
2025-04-22 機械学習勉強会
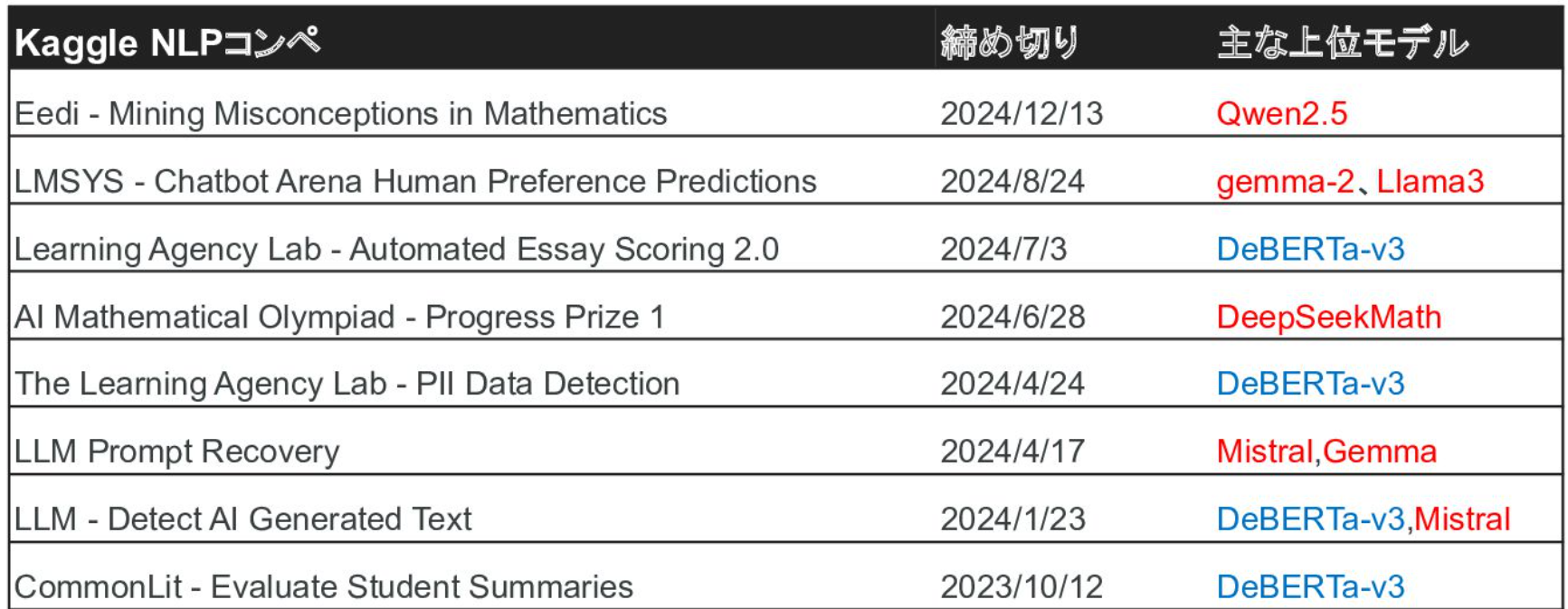
今週のTOPIC[slide] Kaggle自然言語処理コンペ向けローカルLLM活用入門[paper]Relevance Isn't All You Need: Scaling RAG Systems With Inference-Time Compute Via Multi-Criteria Reranking[slide] MCP Server as a Judge[blog] The State of Reinforcement Learning for LLM ReasoningDETR手法の変遷と最新動向(CVPR2025)[blog] How to think about agent frameworks[paper] Welcome to the Era of ExperienceメインTOPICこれはなに?Introduction関連研究大規模言語モデルと検索大規模言語モデルと強化学習Search-R1の手法Reinforcement Learning with a Search EngineGeneration with Multi-turn Search Engine CallingTraining TemplateReward Modeling結果データセットベースライン実験設定パフォーマンス分析PPO vs. GRPOBaseモデル vs. Instructモデル応答長と有効な検索呼び出しに関する分析取得トークンの損失マスキングに関する検証結論
今週のTOPIC
@Naoto Shimakoshi
[slide] Kaggle自然言語処理コンペ向けローカルLLM活用入門
- Kaggleでも普通にLLMのファインチューニングが行われるようになってきた
- 学習
- まずは を試す。文書分類でもこれを使ったりする。(Yes or NOで答えて → Yesを出力)
- 候補のトークン (Yes or No)を固定して確率も出せる
- 参考コード:https://www.guruguru.science/competitions/24/discussions/21027ff1-2074-4e21-a249-b2d4170bd516/
- LoRAで学習
- ChrisのTIPSが参考になる:https://www.kaggle.com/competitions/lmsys-chatbot-arena/discussion/527596
- モジュールは全て学習させた方がいい
- 学習率は2e-4 or 2e-5、バッチサイズは8 (全てのGPU合わせて)がおすすめ
- r=16で固定でalphaを調整 → 1epochでalphaを決定 → alphaを固定してr調整
- 推論
- vLLM使う
- 、などをちゃんと設定する
- 量子化
- 量子化してLoRA学習
- 学習してから量子化
@Yuya Matsumura
[paper]Relevance Isn't All You Need: Scaling RAG Systems With Inference-Time Compute Via Multi-Criteria Reranking
- MS Research / ICLR2025 poster
- ‣
- RAGにおいて、クエリのベクトルと類似度の高い(関連性の高い)ドキュメントを引っ張ってくるだけでは最終的な回答の質の向上に限界があるよねというよくある話が課題感
- 関連性以外の複数の基準でもリランクしようぜというIRっぽい話
- 基準
- Depth of Content
- Diversity of Perspectives
- Clarity and Specificity
- Authoritativeness
- Recency
- LLMに思考させて(CoTで)適切な基準を選ばせてええ感じでリランクしようぜという手法。
- 通常通り、クエリと類似するドキュメント群を獲得した後、それらをもとにLLMに並び替えの基準を考えさせてから並び替えるという手法。
- 入力に応じてLLMが利用する基準を動的に選んでリランクしている部分が面白いと思った。

@Shun Ito
[slide] MCP Server as a Judge
- JAWSで昨日発表されていた資料


- 評価用のMCP Serverを用意し、共通の評価基盤として利用する
- RAGで利用する例

- 別のAIアプリケーションでも、評価部分は共通化して利用できる

- 評価基盤のMCP化は見たことがなく面白い
@qluto (Ryosuke Fukazawa)
[blog] The State of Reinforcement Learning for LLM Reasoning
RLHFの中で使われていたPPOに始まり、DeepSeek-R1でも脚光を浴びたGRPO、そしてその後のLLMに対する強化学習の最近について紹介した記事。
RLHFからDeepSeek-R1に至るまでの流れのおさらいをしたい人には記事前半が役立つ。

@Takumi Iida (frkake)
DETR手法の変遷と最新動向(CVPR2025)
DETRの派生系物体検出モデルを解説してる。CVPR2025に採択された論文もカバー
後半の部分だけ以下に紹介

Mr. DETR
one-to-one assignmentだと後処理が不要でE2Eで推論できるが、初期の学習がむずい
→ one-to-manyをマルチタスクで解かせて安定化
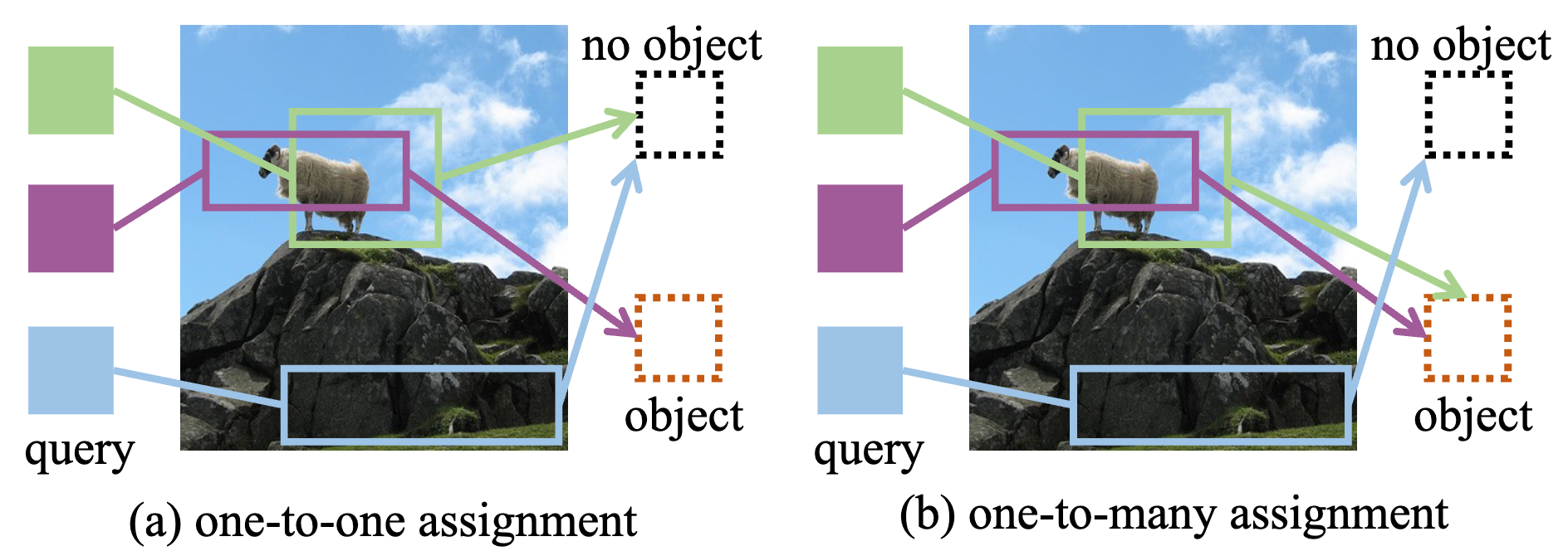
Mr. DETRが考えたこと「o2oとo2mの学習でネガティブトランスファーが起きてしまう
→ Self-AttentionとFFNを分離したデコーダにする


DEIM: DETR with Improved Matching for Fast Convergence
one-to-manyだと、追加のデコーダで計算量が増加+冗長なBBoxを生成してしまう
→ 密なone-to-oneマッチング+Matchability-Aware Lossを提案
やったこと1:正例を増やして、Positive Predictionを増やす←o2oの初期の学習の進みづらさ解消?

やったこと2:IoUが低い場合でもLossを大きくして、正例に対する勾配を強くする

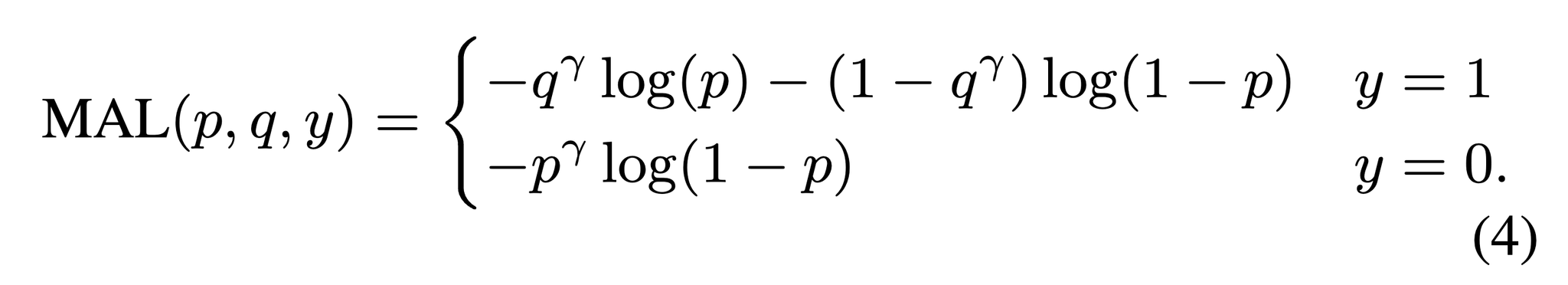
結果:学習効率だけでなく、推論速度も結構速い
@ShibuiYusuke
[blog] How to think about agent frameworks
- LangChain作者のHarrisonによるAI Agentフレームワーク論。
- OpenAI’s guide on building agentsに対する批判でもある。
- ポジショントークな主張も多いが(OpenAIのガイドもポジショントークか)、LangChainというLLMを活用する汎用ライブラリを作ってることもあり、AI Agent開発者(プログラムを書いて体験をつくる人)のためのLLM活用のPainを論じてて面白い。
- WorkflowとAgent
- Predictability vs agency
- ワークフロー:確実性の高いユースケースで有効。決まったパスを統合するシステム。予測可能性と一貫性。
- AI Agent:不確実性が高く、プロセスやツール利用を動的に指示するシステム。柔軟性とLLM主導の意思決定。
- (ML/AI開発の常として)いずれにおいても100%の正確性は出せない!
- floor and ceiling
- ワークフローフレームワークの多くは学習が難しい(high floor)が、拡張性が高い(high ceiling)が、作るためには大量のロジックを書く必要がある。
- Agentフレームワークの多くは簡単に始められる(low floor)が、制約も多い(low ceiling)。
- 実際にはワークフローとAgentの組み合わせになる。

- フレームワークの価値
- Agent abstraction:ロジックをコントロールするためにはコード修正が必要になるケースがあり、抽象化がその障壁となることを理解している(LangChain作者が言うと重みがすごい・・・)。
- 抽象化の成功例としてKerasは参考になる。簡単に使い始められるインターフェイスを用意し、しかし利用者が低レベルフレームワーク(TensorFlow)の操作まで必要にならないように作る。
- Short term memory:同じ会話内でのメモリ。
- Long term memory:過去の会話からのメモリ(会話をまたいだメモリ)。
- Human-in-the-loop:ユーザからフィードバックや承認を得る。
- Human-on-the-loop:Agentの処理軌跡をユーザが検査する。さらには以前の状態に戻って処理を再実行する。
- Streaming
- Debugging/observability
- Fault tolerance
- Optimization
[paper] Welcome to the Era of Experience
- DeepMindのSilver先生とSutton先生(強化学習の巨匠!?)による「経験の時代」の幕開けを告げる論文。
- これまでのAIは人間の生成したデータをベースに学習してきたが、人間を模倣するだけでは多種多様なトピックをカバーできなくなってきてる、という主張。
- 新たなデータソースとしてAgentが環境に根ざした行動と観察を学習していく(Agentの行動がデータになる)時代になる。この発想は強化学習の研究者っぽくて面白い。
- 人間の思考様式に囚われない(偏見、論理的誤り等々)データになる可能性がある。
- リスク
- Job displacement
- Potential misuse of AI
- Autonomously interact with the world over extended periods of time to achieve long-term goals
- Experiential agent could observe and learn to circumvent malfunctioning hardware, adjust to rapid societal change, or embrace and build upon new science and technology
- A natural brake on the pace of potential AI self-improvement

メインTOPIC
Bowen Jin, Hansi Zeng, Zhenrui Yue, Jinsung Yoon, Sercan Arik, Dong Wang, Hamed Zamani, Jiawei Han
これはなに?
LLMにリアルタイムの検索エンジンとの連携能力を強化するための、新しい強化学習(RL)ベースのフレームワーク Search-R1 を提案する論文
Introduction
現在、LLMsと検索エンジンを統合するアプローチは主に以下の2つに分類される
- RAG(Gaoら, 2023;Lewisら, 2020)
- 検索エンジンをツールとして扱うアプローチ(ReAct, Toolformer)
RAGではマルチターンでのやりとりを通じて検索を行う手法などが進められているが、LLMが検索エンジンと効果的にやり取りする方法を学習していないので最適とは言えない。
検索エンジンをツールとして扱うアプローチもプロンプトベースの手法では一般化が難しくうまく機能しないことがある。
RLは、LLMの推論能力を高めるための強力な手法として注目を集めている。
特に、OpenAI-o1やDeepSeek-R1といったモデルは、PPO(Proximal Policy Optimization)やGRPO(Group Relative Policy Optimization)といったRL技術を活用し、論理的推論能力や問題解決能力を、経験とフィードバックを通じて向上させている。
RLでは、結果ベースの報酬だけで訓練した場合でも、モデルは自己検証や自己修正を含む高度な推論スキルを学習することが確認されている。
- 検索エンジンを環境の一部としてモデル化
LLMによるトークン生成と検索エンジンからの取得を交互に行う軌跡(trajectory)をサンプリング可能にする。SEARCH-R1はPPOやGRPOなど、さまざまなRLアルゴリズムと互換性があり、取得トークンに対する損失のマスキングを適用することで、学習の安定性を保つ。
- マルチターンでの検索と推論のサポート
と トークンで明示的に検索を呼び出し、結果は ~ で囲まれ、推論は ~ で実行され、最終回答は ~ で記述される。この構造により、LLMが段階的かつ構造化された意思決定を行えるようになる。
💡 DeepSeek-R1では推論部分を ~ で表現するよう学習されている
- 単純な結果ベースの報酬関数を採用
プロセスに依存した複雑な報酬設計は避け、最終結果の正解かどうかだけを報酬として使うことで、検索と推論シナリオにおいても有効な学習ができることを示す。
主な貢献は以下の通り。
- LLMが検索エンジン結果を活用して推論する能力を向上させるための、RL活用における課題とその見解を提示。
- 安定化のための取得トークンのマスキング、複雑なタスク対応のためのマルチターン構造、簡素で効果的な報酬設計を備えた新たなRLフレームワーク SEARCH-R1 を提案。
- 2つのLLMにおいて、同条件下(同一の検索器・データ・事前学習モデル)でRAGベースラインに対してそれぞれ41%と20%の相対的性能向上を達成したことを実証し、RLアルゴリズムの選択やモデル特性、出力長に関する洞察も提供。
関連研究
大規模言語モデルと検索
Introductionでも述べた通り、現在、LLMsと検索エンジンを統合するアプローチは主に以下の2つに分類される
- RAG
- この方法は無関係な情報を取得してしまう問題や、有用な文脈が十分に提供されないといった課題に直面することがある。
- 検索エンジンをツールとして扱うアプローチ(ReAct, Toolformer)
- IRCoT(Trivediら, 2022a)やReAct(Yaoら, 2023)は、プロンプトによって反復的な推論と検索の呼び出しをガイドする
- Toolformer(Schickら, 2023)は、教師ありファインチューニングにより検索操作能力を高める。しかし、これらの手法は高品質なラベル付き軌跡データに強く依存しており、大規模化が難しいという課題を抱えている。
DeepSeek-R1では、RL(強化学習)によって結果ベースの報酬のみを使って高度な推論スキルを育成できることが示されているが、それを検索エンジンの呼び出しシナリオに応用する試みはほとんどなされていない。
⚠️ あくまで、著者が論文として手法が公開されたものの範囲でと言っているものだと思われる。
大規模言語モデルと強化学習
LLMにおけるRLの導入は、Ouyangら(2022)による人間のフィードバックに基づく強化学習(RLHF)により本格化した。
この手法ではまず人間の好みに基づく報酬モデルを学習し(Lambertら, 2024)、その後この報酬モデルを用いてPPOを通じてポリシーLLMのチューニングを行う。しかし、PPOには複数ラウンドにわたるモデル最適化が必要であり、実装が難しい。
そのため、より単純化された手法として、DPO(Direct Preference Optimization)やSimPOといった直接最適化手法が提案されている。これらは計算効率が高い一方で、オフポリシー問題に弱く、純粋なRL手法と比べて一貫した性能を出しにくいという欠点がある。
代替的な解法としては、GRPOがある。これは、ベースラインの推定をグループスコアに基づいて行うことで、価値関数を不要にする。また、RLOOは、REINFORCEスタイル(Williams, 1992)のシンプルな最適化枠組みを導入している。
💡 GPROはDeepSeekMathで採用され、DeepSeek-R1でも大きな貢献を果たした
Search-R1の手法
Reinforcement Learning with a Search Engine
- は検索エンジン
- はポリシーLLM
- はリファレンスLLM
- は報酬関数
- はKLダイバージェンス
- はデータセットからサンプリングされた入力
- は、検索エンジンからの取得結果を挟みながら生成された出力
既存のPPOとGRPOを元にし、検索拡張推論のための最適化を加えている

ポリシーLLMのみを使ってロールアウトを生成するのが一般的だったが、本研究ではを用いて、検索を挟んだ推論を明示的に導入している。
PPOおよびGRPOの両手法では、トークンレベルの損失はロールアウト全体にわたって計算される。しかし、SEARCH-R1のロールアウトは、LLMが生成したトークンと、検索によって取得されたトークンの両方を含む。
LLM生成トークンに対する最適化は、検索エンジンとの効果的なインタラクションや推論能力の向上に寄与するが、取得トークンに同様の最適化を適用すると、望ましくない学習動作が生じるおそれがある。
この問題に対処するため、SEARCH-R1では取得トークンに対する損失マスキング(loss masking)を導入する。これにより、ポリシー勾配の目的関数はLLMが生成したトークンのみに基づいて計算され、検索結果は最適化から除外される。
⚠️ 上式からは簡略化のためか省かれている。
Generation with Multi-turn Search Engine Calling
本論文ではLLMがテキスト生成と外部検索を交互に行う反復的な枠組みを採用している。具体的には、システムインストラクションにより、LLMは検索が必要な場合に、検索クエリを と のトークンで囲んで生成するように誘導される。
このトークンが生成シーケンス中に現れると、システムはクエリを抽出して検索エンジンに送信し、該当する検索結果を取得する。そして、この取得結果は と のトークンで囲んで、現在進行中のロールアウトシーケンスに追加され、次の生成ステップの文脈として利用される。
このプロセスは以下のいずれかの条件を満たすまで繰り返される
- アクション回数の上限に達したとき
- 最終回答が生成され、それが と のトークンで囲まれたとき

Training Template
まずは初期のLLMにあらかじめ定義された指示に従わせるためのシンプルなテンプレートを設計する。
このテンプレートは出力を以下の3つの部分に構造化している
- 推論パート( と で囲む)
- 検索エンジン呼び出しパート( と )
- 回答パート( と )
Reward Modeling
最終的な出力の正しさのみに基づくルールベースの報酬設計を採用している。
DeepSeek-R1とは異なり、本研究では出力の形式に対する報酬は設けていない。これは、本モデルがすでに十分に構造に従った出力を行う能力を備えていることが確認されているためであり、複雑な形式報酬の設計については今後の課題とする。
さらに、DeepSeek-R1に従い、ニューラルネットワークによる報酬モデルの訓練も行っていない。この選択は以下の理由による:
- LLMは報酬の形式に対して過敏に反応するため、設計を誤ると学習が不安定になる可能性があること
- ニューラル報酬モデルの再学習には計算コストと実装の複雑さが伴うこと
結果
データセット
検索と推論の複合課題を広範にカバーすべく下記のデータセットを用いた
- 一般的な質問応答(General Question Answering)
- NQ(Natural Questions)
- TriviaQA
- PopQA
- マルチホップ質問応答(Multi-Hop Question Answering)
- HotpotQA
- 2WikiMultiHopQA
- Musique
- Bamboogle
ベースライン
- 検索なしの推論
- 直接推論(Direct inference)
- Chain-of-Thought(CoT)推論
- 検索ありの推論
- Retrieval-Augmented Generation(RAG)
- IRCoT
- Search-o1
- ファインチューニングに基づく手法
- 教師ありファインチューニング(SFT)
- 検索エンジンなしでRLによってファインチューニングされたもの(DeepSeek-R1の手法)
実験設定
- Qwen-2.5-3b (Base / Instruct) および Qwen-2.5-7B (Base / Instruct)を利用
- 検索には 2018年版のWikipediaダンプ。
- Retriever (Embedding)にはE5 (Text embeddings by weakly-supervised contrastive pre-training) を利用
- 手法比較の公平性を保つため、全ての検索ベースの手法で取得する件数を3件に固定
- NQとHotpotQAの訓練データセットを統合し、Search-R1および他のファインチューニングベースの手法の共通データセットとして利用
- 評価指標には Exact Match を使用
- 推論ベースのベースラインについては、Instructモデルを使用する。Baseモデルは指示に従えないため。RLによるチューニング手法に関してはBaseモデルとInstructモデルの両方で実験を行った
パフォーマンス

- SEARCH-R1は強力なベースラインを一貫して上回る
- Qwen2.5-7Bモデルで41%、Qwen2.5-3Bモデルで20%の平均相対性能向上を達成している。
- これは、インドメイン評価(NQ, HotpotQA)およびアウトオブドメイン評価(それ以外)の両方で確認されている。
- SEARCH-R1は、検索を含まない推論ベースのRL手法(R1)よりも優れている
- 検索を組み込むことで、関連する外部知識にアクセスできるようになり、性能が向上しているのは想定通りである。
- SEARCH-R1はBaseモデル・Instructモデルの両方で効果的である
- これは、DeepSeek-R1-ZeroスタイルのRL(成果ベースの報酬)が、検索を伴う推論にも適用可能であることを示している。つまり、純粋な推論タスクだけでなく、検索統合型推論にも拡張できることを意味する。
- より大きなモデルは、検索の仕方をよりうまく学習できる
- 特にQwen2.5-7Bモデルでは、RAGなどの次点モデルに対して大きな性能差が観測されており、7Bモデルのほうが3Bモデルよりも検索能力の学習に優れていることが示唆されている。
分析
PPO vs. GRPO

- GRPOは全てのケースでPPOよりも収束が早い
- PPOは critic model に依存しており、有効な学習が始まる前にウォームアップステップが必要であるため、初期の学習は遅い
- PPOはより高い学習安定性を示す
- GRPOは多くのステップを経た後に報酬の崩壊が起きるのに対し、PPOは安定して推移している
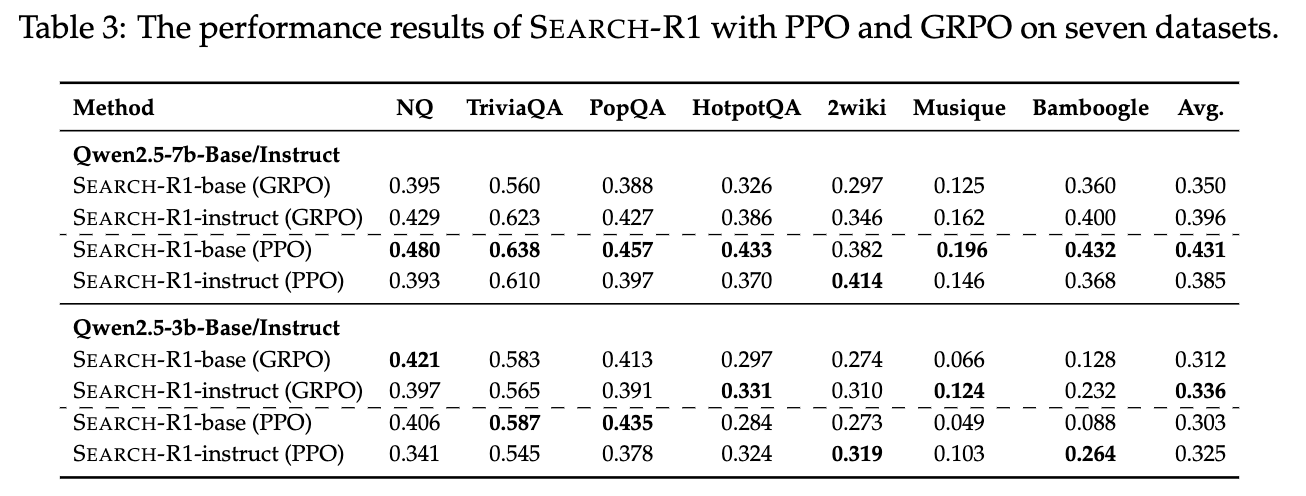
- 収束スピードや安定性に差があるものの、最終的な報酬や性能には大きな差はなかった
- 安定性に優れるPPOが、この実験設定においては望ましい選択だといえる
Baseモデル vs. Instructモデル

Instructモデルの方が収束が早く初期性能も高かったが、最終的な報酬はほぼ同等。
下記のことが示唆される
- Instructモデルのような post-training は推論+検索の学習において初期の加速には有効
- RLは時間をかけてその差を埋めることが可能であり、Baseモデルでも十分な性能に達することができる
応答長と有効な検索呼び出しに関する分析

- 初期段階(最初の100ステップ)
- 応答長は急激に短くなり、報酬はわずかに上昇
- ベースモデルが不要な冗長語を削減し、タスク要件への適応を開始している
- 後期段階(100ステップ以降)
- 応答長および報酬はともに大きく増加
- モデルは検索エンジンを頻繁に呼び出すことを学習し、取得パッセージの影響で応答が長くなる
取得トークンの損失マスキングに関する検証

検索エンジンから取得したトークン部分に関するマスキングの効果比較。
マスキングをした方が意図しない学習効果を抑制しつつ安定した訓練を実現できている。
結論
従来のRAG的手法がマルチターン検索のために長いプロンプトに依存していたり、ツール使用型の手法が大規模な教師ありデータを必要としていたのに対し、Search-R1はRLによってロールアウトを最適化することで、自律的なクエリ生成と戦略的な情報利用を可能にしている。
7つのデータセットにおける広範な実験を通じて、Search-R1がリアルタイム外部知識を必要とする複雑な推論タスクにおいてLLMの能力を大きく向上させることを示した
今後の展望としては、SEARCH-R1を以下の方向に拡張することが考えられる
- より洗練された報酬設計
- 不確実性に応じた動的な検索調整
- 多様なツールとの連携
- 検索以外の多様な情報源との統合
- マルチモーダル推論タスクへの応用可能性の検討