの重み」と「WASMライブラリ」を読み込む。これらはダウンロードされ、ブラウザにキャッシュされる。
- WASMライブラリに含まれる WebGPU 用の計算コードを使って、GPU上で高速に主要な推論計算を実行。WebGPUはW3C(ウェブ技術の標準化団体)が定めた新しい標準技術で、これにより、ウェブブラウザ内で直接GPUのプログラムを実行できる。WebGPUは、WGSL(WebGPU Shading Language)という専用言語で書かれたプログラムを、パソコンやスマートフォンに搭載されているGPU(Macbook、NVIDIA搭載ノートPC、Androidスマホなど)が理解できる形式に変換される。
@Shun Ito
[論文] Multi-Token Attention
- by Meta, 2025/04
- 新しいattentionの手続きを提案
- 例えば Where did Alice see the rabbit? のような「Alice と rabbit の両方が含まれる文章」を類似検索したい場合に、両者を単一のベクトルに落とし込みたい
- attentionのQK部分で、複数トークンの情報を織り込む


- (手法1)softmaxの前 or 後 に、隣接するQuery, Keyの情報を畳み込む
- 元々のsoftmax前後の手続き
- softmax前で入れる場合(c_q, c_kは隣接トークンをどこまで参照するかのハイパラ)
- softmax後に入れる場合




- (手法2)head間の情報を畳み込む
- c_h 個のグループに分割し、グループごとに畳み込み

- 結果としては精度改善される。他の実装への組み込みやすさは課題

@Takumi Iida (frkake)
[blog] 画像に対する自己教師あり表現学習手法について(2記事)
- 次の2記事のまとめです。
- 導入

- Siamese Architecture
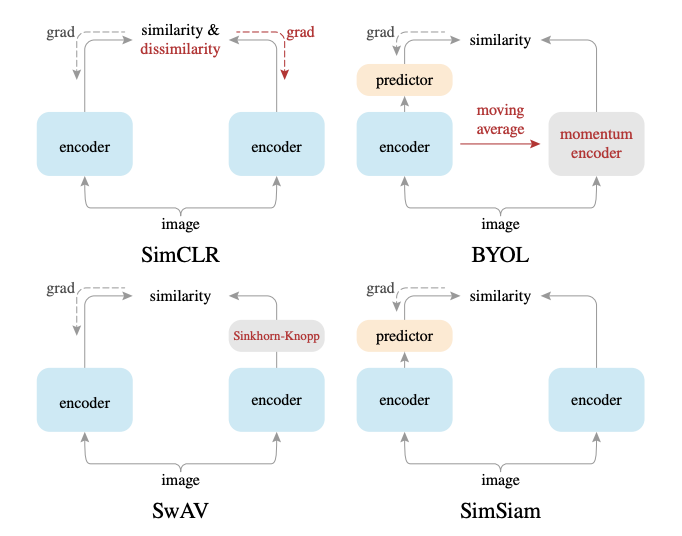
- Data Augmentation
- Crop, Color Distortionの組み合わせが良い(タスクによるが)
- Momentum Encoder
- DINO
- sharpening:モデルの出力を先鋭化する
- centering:同じような出力ばかり出さないように、出力に対してバイアスをかける
FFN Fusion: Rethinking Sequential Computation in Large Language Models
- Akhiad Bercovich, Mohammad Dabbah, Omri Puny, Ido Galil, Amnon Geifman, Yonatan Geifman, Izhak Golan, Ehud Karpas, Itay Levy, Zach Moshe, Najeeb Nabwani, Tomer Ronen, Itamar Schen, Elad Segal, Ido Shahaf, Oren Tropp, Ran Zilberstein, Ran El-Yaniv
AIによる3行まとめ
- この論文は、大規模言語モデル(LLM)の逐次的な計算を削減する新しい最適化技術「FFN Fusion」を提案しています。
- この技術は、特定のアテンション層を除去した後に残る連続したFFN(Feed-Forward Network)層を特定し、精度への影響を最小限に抑えながら並列処理に変換します。
- この手法をLlama-3.1-405Bに適用し、推論速度を1.71倍向上させ、トークンあたりのコストを1/35に削減した効率的なモデル(Ultra-253B-Base)を作成しました。
Introduction
- LLMのランタイム最適化に関する研究では、多様なアプローチが模索されてきたがそれぞれ課題がある
- 量子化 (メモリ使用量を削減し、低精度演算によって推論を高速化)
- ビット数を極端に削減すると精度と正確性のトレードオフが生じる
- プルーニング (冗長なパラメータを削除)
- 精度を損なわずにさらなる冗長性を特定することが困難であり、特に構造的なプルーニングでないと効率化が限定的
- Mixture of Experts (推論時にモデルのごく一部のパラメータのみを動的に活性化)
- 単一トークン推論や大規模バッチ推論には効率的だが、中小規模のバッチでは計算資源の活用不足が発生し、最適なスループットを確保できない
- 本研究の貢献
- FFN Fusion
- 近年の研究により、LLMには構造的な冗長性が存在することが明らかになっており、特にアテンション機構は、選択的に除去しても精度への影響が限定的であることが示されている
- その結果、多くのモデルには連続したFFN層の長いシーケンスが残ることが多くなる
- 本研究では、これらのFFN層の間には驚くほど低い依存関係しかないことを示し、複数の連続するFFN層を1つのより広いFFN層に融合(fusion)することで並列実行を可能とする
- 特に、現代のGPUノードでは、テンソル並列実装が連続する層間の同期遅延に悩まされることが多いが、この手法はデバイス間の通信を減少させることで、ハードウェアの利用効率を大幅に向上させる
- 研究結果は、LLMの計算の大部分が最小限の精度影響で並列化できることを示しており、既存のランタイム最適化技術(プルーニングや量子化など)を補完する
- Ultra-253B-Baseの実証
- Llama-3.1-405B-Instruct (Llama-405B) をベースにFFN Fusionとattention pruningを適用したUltra-253B-Baseを開発
- Ultra-253B-Baseは、本手法のスケーラビリティを示すだけでなく、親モデルと同等以上の性能を維持しながら、包括的なベンチマークスイートにおいて顕著な効率向上を達成
- 推論速度の大幅向上
- 推論レイテンシを1.71倍の高速化を実現し、バッチサイズ32でのトークンあたりのコストを1/35に削減
- 最先端のベンチマーク性能
- Arena Hard: 84.92%, HumanEval: 86.58%, MMLU Instruct: 87.54%, MMLU-Proで72.25%, MT-Benchで9.19
- メモリ使用量の削減
- KV cacheメモリを1/2に削減し、パラメータ数を405Bから253Bに削減することでメモリフットプリントを改善
Preliminaries
- Transformer-based LLMs
- アテンションの適用
- 入力 に対し、正規化 を適用し、アテンション処理を行い元の入力 に加算
- FFN層の適用
- アテンション処理後の出力 に対し、正規化 を適用し、FFN層を通した後に加算
- FFN層 (SwiGLU) の定義
- 本研究で使用するFFN層は、SwiGLU(Shazeer, 2020) というモジュールを採用しており、以下の式で表される
- はSiLU (Swish Linear Unit) 活性化関数
- : 埋め込み次元, : FFNの隠れ次元
- Puzzle
- Puzzle(Bercovich et al., 2024)は、学習済みLLMの推論効率を最適化するためのニューラルアーキテクチャ探索(NAS)フレームワーク
- 事前学習された親モデルから始まり、蒸留プロセスを通じてモデルの品質を維持しながら、各トランスフォーマーブロックを体系的にプルーニングまたは再構成します
- 特に、Puzzleの適用では、多くのアテンションレイヤーが最小限の精度損失で除去できることがしばしば示されており、その結果、アテンションによって中断されないFFNのシーケンスが残る
- さらに、特定のFFNレイヤーは大幅なチャネルプルーニングにより、その隠れ次元の削減につながる

FFN Fusion
- Puzzleアルゴリズムによるモデル最適化の一環として、ベースモデルの多くのアテンションレイヤーが削除される
- アテンションが削除されたTransformerブロックは以下の式で定義される
: アテンションを除去したTransformerブロック
: トークン毎の正規化関数
: Feed-Forward Network
- このようなアテンションを削除したTransformerブロックが連続している場合、 のような 個のブロックがあるとする。このときFFN Fusionを適用し、並列化した場合以下のように定義される。
- とFFN層の系列があった場合に各FFN層 の重み行列を と定義
- このときFFN Fusionによって得られるFFN関数の和は以下の重み行列を持つ単一のFFN関数 と等価
- FFN Fusionのポイント
- すべてのFFN層が同じ入力を共有
- 従来の逐次処理では、各FFN層の入力は前の層の出力に依存
- 計算の独立性が向上
- 各FFN層が前の層の出力に依存しないため、並列計算が可能
- GPU上での計算効率が向上し、推論速度が大幅に改善
- 複数のFFN層を1つのFFN層に統合
- n 個のFFN層の計算を、1つのより広いFFN層として処理できる
- 各層の重み行列を結合することで、新しいFFN層のパラメータを構成
効率性の動機と分析
- LLMは一般的に逐次的なブロックで設計されており、モデルの規模が大きくなるにつれてブロックサイズとブロック数が増加
- 大規模なモデルでは、テンソル並列化 (TP) などの手法を使用して計算を複数のGPUに分散し、推論レイテンシを削減するがGPU数を増やしても、必ずしもレイテンシの削減が線形には向上しない
- 並列化が線形なレイテンシ改善をもたらさない理由
- 各TPブロックの後に、all-reduce (全GPU間でのデータ同期) の通信が必要
- 小規模演算におけるGPU性能の低下
- GPUは大規模な行列演算に最適化されているため、各演算が小さくなると、低レベルのオーバーヘッドの影響が大きくなる
- FFN Fusionではこの問題を解決するために、複数の逐次ブロック (FFN) を融合し、より大きなブロックに統合
- 逐次処理の回数を減らし、各ブロックの計算をまとめることで、同期オーバーヘッドを削減
- ブロックのサイズを大きくすることで、より多くのGPUを活用しながら十分な計算を各GPUに割り当てられる
ブロック間の依存関係の対応分析
- ブロック の貢献度 を定義
- ブロック を削除した際のブロック の貢献を と定義
- 依存度を表す行列 を次の式で計算
- 小さいコサイン距離 (青色)
- 独立性が高い (ブロック を削除しても の出力に大きな影響なし)
- 並列化可能
- 大きいコサイン距離 (赤色)
- 強い依存関係 (ブロック を削除すると の出力が大きく変化)
- 逐次処理が必要
- 以下のヒートマップはUltra-PreFusionモデル (FFN Fusion前) を対象に依存行列の結果
- ブロック 0 および 5 はすべてのレイヤーと強く相互依存 (暗い赤色)
- 点線の青色領域は、相互依存が低いFFNブロック

Producing Large-Scale Models with FFN Fusion
Base 405Bの派生モデル
- Llama-405Bに標準的なPuzzle探索を実行し、派生モデルが1.5倍のレイテンシ高速化を達成し、単一のNVIDIA 8×H100ノード (合計640 GB) および単一のB100 GPU (192 GB) で最適化
- これにより、253Bパラメータのベースラインモデルが得られ、多くのアテンション層が削除され50個のブロックが連続的に配置された
FFN Fusion
- 連続する50個のFFN層のうち49個にFFNフュージョンを適用
- 最後のFFNもフュージョンすると精度が低下。モデルの表現において最後のFFN層は重要であることが示唆される
- GPUのメモリ制限により、レイヤーを[66, 73]、[74, 85]、[86, 100]、[101, 114]の4つのシーケンスに分割し、それぞれを単一のFFNにフュージョンした
- フュージョン前、ベースラインモデルはMMLUで84.23、MT-Benchで8.83を達成。49個のレイヤー全てをフュージョンした後もモデルは追加トレーニング前の段階でMMLUの精度(82.76)を維持し、MT-Benchで8.35を達成
Additional Training
- 性能を回復するため、複数段階の蒸留(KD)を行い、MMLUとMT-benchのスコアがそれぞれ85.17と9.10に向上
- 8kコンテキストで54Bトークン
- 16kと32kでそれぞれ5Bトークン
- 128kで0.8Bトークン
- さらに2つの方法で最適化
- instruction-tuningとRLHFによる低コストのアラインメント
- 表1はアラインメント前後のUltra-253B-Baseを比較
- 表3は、Ultra-253B-BaseがLlama-405Bの性能を上回ったことを示しており、特にArena Hardベンチマークで顕著
- 蒸留の後、アラインメントを行わず、より長期の継続的事前学習(CPT)のみを適用
- 8kのコンテキスト長で73Bトークン
- 258kのコンテキスト長で15Bトークン
- instruction-tuning前でも強力な性能を示した



Efficiency Improvements
- ユーザーレイテンシで1.71倍の高速化

- バッチサイズ32での1トークンあたりのコストを1/35に削減
- アテンションレイヤーを半減し、パラメータ数を405Bから253Bに削減することでメモリフットプリントを削減
- Ultra-253B-Baseは単一のH100ノードにおける効率のフロンティアを更新し、同様のハードウェア制約の下で最先端の精度とレイテンシを実現
