
2025-05-26 機械学習勉強会
今週のTOPIC[blog] 日本語ModernBERTの開発[slide]生成検索エンジン最適化に関する研究の紹介[blog] vLLMのSpeculative Decodingによる推論高速化を試す[論文] AGENTIF: Benchmarking Instruction Following of Large Language Models in Agentic Scenarios[blog] Webスケールの日本語-画像のインターリーブデータセット「MOMIJI」の構築 /巨大テキストデータをAWSで高速に処理するパイプラインAIによる画像認識技術の進化 -25年の技術変遷を振り返る-[blog]情報検索のための質問文作成モデル query-crafter-japanese を公開[論文] MMaDA: Multimodal Large Diffusion Language ModelsFast Inference from Transformers via Speculative DecodingAIによる3行まとめ1. Introduction2. Speculative Decoding3. AnalysisNumber of Generated TokensCalculating \alphaWalltime ImprovementNumber of Arithmetic Operations (算術演算数)Choosing \gammaApproximation Models4. Experiments4.1. Empirical Walltime Improvement(経験的ウォールタイム改善)4.2. Empirical α Values(経験的α値)6. Discussion
今週のTOPIC
※ [論文] [blog] など何に関するTOPICなのかパッと見で分かるようにしましょう。
技術的に学びのあるトピックを解説する時間にできると🙆(AIツール紹介等はslack channelでの共有など別機会にて推奨)
出典を埋め込みURLにしましょう。
@Naoto Shimakoshi
[blog] 日本語ModernBERTの開発
- 開発と評価編
- Sarashinaで得た知見をオリジナルのModernBERTに加えて取り込んでる
- LLMの事前学習において、Weight decayの値は0.1の方が一般的な値であるため変更
- 安定して学習、かつでかいほどちゃんと性能が良い
- ……..
- 学習Phaseを進めるに従ってFinetuningの精度も着実に向上してる
- 一般に、サイズの大きなモデル・よく学習されたモデルの方が、fine-tuning時の学習率は小さい方がよく、今回のモデルも学習率は低いほうがいいらしい (1e-05)
- 推論速度も長いテキスト長のものだと結構差がある
- 東北大BERT-baseと310Mモデルが同等の処理効率
* 系列長拡張: Phase 2におけるマスク率を30%から15%に下げることで、モデルの性能が向上することを確認 * weight decayを0.1に設定 (オリジナルは1e-5または1e-6と非常に小さい)

「事前学習フェーズ」にかかった時間は、310MモデルがNVIDIA H100を256枚使用して約70時間、130MモデルがNVIDIA A100を128枚使用して約120時間でした。モデル構築においては、HuggingfaceのAccelerateやDeepSpeed (ZeRO 2)などを用いました。 今回構築したモデルは、LlamaやSarashinaのようなデコーダ型のLLMと比較すると極めて軽量であり、4T tokens程度の事前学習でも高速に完了しました。


- 分析編
- 開発と評価編で語られていたMask率の分析
- JCoLAやJNLIといった「日本語の理解力」を問うタスクにおいては既存モデルよりも性能が低かった → Phase2に訓練時間を伸ばすという手を入れた
- 事前学習 → Phase1ではあまり性能が改善しない。Phase1では英語データセットも含めて学習してるので、日本語特化で学習させた方が最終精度が良くなるっぽい。
- 小規模LMとの性能比較
- 以下のモデルで実験
- sarashina2.1-1b
- plamo2-1b
- LLM-jp-3シリーズ
- Sarashina 2.2シリーズ
- 一切文生成をせず、SLMを分類モデルとしてfine-tuningする
- 一貫してModernBERTの方が精度が高い
- SLMを双方向化した上での実験
- Encoder型のようにして扱う。このような研究は増えてるらしい。
- BehnamGhader et al., LLM2Vec: Large Language Models Are Secretly Powerful Text Encoders. COLM 2024
- Lee et al., NV-Embed: Improved Techniques for Training LLMs as Generalist Embedding Models. ICLR 2025 (spotlight)
- LLMの日本語化はベクトル表現にも有効か?LLM2Vecにおける日本語ドメイン適応の効果
- テキスト埋め込みモデルPLaMo-Embedding-1Bの開発
- 双方向にすることで性能は落ちてしまっている。単純にやるのではなく、LLM2Vecのように追加事前訓練が必要かもとのこと。



- トークナイザと性能の関係編
- 結論
- 日本語ModernBERTは事後的にトークナイザを改造することで形態素解析器を簡単に追加できる
- 日本語ModernBERTは事後的にトークナイザを差し替えても性能への影響が小さい
- 日本語ModernBERTは固有表現認識タスクでも高い性能を達成する
- Mecabを前に入れるのか問題
- 既存のモデルはさまざまな形態素解析器を使ってる
- を使って事後的に分かち書きを入れてみる
- トークナイザの変化に頑健と言える
- 固有表現認識タスクでの評価
- Mecabで予め分かち書きされてるため、若干不利ではあるがbert-largeに健闘




@Yuya Matsumura
[slide]生成検索エンジン最適化に関する研究の紹介

- 生成検索エンジンとは、クエリに対してランキングではなく、回答となる生成結果を示すもの。
- 評価指標が定まってないの問題だよね頑張ろう。

- 提案したよ。シンプルにいっぱい引用されていて、かつそれが先頭であれば嬉しいという指標。

- その上で評価したら、引用入れたり統計情報追加するのが良かったよ。キーワード詰め込んだりしても微妙だったよ。

- でもプロンプトインジェクション(詳細不明・自動生成している)もできちゃうよ


@Shun Ito
[blog] vLLMのSpeculative Decodingによる推論高速化を試す
- (メインと被ってしまった。。。)
- 参考: ‣
- Speculative Decoding: 大型モデルの推論を、小型モデルを使って高速化する方法
- 本来の出力を得たい大型モデルと、出力傾向の似ている小型モデルを用意する
- 例: LLaMa3 70B と LLaMa3 7B
- 小型モデルで数トークンを生成
- 例: The quick brown fox jumps
- 大型モデルに一通り入力し、fox jumpsが最適かどうかを判定する
- fox jumpsがlogits的に最適 → そのまま採用し、次のoverも採用する
- jumpsが最適でない → foxだけ採用し、jumpsを最適なものに修正する
- 続きは再び小型モデルの生成から始める
- 大型モデルで2回生成したところを小型2回+大型1回で処理できて高速になる
- 小型の生成個数を増やすほど、途中で間違ってやり直しになる可能性も高まるので、3個くらいが適当

- 実験
- 大型モデル → Qwen3-32B、小型モデル → Qwen3-0.6B, Qwen3-1.7B
- 指標
- Output Throughput: 出力トークン数 / 秒。Higher is Better
- Time Per Output Token: TTFTを除いた1トークン出力の間にかかる時間。Lower is Better
- TTFT (Time To First Token): 最初のトークン生成までにかかった時間。Lower is Better
- 結果
- (図を載せていないが)他の結果を含めてみるとspec_tokens=2, 3あたりが良い
- 1.7Bが良さげ。concurrencyが上がるとbaseline(素の出力)が上回る
- 1.7Bが良さげ。concurrencyが上がるとbaseline(素の出力)が上回る
- 一貫してbaselineがよかった。最初の1トークンはどうしてもステップ数が増える




@qluto (Ryosuke Fukazawa)
[論文] AGENTIF: Benchmarking Instruction Following of Large Language Models in Agentic Scenarios
Yunjia Qi¹*, Hao Peng¹*, Xiaozhi Wang¹, Amy Xin¹, Youfeng Liu², Bin Xu¹, Lei Hou¹, Juanzi Li¹
¹Tsinghua University ²Zhipu AI
Agentシナリオは、拡張されたシステムや詳細なツール仕様など、複雑な制約を含む長い指示を伴うことが多い。
こういったシナリオにおける、LLM の指示に従う能力を体系的に評価するための最初のベンチマークである AgentIF についての論文。
コードとデータセットの両方が公開されている。
ベンチマークの特色
- 現実的:50件の実際のエージェンシー・アプリケーション事例から構築。
- 長大:指示は平均1,723語(最大15,630語)に及ぶ。
- 複雑:平均11.9個の制約を含み、ツール仕様や条件付き制約など多様なタイプを網羅。
データセット構築プロセス

- 指示収集:GitHub上の40種のオープンソースエージェントと、産業向けエージェント10種からシステムプロンプトを取得し、GPT-4oを用いて各約20問のユーザークエリを生成。その後、人手でリライト・フィルタリングを実施し、高品質な707件の指示セットを得ています。
- 制約抽出・注釈:長大で構造化された指示をブロック単位に分割し、GPT-4oで制約を抽出、さらに人手検証を加えて合計8,415個の制約を高精度にアノテーション。
- 評価スクリプト生成:各制約に対し、簡易コード検証、LLM検証、ハイブリッド方式のいずれかで自動評価できるようスクリプトを生成・精査。
評価指標
- CSR(Constraint Success Rate):全制約のうち満たされた制約の割合
- ISR(Instruction Success Rate):全制約を完全に満たした指示の割合
実験結果
GPT-4oをはじめとする20超の最先端モデルを評価したところ、最高モデルでもCSR約60%、ISR約27%に止まり、特に条件制約とツール制約で著しい性能低下が見られた。
また、In-Context Learningが効く例示制約では比較的高い成功率を示す一方、条件判断や仕様遵守には大きな課題が残ることが分かった。
@Yosuke Yoshida
[blog] Webスケールの日本語-画像のインターリーブデータセット「MOMIJI」の構築 /巨大テキストデータをAWSで高速に処理するパイプライン
- MOMIJI (Modern Open Multimodal Japanese filtered Dataset) は,大規模かつ厳選された,画像とテキストが交互に現れるWeb文書の公開データセット
- 2024 年 2 月から 2025 年 1 月までの Common Crawl から抽出
- 約 5,600 万 (56M) 件の日本語文書,約 1,100 億 (110B) 文字,約 2 億 4,900 万 (249M) 枚の画像
- 類似した他の画像-テキストデータセットと比較した表

- 課題
- 元となるデータセットが巨大であり,取り回しづらい
- 画像やテキストを大量にダウンロードし解析する必要がある
- ひとつひとつのフィルタリングが軽くても,処理対象のファイル数が膨大
- 多段なフィルタリングを順番に管理し実施していく必要がある
- GENIACの限られた期間内でデータセットを完成させる必要がある
MOMIJI構築のパイプライン (AWS Lambda + Step Functions, Batch)

- 実行
- 4,000並列でLambdaを実行
- 画像ダウンロードを含めても1スナップショットあたり6〜8.5時間
- 1 スナップショットで100TiB
- MOMIJIは実際には11スナップショットで構築される大規模なデータセットでありながら,計算時間としては4営業日程度で処理が完了
- うまくいかなかったこと
- いくつかのライブラリがLambda環境や特定のPythonバージョンでは動かない
- LambdaではPythonの並列処理関連は実行環境レベルで利用できないようになっていますが,ライブラリによっては要求してくるものもありました
- 最終的にはDockerfileやモンキーパッチを書くことで解決
@Takumi Iida (frkake)
AIによる画像認識技術の進化 -25年の技術変遷を振り返る-
藤吉先生による画像認識の25年まとめ
ハンドクラフト特徴からCNN、ViT、VLMまでかなり広範にまとめられている
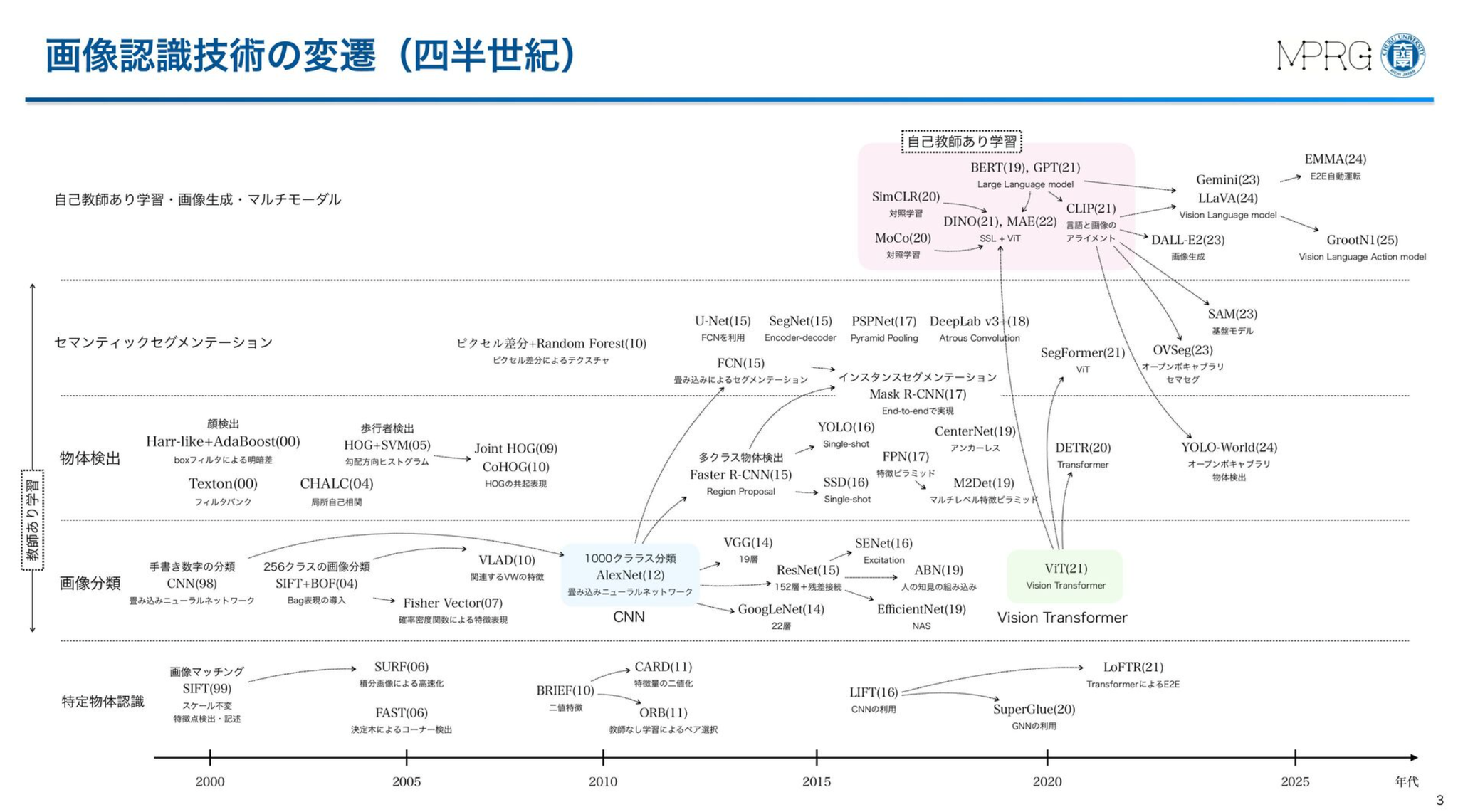
ハンドクラフト特徴
テンプレートマッチング
SIFT特徴量を使ったテンプレートマッチング



ローテクスチャでもいけるようになる

ハンドクラフト特徴
Joint Haar-likeとかJoint HOGとかは知らなかった

ミドル:ほどほどにローカル特徴を組み合わせて認識する
Joint Haar-likeとかJoint HOGとかは知らなかった

グローバル:ローカル特徴をがっと組み合わせて認識する

VLMについて
画像とテキストをペアで学習するもの(CLIP系)
なぜゼロショットのクラス分類ができるのかが視覚化されてて面白い



他にもLLaVA系やGemini系に言及あり
Gemini系のWaymoが開発したEMMAだと、大量のデータで事前学習したあとに自動運転データでFTすると良く、さらにChain-of-thought Promptingでプランニングを段階的にやると良いとのこと
Chain-of-thought Promptingの例

@Hiromu Nakamura
[blog]情報検索のための質問文作成モデル query-crafter-japanese を公開
情報検索におけるニューラルネットワークモデル学習に必要な「質問文と回答文のペア」を効率的に生成するためのquery-crafter-japaneseというオープンソースモデルが公開。

解決するもの
商用LLMでのデータ生成におけるライセンスやコストの課題
何をした
小型ながら高性能でApache 2.0ライセンスのquery-crafter-japaneseが開発できた。このモデルは、与えられたテキストからキーワード、質問文、タイトル、要約など7種類の質問カテゴリーを生成できる。大量のデータ処理において速度と費用面で大きな優位性を持つことが示されている。学習には制限のないDeepSeek-R1を用いて教師データを作成し、Qwen3でファインチューニングを行った結果、多くのケースでDeepSeek-R1を上回る性能を発揮。(ともあれ、DeepSeek-R1で生成したデータセットでDeekSeek-R1の評価をするのってありなんだっけ?
BAAI/bge-reranker-v2-m3で評価(CrossEncoder系のモデルhttps://secon.dev/entry/2024/04/02/080000-japanese-reranker-tech-report/

DeepSeek-R1 他よりスコアが低いからといって必ずしもDeepSeek-R1の質問文の質が悪いというわけではなく、リランカーでも判別が難しいような「正しく難しい質問文」を作成しているケースもあるとのこと
感想
LLMで自社サービス特化や独自ドメイン特化の検索データセットを作る場合は、商用LLMで金と時間をかけて頑張るという感じだった(俺もそういうトライはしたし、技術書典でもこのテーマで書いた)ので、このようにローカルLLMベースで学習して突破できるのは夢がある。
@ShibuiYusuke
[論文] MMaDA: Multimodal Large Diffusion Language Models
- GitHub: ‣
- HuggingFace demo: ‣
- Diffusionによるマルチモーダル統一基盤モデル(テキスト、画像)。MLLM(Multimodal Large Language Model)or VLM(Vision Language Model)。
- しかし論文ではモデルアーキテクチャは論じてくれてない。GitHubを参照。


- 統一されたトークン:テキストデータと画像データを一貫した離散トークン化により、共通のモデルリング目的、prediction of discrete masked tokens。
- 統一された目的関数による事前学習、ポストトレーニング
- Mixed Long Chain-of-Thought FineTuning:
- UniGRPO

- Multimodal understanding、Text-to-image generation、Textual reasoning、Inpainting、Extrapolation

- Synergy across various tasks

Fast Inference from Transformers via Speculative Decoding
- Yaniv Leviathan, Matan Kalman, Yossi Matias
AIによる3行まとめ
- Speculative Decodingは、大規模なTransformerモデルの推論を高速化する手法で、複数トークンを並列に生成・検証することでシリアルな実行回数を削減します。
- 軽量な近似モデルで候補トークンを生成し、高精度なモデルで検証・補正することで、出力を変えずに2〜3倍の速度向上を実現します。
- モデルの再学習や構造変更が不要で、T5-XXLなどの既存モデルでもそのまま利用可能です。
1. Introduction
- 大規模自己回帰モデルは高性能である一方、デコーディングが逐次的なため推論が遅い
- 推論高速化のための様々な手法が開発されてきたが、多くはモデルアーキテクチャや学習手順の変更、モデルの再学習が必要であり、元のモデルと同一の出力を維持しない
- 本研究の動機は、推論ステップに「難しい」ものと「簡単な」ものがあるという点に加え、大規模モデルの推論ボトルネックがしばしば計算リソースではなく、メモリ帯域幅や通信にあるため、追加の計算リソースが利用可能であるという点
- 本研究では、モデルや学習手順を変更せず、出力分布を維持したまま投機的実行を利用して推論を高速化する手法を提案
2. Speculative Decoding
- ターゲットモデル と近似モデル
- ターゲットモデル は、推論を高速化したい大規模で低速なモデル
- 近似モデル は、同じタスクに対してより効率的な(小さな)モデル
- 投機的デコーディングのコアアイデア
- 効率的な近似モデル を使用して 個の候補トークンを自己回帰的に生成
- 次に、ターゲットモデル を使用して、生成された候補トークンを並列に評価し、受け入れ or 拒否
- 最初に拒否された推測を修正するため、または全ての推測が受け入れられた場合に新しいトークンを追加するために、調整された分布から追加のトークンをサンプリング
- 投機的サンプリング (Speculative Sampling)
- ターゲットモデル の分布 から直接サンプリングする代わりに、まず近似モデル の分布 からトークン をサンプリング
- もし ならそのトークンを受け入れる
- もし なら確率 でそのサンプルを拒否
- 拒否された場合、調整された分布 から再度サンプリング
- この方法でサンプリングされたトークンは、ターゲットモデル から直接サンプリングされた場合と同一の分布に従うことが理論的に保証されている
- A.1. Correctness of Speculative Sampling 参照
- アルゴリズムの実行ステップ

- 近似モデル で 個のトークン を自己回帰的にサンプリング
- 元のprefixと各トークンを追加したコンテキストに対してターゲットモデル を並列で実行し、それぞれのステップでの確率分布を取得
- 各推測 に対して、一様分布 から乱数 をサンプリングし、もし であれば、その推測 とそれ以降の推測を拒否 (受け入れられた推測の数を )
- 受け入れられた最後の推測の次の位置に対応する からの分布 を取得
- もし であれば (つまり、少なくとも1つの推測が拒否)、分布を調整
- 調整された分布から最後のトークン をサンプリング
- 受け入れられた 個のトークンとサンプリングされた最後のトークンを結合して返却

- 各行はアルゴリズムの1回のイテレーションを表す
- 緑色のトークンは、近似モデルが行った提案のうち、ターゲットモデルが受け入れたもの
- 赤色のトークンは拒否された提案であり、青色のトークンはそれらの修正
- 例えば、最初の行ではアルゴリズムの一回の実行で5つのトークンが生成
3. Analysis
Number of Generated Tokens
- 定義3.1 受理率
- prefix が与えられた場合の受理率 は Speculative Samplingにより を受理する確率
- は がどの程度 に近似しているかの自然な尺度
- もし、 が独立同分布であるという単純な過程を置き、 と表記するとアルゴリズム1回の実行で生成されるトークン数は成功確率 で上限 の幾何変数となる
Calculating
- 定義3.2 ダイバージェンス
- where
- が小さい → 分布が似ている
- 補題3.3
- 定義3.2より (証明略)
- 定理3.5
- Speculative Samplingの期待値より (証明略)
- 系3.6

Walltime Improvement
- 独立同分布の仮定のもとで、我々のアルゴリズムがターゲットモデル呼び出しを 倍に削減することを示した
- walltime解析にあたり十分な計算リソースがあり、ターゲットモデル の 個の並列評価を、ウォールタイムを増加させることなく並列実行できると仮定
- 定義3.7
- コスト係数 を 1回の実行時間と 1回の実行時間の比
- = の実行時間 / の実行時間
- はハードウェアやソフトウェアの実装に依存する
- 実験では は より数桁小さく は常に0.05未満
- 定理3.8
- walltimeの期待改善率は
- 生成されるトークン数の期待値より (証明略)
- 系3.9
- もし なら、改善が得られる が存在し、その改善係数は少なくとも となる
- 証明 もし に対して改善が得られるならば の任意の に対しても改善が得られるため、 に対して定理3.8を評価することができる
Number of Arithmetic Operations (算術演算数)
- アルゴリズムは を 回 並列実行するため算術演算数は 倍になる
- アルゴリズムは1回の実行で最大 トークンを生成するため、推測を拒否する場合は計算が無駄になる
- 定義3.10
- を近似モデル のトークンあたりの算術演算数とターゲットモデル のトークンあたりの算術演算数との比率とする
- 定理3.11
- アルゴリズムの総演算数の期待される増加係数は
- 生成されるトークン数の期待値より (証明略)
- が低い場合、算術演算数の増加係数は大きくなる
- 算術演算数とは異なり、メモリアクセス数は減少する可能性がある
- ターゲットモデルの重みとKVキャッシュはアルゴリズムの実行ごとに1回読み込まれるため、それらを読み込むためのメモリアクセス数は、生成されるトークン数の期待値 の係数で減少する
Choosing
- と が与えられ、十分な計算リソースがあると仮定すると、最適な はwalltimeの期待改善率 を最大化
- Figure 3. は様々な の値に対する の関数としての最適な

- Table 1. と Figure 4. は と仮定した場合の、様々な と の値に対する推論速度と総算術演算数のトレードオフを示す
- 近似モデル の実行にかかるコストが、ターゲットモデル の実行にかかるコストと比較して無視できるほど小さいという理想的な状況


Approximation Models
- 投機的サンプリング、そしてそれに基づく投機的デコーディングは、近似モデル をどのように選択しても、ターゲットモデル と同一の出力分布を保証する
- 実験では主にターゲットモデル と同じアーキテクチャを用いたより小さなTransformerモデルが使われ、 を よりおよそ2桁小さく選択することが、推測の受理率 とコスト係数 のバランスをとるうえで最も良い結果を示した
- 近似モデルの別の種類として、コストが無視できるモデル (negligible-cost models) が挙げられる ()
- 例えば、T5-XXL 11B をターゲットモデル、bigramモデルを近似モデルとした英語からドイツ語への翻訳タスクでは、 となり、 の場合に1.25倍に推論速度が向上
- 他の単純なヒューリスティクスも、コストが無視できる近似モデルとして使用可能
- 例えば、要約やチャットのような、長いシーケンスが繰り返されやすいタスクでは、一致するprefixが見つかった場合に単にコンテキストからトークンをコピーする近似モデルが、高い α 値をもたらす可能性がある
- これらのパラメータを持たない近似モデルは、本番環境への展開がさらにシンプル
- 理論的な観点から興味深い例として、ランダムにトークンを選択する近似モデルもあり、これは全てのターゲットモデルに対して(非常に小さいながらも)何らかの改善を保証する
4. Experiments
4.1. Empirical Walltime Improvement(経験的ウォールタイム改善)
セットアップ
- 実験には、T5論文で使用されている2つのタスクを選択
- WMT EnDeでファインチューニングされた英語からドイツ語への翻訳タスク
- CCN/DMでファインチューニングされたテキスト要約タスク
- ターゲットモデル は両タスクともT5-XXL (11B) を使用
- 近似モデル はT5-large (800M), T5-base (250M), T5-small (77M)
- walltimeの改善率は、単一のTPU-v4上でバッチサイズ1で測定
- 評価は、argmaxサンプリング (温度設定temp=0) と標準サンプリング (温度設定temp=1) の両方
結果
- Table 2. は実験結果
- テストされた近似モデルの中で、T5-small (77M) が最も高い速度向上を示した
- 予想通り近似モデルのサイズが大きくなるにつれて、 も増加する傾向が見られた
- 興味深い発見として、argmaxサンプリング (temp=0) の方が、 値およびwalltime改善率が共に高くなる傾向が見られた
- 具体的な速度向上率は、翻訳タスクで2.6倍 (temp=1) および3.4倍 (temp=0)、要約タスクでは2.3倍 (temp=1) および3.1倍 (temp=0)

4.2. Empirical α Values(経験的α値)
異なるモデル、タスク、サンプリング方法における経験的な 値(推測受理率)の測定結果
GPT-like (97M)
- 非条件的な言語生成タスク
- としてlm1bで学習されたGPT-likeモデル
- として6Mパラメータを持つTransformerデコーダーモデルと、単純なunigramおよびbigramモデル
LaMDA (137B)
- 対話タスク
- としてLaMDA 137B
- としてLaMDA (8B, 2B, 100M)
T5-XXL (137B)
- 4.1参照
結果
- Table 3. は測定された 値
- ターゲットモデルより数桁小さい近似モデルは、0.5から0.9の間の 値を生成する傾向
- すべてのモデルについて、 (argmax) の方が よりも 値が大きくなる
- unigramおよびbigram近似でも、無視できない 値が得られる
- 例えば、英語からドイツ語への翻訳タスクにおいて、ターゲットモデルがT5-XXL 11B、近似モデルがbigramモデルの場合、 値は0.2
- この場合のコスト係数 はほぼ0であるため、 で1.25倍の推論速度向上

6. Discussion
- 投機的実行全般、特に投機的デコーディングの限界
- レイテンシの改善が演算数の増加を代償とする並列性の増加によって達成される点にあり、追加の計算資源が利用できない構成では、この手法は役に立たない
- 追跡調査すべき方向性
- ビームサーチへの投機的デコーディングの適用
- カスタム近似モデルによるより大きな改善の可能性
- 近似モデル自体がさらに高速なモデルによって高速化される階層的なバージョンのアルゴリズム
- 推論全体を通して近似モデルと推測数 を固定するのではなく、それらを変動させることによる追加の改善
- 近似モデルによって生成される分布に対して異なる変換を適用
- テキストモダリティ以外のドメイン(画像など)でのテスト
- 確率的投機的実行および投機的サンプリングは、自己回帰モデルからの投機的デコーディングの範囲外でも役立つ可能性
- 例えば、互いに依存する遅い関数を並列に実行する場合など