
2025-04-15 機械学習勉強会
今週のTOPIC[lib] FastAPI-MCP[slide] NLP2025 参加報告会 / NLP2025[blog] Introducing GPT-4.1 in the API[blog] 生成AIの構造化出力において、フィールドの順番や命名が重要[論文] Advances and Challenges in Foundation Agents: From Brain-Inspired Intelligence to Evolutionary, Collaborative, and Safe Systems[blog] Agentforce: Scaling Agentic AI for Enterprise Automation & Observability—Powering 2 Billion Predictions Monthly[blog] LLMを活用した商品検索タグ自動生成とRecall改善の取り組み(BigQuery × Gemini)[論文] ConceptFormer: Towards Efficient Use of Knowledge-Graph Embeddings in Large Language Models[論文] SkillWeaver: Web Agents can Self-Improve by Discovering and Honing Skills[論文] SoTA with Less: MCTS-Guided Sample Selection for Data-Efficient Visual Reasoning Self-Improvement[論文] VideoChat-R1: Enhancing Spatio-Temporal Perception via Reinforcement Fine-TuningメインTOPICOLMoE: Open Mixture-of-Experts Language Models背景MoEについて事前学習全体的な結果設計ごとの検証実験事前学習の設定MoE分析
今週のTOPIC
@Naoto Shimakoshi
[lib] FastAPI-MCP
- FastAPIサーバーを簡単にMCP化出来る
- インストール
- 以下をするだけで にMCPサーバーができる
- エンドポイントで取得できるOperation (Tool)を制限できたりする
- 使う時は、 で を入れるだけ。
[slide] NLP2025 参加報告会 / NLP2025
- SansanさんのNLP参加報告スライド。自身の発表と面白かった発表についてのまとめ。
- ニュース記事に登場する会社名がどの法人番号の会社とマッチするかを判定する論文を自身で発表
- 同名別企業がある場合が課題
- cosine類似度で今までやっていたが、GPTでやるようにしたことで、0.21 → 0.86に正解率が向上
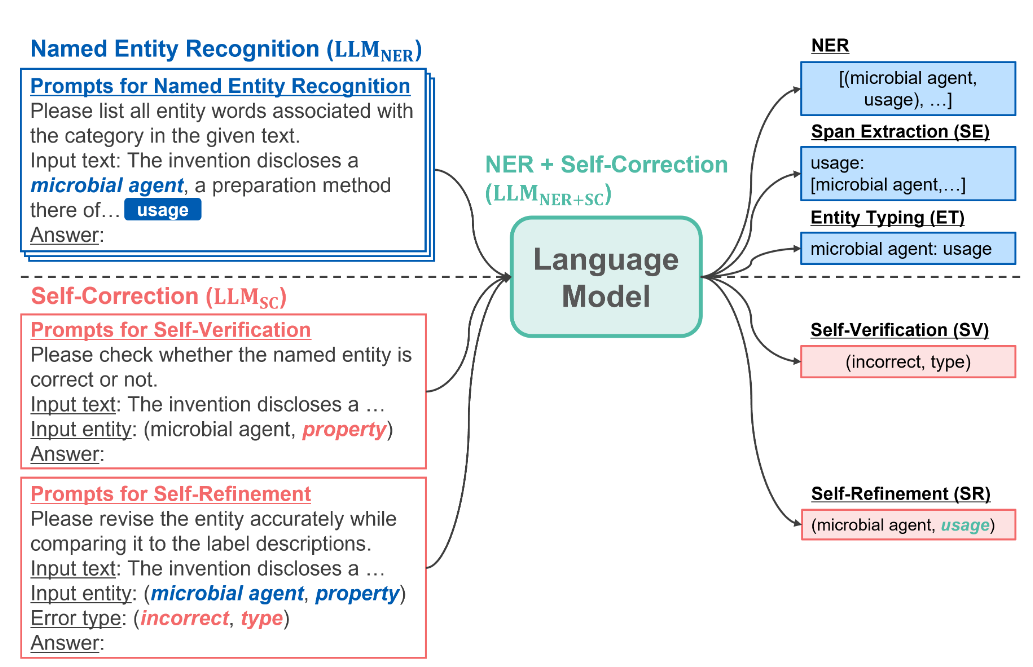
- 自己修正に基づく固有表現抽出モデルの指示学習
- 旭化成さんの研究
- 課題:生成モデルの方が近年では抽出モデルより高性能と報告されていることがあるが、依然として抽出モデルの方が高性能なケースが多い。要因の一つとして生成モデルの場合は抽出エラーが発生。
- 抽出エラーの分類。本論文ではFalse Positiveの場合に焦点を当てる。
- 過抽出
- スパンの部分不一致に起因
- 抽出不足
- スパンの部分不一致に起因
- ラベル
- エンティティのラベルが間違い
- スパン + ラベル
- 修正不可
- それ以外
- ハルシネーションとかもこれ?
- 対策:Instructoin Tuningする過程でSelf-Refinementを同時に学習させることで抽出エラーを減らす。
- gemma-2-2b-itをInstruction Tuning
- 固有表現抽出、スパン抽出、エンティティ型推定を同時に学習
- InstructUIEに則った手法
- それに加え、生後判定、エラー分類も生成するように学習 (Self-Verification)し、上の結果と照らし合わせて修正後の固有表現も生成 (Self-Correction)
- 結果
- Self-Correction w/ Oracle SVはSVが100%の精度だった時の結果

@Yuya Matsumura
[blog] Introducing GPT-4.1 in the API
- 新しいGPTファミリーのGPT4.1 が出るよ!
- GPT-4.1
- GPT-4.1 mini
- GPT-4.1 nano
- npakaさんの日本語記事をどうぞ。
- ‣
- 4oシリーズと比べて早くて賢いよ!ベースモデルはこれになりそう。

- コーディング能力大幅アップ!
- 指示追従能力大幅アップ!
- ここがでかいように思う。指示した通りに出力してくれる能力が上がったのでプロダクトで使いやすい。
・フォーマットの追従モデルのレスポンスにXML、YAML、Markdownなどのカスタムフォーマットを指定する指示を提供します。・否定的な指示モデルが避けるべき動作を指定します。(例:「ユーザーにサポートへの問い合わせを求めないでください」)・順序付き指示モデルが特定の順序で実行しなければならない一連の指示を提供します。(例:「まずユーザーの名前を尋ね、次にメールアドレスを尋ねてください」)・コンテンツ要件特定の情報を含むコンテンツを出力します。(例:「栄養プランを作成するときは、必ずタンパク質の量を含めてください」)・ランキング出力を特定の方法で順序付けます。(例:「人口数でレスポンスを並べ替えてください」)・過信要求された情報が利用できない場合、またはリクエストが特定のカテゴリに該当しない場合に、「わかりません」などの返答をモデルに指示します。(例:「答えがわからない場合は、サポート担当者のメールアドレスを入力してください」)
- ロングコンテキスト
- 最大100万トークン(4oは128,000)
- 長いコンテキストだけど全体をちゃんと認識できるように学習したとのこと。
- コンテキストの長さがどうであっても、コンテキストのどこに”針”があっても探せている図
- より現実世界に即したベンチマークであるOpenAI-MRCRをオープンソース化
- マルチホップのロングコンテキスト推論を評価するためのデータセットGraphwalksのリリース
- 複数のファイル間を移動したり、ドキュメントを相互参照したりといったコンテキスト内で複数回の論理ホップが必要となるタスクのベンチ

コンテキストに巧妙に隠された複数の針を検出し、それらの曖昧性を解消するモデルの能力をテストします。評価は、ユーザーとアシスタントの間で複数ターンの合成会話で構成され、ユーザーは「バクについての詩を書いてください」や「岩についてのブログ記事を書いてください」など、あるトピックに関する文章を要求します。次に、コンテキスト全体に2つ、4つ、または8つの同一のリクエストを挿入します。モデルは、特定のインスタンスに対応する応答(例:「バクについての3番目の詩をください」)を取得する必要があります。
課題は、これらのリクエストとコンテキスト全体の類似性にあります。モデルは、詩ではなくバクに関する短編小説、あるいはバクではなくカエルに関する詩といった微妙な違いによって簡単に誤解してしまう可能性があります。「GPT-4.1」は、コンテキスト長が128,000トークンまで「GPT-4o」よりも優れており、100万トークンまで高い性能を維持することがわかりました。
- 画像理解もそこそこ
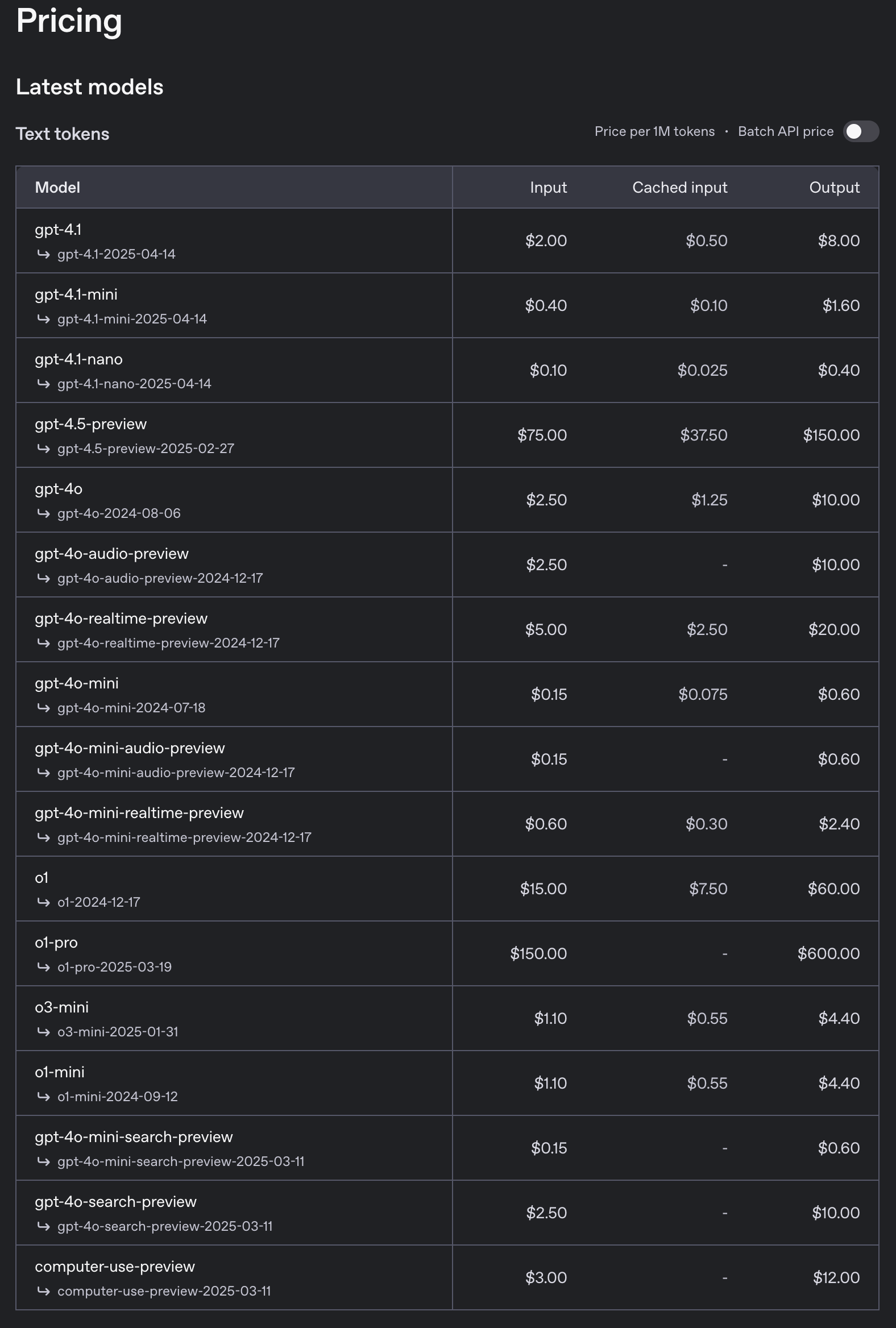
- 価格
- 4.1は4oよりも26%安価
- プロンプトキャッシュが強くなっている(50% → 75%)ので、同じようなプロンプト使う系ではけっこう安くなりそう。

全盛り
@Shun Ito
[blog] 生成AIの構造化出力において、フィールドの順番や命名が重要
- takeaway
- 推論理由を最初のほうで出力させたほうが精度が高まる
- Structured Outputの出力を安定させたい
- from https://www.dsdev.in/order-of-fields-in-structured-output-can-hurt-llms-output
- reasoningを先に置いたパターンAが96%、後に置いたパターンBが54%の正解率
- from https://python.useinstructor.com/blog/2024/09/26/bad-schemas-could-break-your-llm-structured-outputs/
- 結果を格納するfield名をfinal_choice → answerにすると、精度が4.5% → 95%に向上
- from https://openai.com/index/introducing-structured-outputs-in-the-api/
- 文脈自由文法を使って、前から順番に生成している。Chain of Thoughtのように、推論理由を最初に方に出力させた方が精度が良い
@qluto (Ryosuke Fukazawa)
[論文] Advances and Challenges in Foundation Agents: From Brain-Inspired Intelligence to Evolutionary, Collaborative, and Safe Systems
論文タイトル通り、「基盤エージェント」というフロンティアに対し、その設計思想、学習方法、応用、そして安全性に関わる課題までを脳神経科学、進化、協調といった学祭的なアプローチにによってまとめたサーベイ論文。
非常に膨大かつ広範なトピックを扱っており、参考文献の数は1400件を超える。重厚壮大な論文。
ただ扱っている文献の数が多いだけでなく、認知科学での知見を活かした論文の分類や考察をしているのがユニークポイントになっているサーベイ。
たとえばAgentのMemoryに関する章だと、冒頭に人間の記憶はこのように(認知心理学の分野では)モデル化され考えられているというものを示しながら Agent に応用する際には……、それに関する論文は……というような話の展開をしていっている。

Memoryを扱うにあたっても、どうエンコーディングするか、活用された状況を踏まえて強化・忘却をどうAgentに組み込むかという問題に対しそれぞれの論文がどのようにアプローチをしているかを把握することができる
[blog] Agentforce: Scaling Agentic AI for Enterprise Automation & Observability—Powering 2 Billion Predictions Monthly
SalesForceが提供するAgentforceがどのように構築されているかという外観を紹介する記事

- 統計的分類と決定木に依存し高度に構造化された予測AIモデルたちが居たが、リードスコアリングのようなトレンド予測を吐き出すだけにとどまり、応答を生成したり複雑なデータを統合することには限界があった。
- それを解決するためにRAGを統合し、AIが生成する応答の正確性を確保したとのこと。Recall / Precision のトレードオフに対応するために multi-tiered indexing などの工夫をしたと記されているが詳細は不明。

- 最初のアーキテクチャ外観から Atlas Reasoning Engine の部分をピックアップして解説した図
- Agenticな振る舞いを実現するためのおおまかな解説となっている
記事内別記事内に含まれている、実際のワークフロー例

@Yosuke Yoshida
[blog] LLMを活用した商品検索タグ自動生成とRecall改善の取り組み(BigQuery × Gemini)

- タグ生成パイプライン
- VertexAI Pipelinesで日次実行
- LLMを使ってJANコードごとにタグを生成し、その結果をFirestoreに保存する役割
- Elasticsearchへのインデキシング
- 差分更新であり在庫情報が更新されるタイミング(1日1回以上)で実行
- 更新された在庫情報と、対応するJANコードのタグをマージし、Elasticsearchのインデックスを更新する役割
- 不適切なタグが検索結果に悪影響を与えるリスクを考慮し、以下の設計
- 手動でのタグ管理
- 必要に応じて自動生成されたタグを確認し、追加・削除できる設計に。
- フロントエンドへは非表示
- 生成されたタグはあくまで検索ロジック内部で利用するものとし、商品詳細ページなどでユーザーに表示しない。
- 検索スコアへの影響抑制
- 検索結果のランキング精度を維持するため、タグの検索スコアへの重みは0に設定。これにより、タグによってヒットするようになった商品は検索結果の末尾に表示され、既存のランキングロジックへの影響を最小限に留めました。まずは「見つからない」を減らすことを最優先しました。
prompt
- リリース後の効果測定
- ゼロマッチレート: 15%減少
- 平均ヒット件数 : 8%増加

@Takumi Iida (frkake)
[論文] ConceptFormer: Towards Efficient Use of Knowledge-Graph Embeddings in Large Language Models
- 読んだ動機
- 「LLMの知識編集手法」というふうに紹介されているのを見て、特定の知識をManipulation, Editingできる方法かと思い、面白そうだと感じたため。 → 読後:知識拡張的な方法だなと感じた。
- 概要
- LLMを再学習することなく(アダプタも不使用)、知識グラフの情報を取り込めるConceptFormerを提案
- 良さ
- 入力の埋め込みレベルで動作するだけなので、Decoder-only LLMとシームレスに統合できる

- 手法
- 処理の流れ
- ユーザのクエリから知りたい(知識を拡張したい)固有表現を得る(NER)
- グラフデータセット(T-REx Star)から知識グラフ取得
- ConceptFormerで知識グラフをConcept Vectorに埋め込む
- 割とシンプルなTransformer N=ノード、E=エッジの埋め込みベクトルとした場合
- ユーザのクエリ(入力埋め込み)に追加
- どう使うか(学習など)
- Tri-RExデータセットを使ってConceptFormerを学習。LLM自身はFreeze。 知識グラフデータセットから別に学習。next-token predictionでSubject-PredicateからObjectを予測するタスクをLLMに解かせる。
- T-Rex Biteでさらに細かく学習

- 結果
- 再学習を使わない方法との比較。一番良いということになっている。 (なんか古い気がする+単純なファインチューニング手法との比較もすべきでは)

- 感想
- LLM自身のパラメータはいじくらないので、そこは良いのでは&面白いと思った。
- しっかり読めてないが、結果に人間の意思がかかっていそう。
@ShibuiYusuke
メインTOPIC
OLMoE: Open Mixture-of-Experts Language Models
ICLR2025 (Oral)
背景
- 学習・推論コスト vs. LLMの精度 のトレードオフを改善するための手法に Mixture-of-Experts (MoE) がある
- 全てのパラメータで動かすのではなく、tokenごとに適切なExpert(FFN)だけを選んで動かす
- Gemini-1.5やGPT-4でも使われているらしい
- MoEは複雑で知見が多く求められるが、あまり公開されていないのが課題
- LLM with Mixture-of-Experts (MoE) を構築し、OLMoEとして公開
- Model, Data, Code, Logsをすべて公開 & コスパが非常に良い
- 実験から得られた知見を論文内で公開

MoEについて

- 個のレイヤーそれぞれについて、Feedforward Network (FFN) がMoE Moduleに置き換えられている
- FFN: それぞれのtokenについて、Network全体を使って実行する
- MoE: より小さなFFN module (Expert) が用意されており、tokenごとにRouterが適切なExpertを割り当てて実行する。
- tokenごとに一部のパラメータしか利用しないため、全てのパラメータが動くdenseモデルと比べて軽量になる
- 手続き
- router の出力 top k について、softmax値とExpertの値を掛け合わせ、それらを合計

事前学習
- 各種設定は以下の通り

- 損失: cross-entropyにペナルティ(後述)を2種類追加したもの

- データセット: DCLM + Dolma1.7を混ぜて前処理をかけた合計5.1T tokens
- クロールデータ、数学、論文、Wikipediaなど
全体的な結果
During pretraining

After pretraining

After adaption (instruction tuning + preference tuning)

設計ごとの検証実験
Mixture-of-Experts vs. Dense
- 本当にMoEにして良くなるのか?

- token数で3倍、学習時間で2倍、学習が効率化された
Expert Granularity
- Expertの個数はどれくらいがよいのか?
- 計算量(使われるパラメータ数)を揃えて比較実験
- 8 → 32は改善幅が大きいが、32 → 64は改善幅が小さくなる
- 過去研究によると今回のCompute Budgetでは理論上256 Expertsが最適らしいが、学習に使用するデータ量・モデルサイズの都合で大きすぎるため64 Expertsを採用


Shared Experts
- 常に利用されるshared expertsを用意するのは有効か?
- 普遍的な情報を掴むsharedを用意することで、その他のexpertがより特化した情報を掴める期待
- 実験の結果はShared有りがやや悪い結果となり、今回は不採用
- Expertsの組み合わせの種類が減ってしまうのが悪く働いてしまっている?

Expert Choice vs. Token Choice
- Expert - Tokenのマッチングは2種類ある
- Expert Choice: Expertそれぞれが、sequenceのどのtokenを使うか選ぶ
- Expertのバランスは良いが、全く選ばれないtokenが出てしまう可能性がある
- Token Choice: Tokenそれぞれについて、どのExpertを使うか選ぶ
- 特定のexpertに偏る可能性はあるが、全てのtokenがいずれかのexpertに流れる
- TC + Load Balancingが一般的で、性能もTCがbetter
- ECの方が20%ほど速い & マルチモーダルなケースで不要なimage tokenを落とせるため、再検討の余地はある

Sparse Upcycling
- denseモデルを起点にMoEモデルを構築する方法
- 元となるdenseのFFNをMoEレイヤーの各Expertに複製する
- MoEレイヤーの手前にrouterを追加
- 作成されたアーキテクチャで事前学習を続ける

- Upcycleでの学習とScratchでの学習を比較すると、500Btoken辺りでほぼ同じ精度になり、600KB付近でScratchが上回った
- Upcycleだと元のモデルの設定を一部受け継ぐ必要がある。その中で今回構築するモデルにとって精度に寄与しないものがあったので、今回はScratchを採用した

Load Balancing Loss
- tokenの割り当て先が特定のExpertに偏ってしまうのを緩和する損失(ペナルティ)

- : sequenceのうちExpert i に割り当てられたtokenの割合
- : batch全体でExpert i にroutingされる確率
- : Expert数
- Load Balancing Lossの導入で、精度改善され、特定Expertへの偏りも緩和された

Router Z-loss
- routerの特定Expertへのlogitが極端に大きくならないようにする損失(ペナルティ)

- Z-loss導入で学習中のspikeが減り、精度改善も見られた

事前学習の設定
(略)
MoE分析
Router Saturation
- MoE層ごとに、ある時点のExpertの選ばれ方と学習終了後の選ばれ方とが、どれくらい一致しているか?

- 後ろの層は早い段階で60%ほど一致しているが、前の層はゆっくり収束していく
Expert Co-activation
- 同時に選ばれやすいExpertはどれくらい存在するか?

Domain Specialization
- ドメインによって選ばれやすいExpertはあるか?

Vocabulary Specialization
- Expertによって関連するtokenの傾向はどれくらい異なるか
- ExpertがどのようなInput / Outputのtokenに対して利用されるか
- 例えば、Expert 43 は地理系のtokenでよく利用される
