
2025-06-03 機械学習勉強会
今週のTOPIC[論文] Qwen2.5-32B/7B の日本語継続事前学習[blog] LLMの他言語混ざり問題の評価と日本語追加学習の効果について[blog] FM-Intent: Predicting User Session Intent with Hierarchical Multi-Task Learning[oss] huggingface/nanoVLM[Tips] PyTorchにおける動的リンクLangChainでPrompt Cachingが利用されていることを確認する [論文]AgentA/B: Automated and Scalable Web A/BTesting with Interactive LLM Agents[論文] What Prompts Don’t Say: Understanding and Managing Underspecification in LLM PromptsメインTOPICDynamic Multimodal Evaluation with Flexible Complexity by Vision-Language Bootstrapping概要データ汚染の調査Dynamic Multimodal Evaluation (DME)実験
今週のTOPIC
@Naoto Shimakoshi
[論文] Qwen2.5-32B/7B の日本語継続事前学習
- 既にブログなどでも詳細が多数公開されているが、改めて論文でJSAIで発表されていたABEJAさんの事例
- Qwen2.5-32B-InstructとQwen2.5-7B-Instructに対して日本語継続事前学習した事例
- 日本語: 英語: コードを 7:2:1 の割合で混在させた約 100B トークン規模のデータセットで学習。
- 品質フィルタリングとしてQwen2.5-72B-Instructで品質スコアと33個のカテゴリを付与してからDeBERTaで学習
- 高品質なデータにした後にさらにQwen2.5-72B-InstructでInstructionデータ作成
- ChatVectorをQwen/Qwen2.5-32B-Instruct とQwen/Qwen2.5-32Bの間に得られる差分をもとに生成。
- ChatVectorとは → https://soysoftware.sakura.ne.jp/archives/3823
- おそらくこれが原因で中国語が混じってしまうといった問題も
- 結果
- 元モデルよりは日本語タスクでは高い性能
- こう見るとgpt-4o強いなあ。。

@Shun Ito
[blog] LLMの他言語混ざり問題の評価と日本語追加学習の効果について
- 日本語の生成結果に中国語が混ざってしまう問題を検証(中国語独自の文字がどれくらい含まれているかで計測)
- 元のQwenではモデルが大きいほど混ざりにくくなる
- 継続学習・PostTrainingによって含有率が低下する傾向が得られている

- 例
- 含有率1%程度
- 含有率5%程度
- 含有率10%程度
@qluto (Ryosuke Fukazawa)
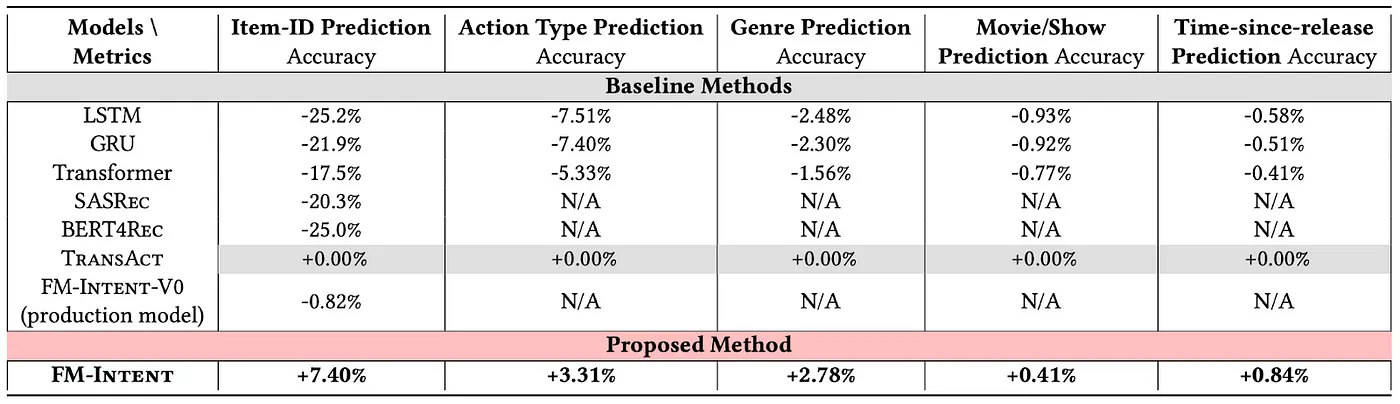
[blog] FM-Intent: Predicting User Session Intent with Hierarchical Multi-Task Learning
Netflix による Foundation Model for Personalized Recommendation の続編。
推薦するコンテンツを encoder ベースのモデルにて next-token-prediction と同じ構図でつくろうというのが上記ブログの内容。この考えのもと作られたモデルを推薦用の基盤モデルとして扱い、露出させる面によって fine-tuning するだけでやや異なる要求性能を見たしたいという期待があった。
FMと略されているが、Factorization Machines ではなくて Foundation Model である。
以前のブログ内容をさらに発展させたのが今回取り上げる FM-Intent。
これまでのFMではユーザーの興味(User Intent)を短期・長期などにわけて明示的かつ多層的に表現することができない。


- 入力特徴シーケンスの形成
カテゴリ埋め込みと数値特徴を組み合わせ、ユーザー行動の包括的な表現を作成
- ユーザー意図予測
マルチヘッドアテンションメカニズムを通じて、ユーザーの長期的な関心を効果的にモデル化
- 階層的マルチタスク学習による次のアイテム予測 入力機能とユーザーの意図の埋め込みを組み合わせて、より正確な次のアイテムの推奨を作成
@Yosuke Yoshida
[oss] huggingface/nanoVLM
- 軽量かつシンプルなコードで実装されたVLM
- ViTは google/siglip-base-patch16-224、LMは HuggingFaceTB/SmolLM2-135M
- 1000行くらいで書かれているので学習用によさそう

@Takumi Iida (frkake)
[Tips] PyTorchにおける動的リンク

pipからインストールしたpre-built PyTorchはcudaやcudnn系のパッケージを一緒にインストールして利用する。そのため、ランタイムにCUDAのバージョンとかを変えてもPyTorchが利用するバージョンは固定される。
一方、ソースビルドするPyTorchはビルド時に、(当然)CUDAなどのライブラリを参照できるようにする必要がある。pre-built版と違い、ランタイムの時のCUDAバージョンなどは(互換性があれば)その場で動的に変更できる。
LangChainでPrompt Cachingが利用されていることを確認する
プロンプトキャッシュって初めて知りました。
システムプロンプトや一般的な指示などの繰り返し仕様されるコンテンツがありますが、プロンプト内で接頭辞が一致した場合に自動的に適用されるみたいです。
参考:‣
キャッシュできるもの
- Messages
- Images
- Tool Usage
- Structured Output
この記事はそれがほんとに機能しているのかをチェックしていて、利用イメージが湧きやすいなと感じました。レスポンスの から何トークンがキャッシュされているのかがわかるらしい。
1回目の実行
2回目の実行
画像でもできます。
感想:プロンプトの接頭辞のところをできるだけ使い回せるようにすると利用トークン数を減らせるのは割と使い道がありそう。
@Hiromu Nakamura
[論文]AgentA/B: Automated and Scalable Web A/BTesting with Interactive LLM Agents

何これ
LLM Agentを大量に生成してユーザーのアクションを行わせてABテストをする試み
課題
- 大規模なユーザー数とトラフィックへの依存
- ニッチな市場やトラフィックの少ない新しいウェブサイトにとっては問題
- 早期のフィードバックが得にくい
- デザインを繰り返し改善するための早期ユーザーフィードバックを得ることが困難

次の情報からAgent生成
- エージェントの数
- ターゲットユーザー層の定義/ペルソナ属性
- 人口統計学的分布/多様性:年齢、教育レベル、技術リテラシーなど。
- ペルソナ: 経済状況、ショッピング習慣、職業生活など。
- ユーザーの意図 (user intentions) または ショッピングの目標
- (例:「30ドル以下の割引されたBluetoothスピーカーを探す」)
各エージェントに与えるもの
- WebからHTMLを持ってきて不要な要素をJSで除去(これの用意めんどいな)
- 可能なアクション空間定義(click, searchなど)
LLMが指定した操作をAction Execution Moduleが実行(ChromeDriver等で)
結果
んー。ユーザーを模倣できたとは言えない。

6.3より
エージェントの行動は、より広範な探索と気軽なブラウジングを示すことが多い人間のユーザーと比較して、より決定論的で、集中的で、効率的である傾向がありました。 LLMエージェントによって生成される行動軌跡と推論は、ユーザー行動の完全な複製として解釈されるべきではなく、ユーザー行動の網羅性と一貫性を重視した構造化された近似として解釈されるべきである。
マルチモーダル情報認識とかはやってこうとしてるみたい。あとはLLMの向上にBetしてる感ある。
@ShibuiYusuke
[論文] What Prompts Don’t Say: Understanding and Managing Underspecification in LLM Prompts
- GitHub repo: ‣
- LLMを用いたソフトウェア開発における、Promptの指示不足の問題を分析した論文。
- 自然言語で要件を伝える場合、LLMがユーザ要件を完全に捉えられているとは限らず、不完全な仕様のソフトウェアができあがる。
- 結果として、ユーザ体験の悪化、アプリケーションの失敗、LLMの振る舞いの不安定性となる。

- 仕様の言語化不足のときのLLMの振る舞い
- LLMは指示不足の内容を予想することができるが、不安定。
- 不完全なPromptでは、モデルやPromptの更新に対してパフォーマンスが回帰する可能性が上昇。
- 指示されていないことを予測することは難しい。
- だからといって、必要な指示を一度にすべて書いても、LLMはそれらに対応するのは難しい。



- Requirements-Aware Prompt Optimization
- COPRO-R:COPROの改善版。平均で4.8%(COPRO単体と比較して+5.8%)の精度向上。
- Bayesian:平均で3.8%の精度向上、トークン使用量を41%〜45%削減。
- 今後の発展
- 要件の発見(Discovery)
- 要件の評価(Curation)
- 検証器自体の検証(validating the validators)LLM-as-a-judgeのアライメント
- 要件の監視(Monitoring)
- .
メインTOPIC
Dynamic Multimodal Evaluation with Flexible Complexity by Vision-Language Bootstrapping
ICLR2025 Oral

概要
- LVLMは一般的なベンチマークで優れた性能を達成するようになってきている
- ベンチマークに関する課題
- データ汚染: LVLMはインターネットから作られた大規模データセットで事前学習している。多くの評価ベンチマークも同じソースから構築されているので、学習・評価でデータが重複している可能性が高い(図に実例あり)
- 複雑性が固定化されている: ベンチマークの持っているデータは静的なので、複雑性が固定化され、ベンチマーク上で高い性能に達しているVLVMを様々な側面から評価できているとは限らない

- 動的な評価が可能なVision-Language Bootstrapping (VLB) を提案
データ汚染の調査

画像の汚染
- 事前学習データの画像と、ベンチマークの画像とを比較し、似ているものを確認
- 比較にはCLIPScore(画像同士の距離)を利用
- CLIPScoreが0.9を超えると、視覚的にかなり似た画像になる
- 0.9を汚染かどうかの閾値とすると、3割前後、多くて8割の汚染が確認された。
画像・テキストの汚染
- 汚染されていると判定された画像ペアについて、ベンチマーク側の画像+訓練側の画像で答えを推定できる(by GPT-4)かどうかで判定
- 2割前後の汚染が確認された。
Dynamic Multimodal Evaluation (DME)
概要
- 問題設定: から を生成する
- I, Q, AはそれぞれImage, Question, Answer
- DMEにおけるChallenge
- 汎用性: 特定のタスクに限定されない
- 正当性: 元の回答が正しいままである
- 柔軟な制御: LVLMの性能に合わせて複雑性(難易度)を調整できる
提案: Vision-Language Bootstrapping (VLB)

- 画像のブートストラップ
- 3種類の編集を入れ込む
- : 新しいオブジェクトの追加
- GPT-4VでAnswerを変えずに追加できるオブジェクトの名前・bboxペアを複数作成
- PowerPaintでオブジェクトを追加
- ‣
- : 既存オブジェクトの削除
- SAMで画像中の物体を特定し、通し番号をつける
- GPT-4Vに削除可能な物体とその番号を生成させる
- PowerPaintでオブジェクトを削除
- : 元画像の拡張
- 元画像の1.5倍にoutpainting
- 倍率を変更した時の結果は後述
- , は余計な情報が増えて問題が難化、 は情報が減って易化すると想定している


- 質問のブートストラップ
- 4種類の変更を入れ込む
- : 単語の置換
- 文中の単語を、シノニムや似た表現に変換する
- : 文の言い換え
- 同じ質問内容で、別の言い回しに変更する
- 例: “How does photosynthesis work?
- 一般向け: How do plants make food from sunlight?
- 研究者向け: What are the key differences between the light-dependent and light-independent reactions in photosynthesis?
- : 関連コンテキストの追加
- GPT-4Vで画像に関する情報を生成し、質問に追加する
- 元の質問の答え記載してしまわないように注意
- : 無関係なコンテキストの追加
- GPT-4Vで、画像に関する質問とは全く関係ない情報を生成し、質問に追加する
- , , は質問の難化、 は易化を想定している

- Judge Module
- 変更前後の画像・質問で、回答が変化していないかを判定する
- 回答が変化していると判定された場合は、最大5回まで生成をやり直す
- 判定にはLVLMのInternVL-2を利用
- 合成ブートストラップ: 画像・質問のブートストラップの組み合わせ方
- ペアマルチモーダル合成: 画像3種類・質問4種類から、12種類のサンプルを生成
- マルチ戦略合成: 画像・質問について複数のブートストラップを適用する
実験
実験設定
- データセット
- MME: Yes/No Questions
- MMBench, SEEDBench: Multiple Choice Questions
- MMVet, LLaVABench: Visual Question Answering
- LVLMs
- Closed-Source APIs
- GPT-4o
- Claude
- Open-Source Models
- DeepSeek-VL
- TransCore_M
- XComposer2
- Monkey-Chat
- LLaVA-NeXT-Vicuna
- Yi-VL-34B
- Qwen-VL
- InternVL
- すべてtemperature = 0
画像・質問それぞれのブートストラップ
- 画像のブートストラップ
- (オブジェクト追加)・(画像拡張)を入れた場合に性能劣化、(オブジェクト除去)を入れた場合に性能改善の傾向

- 質問のブートストラップ
- (単語置換)・(文の言い換え)・(無関係な情報追加)を入れた場合に性能劣化、(関連情報の追加)を入れた場合に性能改善の傾向

合成ブートストラップ
- ペアマルチモーダル合成: 画像3種類・質問4種類から、12種類のサンプルを生成
- 易化に働くブートストラップの組み合わせは、最も悪いケースよりも+10pt程度変わる

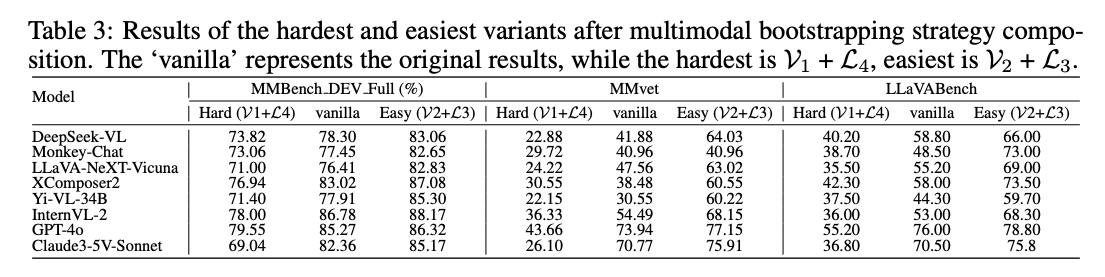
- マルチ戦略合成: 画像・質問について複数のブートストラップを適用する
- 難化に働くブートストラップを増やすほど、性能劣化につながる

Analysis
- 画像拡張の倍率の影響
- 倍率が大きくなるほど、無関係な情報が増え、性能が劣化していく

- ブートストラップによるデータ汚染への影響
- ブートストラップによって汚染は下げられている

- Judge Moduleの精度
- ブートストラップ前後の回答差異の有無を人間が評価した結果、ほぼ100%近い精度になっており、提案手法のやり方で問題はなさそう

- ブートストラップによってLVLMの回答が変化した例




