
2025-06-10 機械学習勉強会
今週のTOPIC[論文] SmolDocling: An ultra-compact vision-language model for end-to-end multi-modal document conversion[論文] MAIN-RAG: Multi-Agent Filtering Retrieval-Augmented Generation[slide] SSII2025 [OS1-02] 量子化手法の概要とエッジ開発における課題[Slide] SSII2025 [TS1] 光学・物理原理に基づく深層画像生成[blog] SelfCheckGPT for LLM Evaluation[blog] RAG is dead, long live agentic retrieval[論文] EDINET-Bench: Evaluating LLMs on Complex Financial Tasks using Japanese Financial StatementsメインTOPIC概要関連研究アプローチ手法の全体像一段階目:ページレベルのレイアウト解析二段階目:要素レベルのコンテンツ解析要素画像のエンコーディング並列コンテンツ解析学習データ評価ページレベル評価要素レベル評価実験実験概要ページレベル解析の比較要素レベル解析の比較アブレーションスタディ並列デコード(Parallel Decoding)タイプ別プロンプト vs 一律プロンプト要素クロップ vs バウンディングボックスクエリまとめ成果限界と今後の課題
今週のTOPIC
@Naoto Shimakoshi
[論文] SmolDocling: An ultra-compact vision-language model for end-to-end multi-modal document conversion

- IBM ResearchとHugging Faceの論文
- 256MクラスのVLMモデル、1ページあたりの変換時間は0.35秒 (Azure DIだと5secとかかかったりする)
- https://huggingface.co/ds4sd/SmolDocling-256M-preview
- ベースはHugging FaceのSmolVLM-256M
- Qwen2.5VL-7Bよりもレイアウト認識で精度を上回る
- DocTagsという形式で文章を整理
- HTMLは位置情報を持たない。見た目のためのタグは必要ない。コードブロックなどに対応してない。
- XMLは冗長な構文でトークン消費長が増大
- OTSLという表の構造を効率的に表現できる言語とも組み合わせた

- 汎用でなく、文書理解のみに特化させたため必要最小限のパラメータですむ
- 画像トークンを512x512画像 → 64トークンまで圧縮する (既存は数千トークン)
- 低品質大量データではなく、高品質の厳選データを用いることで小型モデルを実現
- 既存のオープンなデータセットから多様なものを抜き出して、品質レビューや人間のアノテーション
@Shun Ito
[論文] MAIN-RAG: Multi-Agent Filtering Retrieval-Augmented Generation
- ACL2025
- RAGで関係性が薄いdocumentを除きつつ回答を生成するための手法を提案

- 手順
- (Predictor) QueryからRetrievalされたdocumentそれぞれについて、そのdocumentだけを使った仮の回答を生成する
- (Judge) それぞれのD-Q-Aペアについて、回答が適切かどうかをスコア付けする。スコアは「yes」トークンと「no」トークンの対数確率の差で計算し、閾値はスコアの分布から動的に決定する。
- (Final-Predictor) スコアの高い順にdocumentをソートし、それらとQueryを元に最終的な回答を生成する
- 実験結果
- ベースラインに比べていずれのタスクでも比較的高いスコア(without retrievalの中では最高)になっている
- Baselines without retrieval: 事前学習された知識のみで回答
- Baselines with retrieval (training-based): retrievalを含めて学習されている
- Self-RAG: 検索の必要性や生成された回答の評価を含めて生成するよう訓練
- Baselines with retrieval (training-free): retrievalが外付けコンポーネント
- 提案手法の別バリエーション(Judgeでyes, noを直接生成させる、選ばれたdocumentをランダムに並べる)は、上で紹介した手法よりも精度が落ちる


@Yosuke Yoshida







@Takumi Iida (frkake)
[Slide] SSII2025 [TS1] 光学・物理原理に基づく深層画像生成
概要
先日JSAIと同日程で開催されていたSSIIでの発表資料。
物理世界を反映したモデルは、世界を知ることができそうなのでとても興味がある。
各モデルの性質を体系的にまとめており、同じ観点(3D表現はなにか、2Dにどう投影しているか、どう学習しているかなど)から見たときにどのように解いているのかが整理されており、大変読みやすい。
内容
画像や動画の超高精細な生成が可能になってきたが、以下のような研究課題も残されている。

光学や物理を陽に利用するモデルで解決できるのでは?私もここに興味あり。

光学モデルと物理原理に基づくモデルの組み合わせで、静止画や動画から発展的問題を解くことができる。

例えば、3DGS + 物理シミュレーション(MPM)を組み合わせると、静止画のオブジェクトを物理的に動かせる。

個人的にはこれが面白い。物体の性質や世界を変えることができる。

中身が違う、みたいなパターンだと難しい。が、衝突時の外部形状の変化から内部形状を推定する方法とかもあるらしい。面白い。

きれいに静止画や動画が生成されているように見えるが、細かいところで現実世界を反映できていないことがあるんだなと改めて実感。
応用例として、特に、物体のキネマティクスやダイナミクスを操作できるのは面白い。
@Hiromu Nakamura
[blog] SelfCheckGPT for LLM Evaluation
SelfCheckGPT: LLMからランダムに生成した回答は一致するはずという前提をとったDetecting hallucinations手法
1: ユーザーが質問し、LLMが答えを出す。
2: その後、SelfCheckGPT は同じ AI に同じ質問を複数回尋ね、いくつかの新しい回答を収集
3: 回答が一貫している場合正確である可能性が高くなる/答えが互いに矛盾する場合hallucinationである可能性がある
これを定量化するために、SelfCheckGPT は回答群に 0 から 1 までのhallucination scoreを割り当てる。0が文章が信頼できる情報に基づいていることを意味する。

SelfCheckGPT論文が提案した具体的な評価の仕方の中でも記事では最も人気のある 3 つのバリアント、SelfCheckGPT-BERTScore、SelfCheckGPTMQAG、SelfCheckGPTLLMPrompt に焦点を当ている。
- SelfCheckGPT-BERTScore
- BERTScore使う
- SelfCheckGPTMQAG
- MQAG使う
- 要約評価を目的に生み出されたけど、SelfCheckGPTでは、LLMが生成した文の一貫性を測るために、このMQAGの枠組み(質問生成+複数選択式QA+確率分布/回答比較)を応用している
- https://arxiv.org/abs/2301.12307
- (「質問生成モデル」と「QA解答モデル」の精度に引っ張られそうだが)

- SelfCheckGPTLLMPrompt
- LLMに判断してもらう
⇒ 記事「全部Opik(Open-source LLM evaluation platform)に送ってな!」
(論文までは読めなかったすまん…)
[blog] RAG is dead, long live agentic retrieval
面白いけどタイトルは詐欺(笑。RAGをAgentでいい感じにしましょうの記事だった。
主にAgentで対象Index絞り込みと、Retrival mode(chunk/metadata/content)を選択させる。

@ShibuiYusuke
[論文] EDINET-Bench: Evaluating LLMs on Complex Financial Tasks using Japanese Financial Statements
- 関連
- ‣
- ‣
- ‣
- 日本の金融市場におけるLLMの性能を評価する日本語ベンチマーク「EDINET-Bench」を提案。日本の複雑な金融タスクにおけるLLM性能の評価を目的とする。
- EDINET(金融商品取引法に基づく有価証券報告書等の開示書類に関する電子開示システム)から収集した年次報告書をもとに、LLMの不正検出(Fraud detection)、業績予測(Earnings forecast)、業界予測(Industry prediction)を評価するデータセットおよび評価コードを公開。また、データセット作成のソースコードも公開。

- データ抽出・分析にClaude3.7 Sonnetを利用。
- Parsing inconsistencyやMislabelingとあるように、固有表現抽出とかで苦労してそう。
- 論文ではベンチマークデータセットを作って各種LLMで評価。
- 不正検出
- Logistic regressionと比較。Summaryデータ(数値データ)で学習、推論。
- LLMの推論性能はLogistic regressionと同程度またはLogistic regression以下。
- 業績予測
- Logistic regressionと比較。Summaryデータ(数値データ)で学習、推論。
- LLMの推論性能はLogistic regressionと同程度またはLogistic regression以下。
- 業界予測
- Logistic regressionとの比較なし。
- 実際の不正検出では、監査人が不正を疑う場合は内部情報にアクセスして調査するので、EDINET-Benchデータセットだけで不正検出するのは限界がある。

- 感想
- LLMはある程度のデータ分析性能を持っている一方で、LLM内部で機械学習を実践するように学習しているわけではない。機械学習で解くのが向いている課題でLogistic regressionがOutperformするのは納得。
- Logistic regressionだけでなくLightGBMとかと比較してみると面白いかも。
- 論文からデータ収集やクレンジングで苦労している感が出てて面白い。下記の通り、データ収集にかかるトークンと金額が書いてあるのは親切で素晴らしいと思う。

メインTOPIC
| Title | Dolphin: Document Image Parsing via Heterogeneous Anchor Prompting |
|---|---|
| Authors | Hao Feng∗, Shu Wei∗, Xiang Fei*, Wei Shi∗†, Yingdong Han, Lei Liao, Jinghui Lu, Binghong Wu, Qi Liu, Chunhui Lin, Jingqun Tang, Hao Liu, Can Huang† |
| Notes | ∗The first four authors contributed equally to this work. †Corresponding author |
| Organization | ByteDance |
| Publication | Accepted to ACL 2025 |
| Code | https://github.com/ByteDance/Dolphin |
概要
文書画像の解析は、テキストの段落、図、数式、表などの要素が複雑に絡み合っており難しいものです。
これまでのアプローチの課題に対応すべく、新しいマルチモーダル文書画像パースモデル「Dolphin(Document Image Parsing via Heterogeneous Anchor Prompting:異種アンカープロンプトによる文書画像解析)」を開発しました。
Dolphinは2段階のプロセスを採用し、まずレイアウト要素を生成し、次にそれらを異種アンカーとして活用して並列コンテンツ解析を行います。
3,000万以上のサンプルで訓練されたDolphinは、軽量なアーキテクチャと並列処理により、ページレベルと要素レベルの両方で最先端の性能を達成しています。

領収書サンプルで動作させると以下のとおり。

JSON出力結果全体
関連研究
従来の手法には2系統:
- 統合型(integration-based):複数の専門OCRモデルを連携させて解析
- 例:Mathpix, TextIn, MinerU
- 高精度だが、モデル間の統合が複雑で非効率
- VLMベースの自己回帰型(autoregressive):文書全体を直接エンドツーエンドで生成
- 例:
- General VLMs: GPT-4V, Claude-series, Gemini-series, Qwen VL-seriesなど
- 汎用性は高いが、長文・複雑レイアウトに弱く、遅い
- Expert VMLs: GOT, Donut, LayoutLM-seriesなど
- こちらも高い性能ははっきしているものの General VLMs と似たような課題を抱えています。
アプローチ

手法の全体像
analyze-then-parse と呼ぶ2段階解析を行います。
- レイアウト解析(上図・左上)
- 入力:ページ画像
- 出力:テキスト段落・図・表などの要素群 + 読み順
- 手法:Swin Transformer + mBART decoder で読み順に沿って要素を抽出
- コンテンツ解析(上図・左下)
- 各要素ごとに専用プロンプトを作って並列に認識
一段階目:ページレベルのレイアウト解析
この段階では、文書中のレイアウト要素とその読み順を以下の手順で特定することを目的とします。
ページ画像のエンコーディング
視覚エンコーダとして Swin Transformer(Liuら, 2021)を使用します。これはページ画像 を入力として受け取り、視覚的な埋め込みベクトルの列 を出力します(ここで、 は埋め込み次元、 は画像パッチ数です)。
Swin Transformer:
Transformerを computer vision に適用する際、対象のスケールが大きく変化することなどの課題に対応するために提案された、Shifted windowsで計算される階層的Transformer。

Swin Transformer の階層的な設計により、全体のレイアウトパターンと局所的なテキストの詳細の両方を捉えることができます。なお、入力画像は縦横比を保持したままサイズ変更とパディングが行われ、最終的に固定サイズ に調整されます。これはテキストの歪みを防ぐためです。
レイアウトシーケンスの生成
レイアウト解析プロンプト をガイドとして用い、デコーダはクロスアテンション機構(Vaswaniら, 2017)を通じてエンコードされた視覚特徴に注目します。デコーダには mBART(Lewis, 2019)を採用しています。
mBART:
機械翻訳のために作られた、MultilingualなBART
プロンプト を入力とすることで、モデルは文書内の要素を順に特定し、構造的関係(例:図とキャプションの対応、表とその説明、セクションタイトルと段落の階層構造)を保持しながら配列します。
図2に示すように、この過程でモデルはレイアウト要素の列 を生成します。各要素 にはそのタイプ(例:図、キャプション、表、段落など)とバウンディングボックスが含まれます。この構造化されたレイアウトのシーケンスは、次の段階である「要素レベルのコンテンツ解析」においてアンカー(基準点)として機能します。
二段階目:要素レベルのコンテンツ解析
第1段階で解析されたレイアウト要素をアンカー(基準)として用い、各要素を並列に解析します。

要素画像のエンコーディング
第1段階で特定された各レイアウト要素 に対して、その該当領域を元の画像から切り出してローカルビュー を作成します。これらのローカルビューは、同じ Swin Transformer を用いて並列にエンコードされ、各要素に固有の視覚特徴を抽出します。
並列コンテンツ解析
エンコードされた要素の視覚特徴に対して、タイプ別のプロンプトを用いて解析を実行します。
図2(右)に示されているように:
- 表には専用のプロンプト を用いて、HTML形式での解析を行います。
- 数式は、文中に出現することが多く、その多くが段落文の一部として扱われるため、段落用プロンプト を流用して処理されます(出力形式はLaTeX)。
視覚特徴 と対応するプロンプト を受け取り、デコーダがそれぞれの要素の内容を並列に生成します。この並列処理戦略と要素タイプに応じたプロンプト設計の組み合わせにより、高い計算効率と正確なコンテンツ認識の両立を実現しています。
学習データ
| ソース | 粒度 | サンプル数 | タスクタイプ |
|---|---|---|---|
| 混合文書 | ページ | 12万 | レイアウト解析(読み順付き) |
| HTML | ページ | 437万 | パース(要素抽出) |
| LaTeX | ページ | 50万 | パース(数式など) |
| Markdown | ページ | 71万 | パース(段落・表) |
| テーブル | 要素 | 157万 | テーブル構造解析 |
| 数式 | 要素 | 2,300万 | 数式解析(LaTeX) |
| 合計 | - | 3,027万 | - |
- 混合文書
- 試験問題、教科書、新聞、ビジネス文書など多様な資料から収集された文書画像で構成されています。各文書には、要素の境界ボックスと読み順のアノテーションが付与されており、レイアウト解析と順序予測の両方の学習に利用されます。
- HTML由来のデータ
- Wikipedia(英語・中国語)をHTMLソースとして利用し、レンダリングを通じて合成文書画像を生成。 タグを使った文字単位のアノテーションを施し、フォントをランダムに変えることで視覚的多様性も確保しています。
- LaTeX
- arXivから収集したLaTeX文書をLaTeX Rainbowというレンダリングツールを使って可視化し、数式・図・表・見出しなどを色分け表示。その結果から要素のタイプ、構造階層、空間的位置を抽出します。
- Markdown
- GitHubページなどから収集したMarkdown文書をPandocでPDFに変換し、 を使ってソースMarkdownとの整合を取りながらアノテーションを生成。段落・表・数式の構造情報を正確に取得しています。
- テーブル
- PubTabNet(Zhong et al., 2020):HTML形式の表、56.8万件
- PubTab1M(Smock et al., 2022):より細かい構造を含む表、100万件
- 数式
- arXivから抽出したLaTeX形式の数式をXeTeXで画像レンダリングし、背景やフォントの多様性を持たせた合成画像を生成。行内・単独・複数行数式を含んでいます。
評価
ページレベルと要素レベルの両方で評価。
ページレベル評価
- (a) Fox-Page
- Fox-Pageは、英語(112ページ)と中国語(100ページ)から構成されるバイリンガルベンチマークです。
- 単一カラムと複数カラムの形式が含まれ、1ページあたり平均1,000語以上を含むため、読み順の予測とテキスト構造理解において高い難易度を持つテストセットです。
- (b) Dolphin-Page
- Dolphin-Pageは、本研究で新たに構築された複雑な構造を持つ文書用のベンチマークです。
- 英語と中国語を含む210ページで構成されており、内訳は:
- 111ページ:純粋なテキスト文書(例:レポート、手紙)
- 99ページ:表、図、数式などを混在させた複雑なレイアウト
- すべてのページには、自然な読み順に従った精密な手動アノテーションが付与されています。
要素レベル評価
- (a) テキスト段落
- テキスト認識能力の評価として、2つのテストセットを使用:
- Fox-Page公式のブロックレベルテストセット(424の段落画像)
- Dolphin-Pageから抽出した1,856段落
- 評価
- 読み順の予測を含まず、純粋な文字認識精度に焦点を当てた評価
- (b) 数式
- 数式認識は以下の3つのベンチマークで評価:
- SPE(簡単な印刷数式, 6,762件)
- SCE(スクリーンキャプチャ数式, 4,742件)
- CPE(複雑な数式, 5,921件)
- 評価指標:CDM(Character Difference Metric)
→ 予測と正解の文字レベル編集距離を測定(数式の認識誤差を精密に捉える)
- (c) テーブル
- 使用ベンチマーク:
- PubTabNet(科学論文から抽出された7,904件の表画像)
- PubTab1M(10,000件のより困難な表)
- 評価指標:TEDS(Tree-Edit-Distance-based Similarity)
- HTML構造で表現された表の予測結果と正解との構造的一致度を測定
実験
実験概要
- エンコーダには、ウィンドウサイズ7のSwin Transformerを使用し、以下のような階層構成を持ちます
- エンコーダ層数:[2, 2, 14, 2]
- アテンションヘッド数:[4, 8, 16, 32]
- デコーダには10層のTransformerを使用し、隠れ層の次元数は1024です。
- 訓練には以下を使用しています:
- 最適化手法:AdamW
- 初期学習率:5e-5(コサイン減衰スケジュール)
- GPU環境:A100 × 40枚
- バッチサイズ:1デバイスあたり16(勾配累積あり)
- 学習エポック数:2
- 入力画像の前処理
- 入力画像は、縦横比を維持したまま長辺を896ピクセルにリサイズし、896×896の正方形になるようパディングします。
- バウンディングボックスはすべて正規化座標で表現され、この最終サイズに対して適用されます。
ページレベル解析の比較

- ベンチマーク:Fox-Page(英語・中国語)、Dolphin-Page(複雑文書)
- Dolphin(わずか322Mパラメータ)は、より大規模なVLM(例:GPT-4o, Claude3.5)や専門モデル(GOT, Foxなど)を凌駕
- 特に複雑文書である Dolphin-Page において、編集距離0.1028という最高成績を達成
- 推論効率も優れており、0.1729 FPSは、最も高速な既存モデルMathpix(0.0944)よりも約1.8倍高速
要素レベル解析の比較
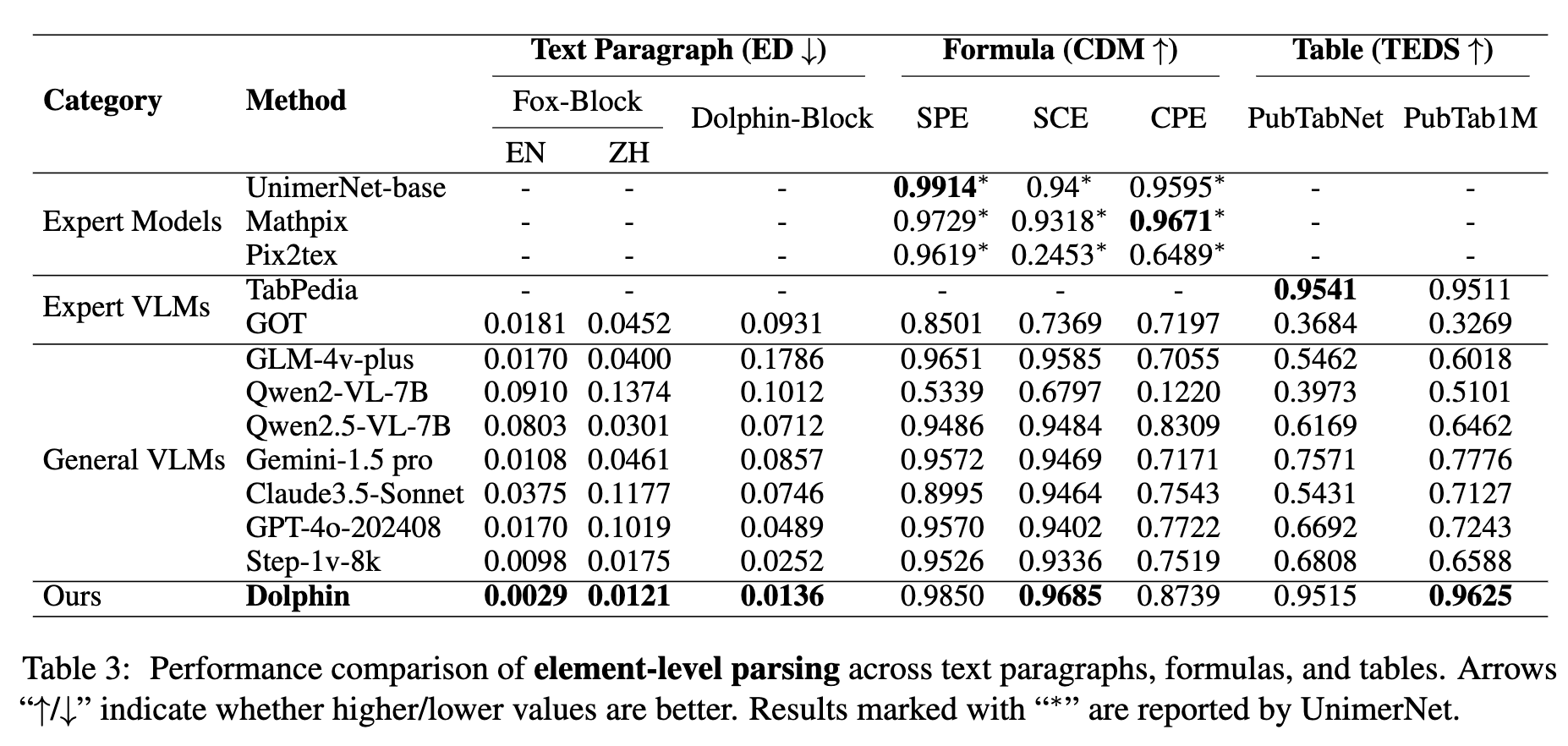
- 段落認識、数式認識、テーブル解析の全てにおいてSOTA性能
- 特に:
- 数式のCDM:0.985(専門モデルMathpixやUnimerNetを上回る)
- テーブル解析TEDS:PubTabNet 0.9515, PubTab1M 0.9625
アブレーションスタディ
並列デコード(Parallel Decoding)

第2段階における並列デコード戦略の効率性を検証するため、逐次的な自己回帰デコードと比較しました。
- 並列デコードにより1.8倍の高速化(FPS: 0.1729 → 0.0971)を実現しつつ、精度は維持
- この高速化には以下の制約があります:
- 各要素の前処理時間
- バッチサイズ制限(GPUメモリの都合により最大16要素/バッチで処理。多数要素がある文書では複数回推論が必要)
- 既存の自己回帰型並列デコーディング手法(例:PagedAttention)を活用することで、さらに高速化の余地があります。
タイプ別プロンプト vs 一律プロンプト
第2段階で使用するプロンプトをすべて汎用プロンプト(例:"Read text in the image.")に置き換えた場合との比較を実施。
- 結果:型別プロンプト使用時の方が明らかに高精度
- 編集距離:0.1283 → 0.1613(悪化)

代表的な事例では、汎用プロンプトが表をLaTeX数式として誤認識する一方、型別プロンプトは正しくHTMLテーブルとして解析・出力できました。
要素クロップ vs バウンディングボックスクエリ
第2段階における「入力形式」の違いを比較:
- 要素クロップ(画像を切り出して処理)
- ボックスクエリ(「この座標のテキストを読み取れ」と指示)

要素クロップの方が精度が高い(ED: 0.1283 → 0.1849)
考察
- クロップは「見えているものをそのまま読む」という自然な認識モデルを可能にする
- ボックスクエリは、モデルに位置理解と内容認識の二重の認知負荷を課すため、精度が落ちやすい
まとめ
成果
- ページ全体、要素単位の両方において、DolphinはSOTAを達成。
- 特に複雑な構造を持つ文書(数式、表、図などが混在)に対しても、高精度かつ高速な解析が可能。
- アーキテクチャは軽量で推論も高速。実運用への展開性が高い。
限界と今後の課題
- 縦書き文書への対応:現在は主に横書き文書に対応しており、縦書きの古文書などには弱い。
- 多言語対応の拡張:英語・中国語には強いが、多言語の拡張(例:日本語・アラビア語等)が今後の課題。
- さらに細かな並列処理の最適化:段落内のテキスト行や、表のセル単位の並列処理にも今後対応したい。
- 手書き文書への対応:現在のモデルは印刷体に最適化されており、手書き文書の認識は課題として残る。