
2025-06-17 機械学習勉強会
今週のTOPIC[論文] Personal LLM Agents: Insights and Survey about the Capability, Efficiency and Security[blog] Benchmarking Multi-Agent Architectures[論文] Learning a Continue-Thinking Token for Enhanced Test-Time Scaling[論文] ProRL: Prolonged Reinforcement Learning Expands Reasoning Boundaries in Large Language Models[blog] Flash Attention 2 + 量子化でVLLMはどこまで軽くなる?ローカル運用に向けた画像枚数とメモリ使用量の検証[blog] uv, ruff, devcontainer, Claude Codeを使ったモダンなPython開発環境のテンプレート[論文] Emergent social conventions and collective bias in LLM populations[論文] Agentic Neural Networks: Self-Evolving Multi-Agent Systems via Textual BackpropagationメインTOPIC:Reinforcement Pre-TrainingひとことでいうとイントロRLHF RLVR RPT(提案手法) 前提知識Next Token Prediction (NTP)Reinforcement Learning with Verifiable Rewards (RLVR)提案手法:Reinforcement Pre-Training (RPT)タスク学習方法実験事前学習評価1:Language Modeling評価2:RPTのReinforcement Fine-Tuning評価3:ゼロショット分析:次トークン推論パターン分析
今週のTOPIC
※ [論文] [blog] など何に関するTOPICなのかパッと見で分かるようにしましょう。
技術的に学びのあるトピックを解説する時間にできると🙆(AIツール紹介等はslack channelでの共有など別機会にて推奨)
出典を埋め込みURLにしましょう。
@Naoto Shimakoshi
[論文] Personal LLM Agents: Insights and Survey about the Capability, Efficiency and Security
- githubにもまとめられている
- 個人端末などで動くPersonal LLM Agentに関するサーベイ論文。元論文は60ページ超なので、一部を抜粋。
- PC Era → Internet Era → Mobile Eraと来て次はAI EraでPersonal LLM Agentsが出来てくるという論調
- Perosnal Assistantの技術がどのように進んでいるか
- Template-based Programming
- 最も一般的な手法
- 自動化可能な機能を事前定義しておいて、ユーザのコマンドをマッピングさせる。
- 信頼性や精度は高いが、スケーラビリティが限定的
- Supervised Learning Methods
- テキスト指示からモバイルUI上の実行可能アクション系列にマッピングするなど
- 汎化性能は上がるが高品質なアノテーションが必要になる
- Reinforcement Learning Methods
- 対象インターフェースと継続的相互作用で能力を獲得
- 行動空間が広く学習が難しい (10**5 ~ 10**10の探索空間)
- 研究としてはワークフローで許可される行動を制約、複雑な指示を小さな部分んい分解など。
- 継続的に学習できるが、報酬関数設計などが必要
- Early Adoption of Foundation Models
- LLMの採用の初期段階
- 今は単純なLLMチャット機能の統合に留まることがほとんど

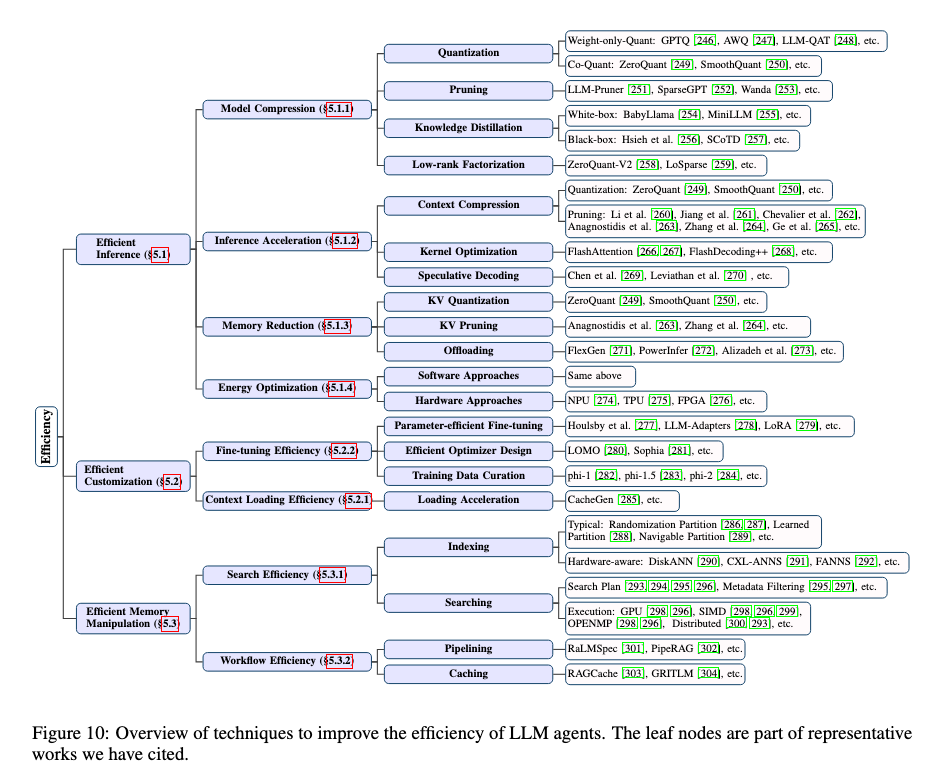
- Personal LLM Agentsの基本構成

- 自動運転と照らし合わせた自動化の定義

- 25人の専門家と議論して出てきた意見 (一部抜粋)
- どのようにAgentをカスタマイズしていくべきか
- 66.67%がin-context learningとfine tuningの両方が必要と回答
- 43.75%がin-context learningだけではL4まで辿り着くことは困難と考える
- 例えば工業系の人などがユーザの場合、LLMはもっと特定のVerticalなドメインに集中すべき
- Agentに必要な最重要な能力は何か
- 研究界隈ではLong contextが重視されるがそこまで問題ではない
- どのようにAgentと協調すべきか
- 60.87%が音声認識と回答
- 最重要な技術課題は何か?(一部抜粋)
- Intelligenceの観点ではMultimodal Support、Context Understanding、Context-aware Actions、Lightweight LLMのドメイン理解能力の向上
- 性能的には効率的な圧縮手法、ローカル・リモートの協調できるアーキテクチャ
- その他、パーソナライズのための効率的なデータストレージ


- タスク実行能力を上げるにはどうするべきか (一部抜粋)
- API連携とツール利用の高度化
- APIが利用可能な場合はAPIを利用、ただし全てのAPIが公開されているわけではないので、UIベースのタスク実行も考慮に入れる。
- コンテキスト認識能力の向上
- 多様なセンサーデータを用いて、状況に即したアクションを行えるようにする。特にL4/L5に求められるようなProactiveなアクションを行うためには、ユーザの潜在的な心理状態や社会的文脈といった抽象概念を推論する能力が必要。
- 記憶だけでなく活用も重要。
- RAGだけでなく、Agentに自己進化させて、継続的に学習させることも重要。
- Reflextion, Self-Refine, EVOLVE, Self-RAGなどの研究が自己改善ループの作成に役立つ
- その他効率性やセキュリティ・プライバシーなどももちろん重要
@Yuya Matsumura
[blog] Benchmarking Multi-Agent Architectures
- LangChain によるマルチエージェントのベンチマークのブログ
- マルチエージェントシステムへのモチベーション
- ツール数やコンテキストのサイズが増えることによって、性能が落ちる。スケーリングの問題
- エンジニアリングのベストプラクティスに従うと、異なる役割ごとにモジュール化したエージェントを作るほうが個別の更新や評価、保守、並列化が容易になる。
- 開発する人やチームも複数にわたるであろうから、どこかで分割したい
- 汎用マルチエージェントシステムへのモチベーション
- ほとんどのマルチエージェントは特定の領域の垂直統合型アプリケーション用に作成されている。つまり、特定のドメインに対しては汎用的なものよりカスタムしたもののほうが好まれる。実際に性能もいいだろう。一方で、以下のケースから汎用マルチエージェントアーキテクチャへの注目も増えている。
- 導入の容易さ
- ツール呼び出しを介してすべての通信が行われる。アプリケーション固有のワークフローよりも性能が劣ることが多いですが、簡単に始められる。
- Bring your own agents(BYOA)
- 他の人に自分のエージェントを持ち込んでもらって接続することが必要になってきうる
- ベンチマーク:τ-benchをベースにデータセットを拡張
- https://arxiv.org/abs/2406.12045?ref=blog.langchain.dev
- 小売のカスタマーサポートやフライト予約などのシチュエーションテスト
- 元のデータセットのタスクの完了には必要なく、システムが他の(無関係な)ツールや指示セットが「念のため」提供された場合に、各エージェントがどれだけうまく機能するかをテストするための現実的な「邪魔者」(distractors)を追加した。コンテキストがどんどん増えていった際に、エージェントの性能がどうなるかというスケールテスト。
- 6つの追加環境(住宅改修、技術サポート、薬局、自動車、レストラン、Spotifyプレイリスト管理)が追加
- 各環境には、それぞれのドメインとのインタラクションを容易にするための19の異なるツールと、ドメインに関連する指示を含む wiki が用意された。
- gpt-4oをベースに以下の3つのエージェントアーキテクチャで実験
- Single Agent
- 単一のプロンプトと、すべてのドメインのツールおよび指示にアクセルできるツール呼び出しエージェント
- LangGraphの create_react_agent
- Swarm
- 各サブエージェントはドメインごとに区切られているが、他のエージェントを認識しており、必要に応じて引き継ぐことができる。
- エージェントの回答は直接ユーザーにFBされる。
- 同時にはひとつのエージェントのみがアクティブ
- LangGraphのlanggraph-swarm
- Supervisor
- 単一のスーパーバイザーエージェントがユーザーの入力を受け取り、サブエージェントに作業を委譲する。
- サブエージェントがレスポンスを返すと、制御はスーパーバイザーに戻る。
- ユーザーにFBを返せるのはスーパーバイザーのみ。
- LangGraphのlanggraph-supervisor
- サブエージェントはなんでもいいので、いろんなマルチエージェントシナリオで適応可能なはず。いわゆる汎用マルチエージェント。

- 実験結果
- Score
- シングルエージェントはドメインの数が増える(2つ追加されると)といっきに性能が落ちた。
- 邪魔なドメインがなければ単一エージェントが強い。
- Swarmは全体的にsupervisorを上回る。
- Swarmのほうが伝言ゲームが少ないからからかと考察。
- Cost
- シングルは線形に増えていく
- supervisorのほうが翻訳が入る分多いか。


- supervisorの改善:性能のボトルネックはsupervisorとサブエージェントの伝言ゲーム・翻訳部分だと考えて以下の改善(さっきの実験結果は改善後のものを利用)
- ハンドオフメッセージの削除
- サブエージェントのstateからハンドオフメッセージを削除し、サブエージェントとのコンテキストを減らした。
- ハンドオフメッセージ:supervisor が sub にタスクを依頼する際の内部的なルーティングのロジック的なもの
- サブエージェントのレスポンスをそのまま直接ユーザーに送信する forward_message ツールをsupervisorエージェントに与えた
- 必要に応じて”再翻訳”せずともよい状態にすることでミスを減らした。
- ツールの命名変更
- supervisor が sub を呼び出すツールの命名をいろいろ変えたらしい? ”delegate_to_<agent>” vs “transfer_to_<agent>” を実験したりとか。
@Shun Ito
[論文] Learning a Continue-Thinking Token for Enhanced Test-Time Scaling
- arxiv 2025/06/12
- 推論時に追加の計算量を利用する「テスト時スケーリング」を考える
- budget forcingについて
- 推論モデルで思考終了時にトークンが出てくる
- 予算が残っていれば「Wait」などの固定トークンに置き換えて思考を継続させる
- 提案: 置き換えるトークンは「Wait」などの元々あるトークンではなく、というフラットな新しい特殊トークンにする
- フラットなトークンに置き換えることで、より多くの思考パターンに続けられる?
- DeepSeek-R1の蒸留モデルで、推論中にトークン予算が尽きていない & 強制継続回数の上限に達していない場合、 を に置き換えて推論させる → 強化学習で の埋め込みベクトルだけを更新

- 結果
- 数学のベンチマークで精度向上
- の直後に出現するワード。再検討を促す「no」、「Wait」、「maybe」、「lets」が多く見られる
- うまくいった例



@qluto (Ryosuke Fukazawa)
[論文] ProRL: Prolonged Reinforcement Learning Expands Reasoning Boundaries in Large Language Models
Mingjie Liu, Shizhe Diao, Ximing Lu, Jian Hu, Xin Dong, Yejin Choi, Jan Kautz, Yi Dong
NVIDIA
強化学習が大規模言語モデルの推論能力そのものを拡張できるかという問いに向き合った論文。
推論能力の向上は2つの手法で高められてきた
- テスト時の探索強化(Chain-of-Thoughtなど)
- RLによる報酬に基づくチューニング(o1など)
ただ、RLはすでにモデルに存在する回答を抽出しているだけで、新しい推論能力を獲得させているわけではないのではないかという疑問が上がっていた。
従来の短時間のRLではなく、長時間のRL(Prolonged RL = ProRL)を通じて、下記を検証した
- RQ1: RLによってLLMの推論境界が本当に拡張されるのか?
- RQ2: RLで「ベースモデルでは到達不能な解法」に到達できるのか?
エントロピー崩壊を避け、長時間のRLを可能にするための工夫は以下の通り。
トレーニングの初期段階でモデルの出力分布が過度に尖った形になり、出力の多様性が著しく低下してしまうことがある。エントロピーが崩壊すると、ポリシーは探索を十分に行う前に狭い出力の集合に早期に固執してしまい、探索能力が大きく損なわれてしまう。
- ロールアウト時のサンプリング温度を上げる
- 動的サンプリングによる探索強化
- KL正則化とReference Policyの定期的リセットによる安定化
提案モデル「Nemotron-Research-Reasoning-Qwen-1.5B」は、次のようなベースモデル(DeepSeek-R1-1.5B)よりも大幅な性能向上を達成した
- Baseモデルが苦手とするタスクほど、RLによる改善が大きい
- Baseモデルでは何度試しても正解できないタスクに対し、提案手法は100%正解した
@Yosuke Yoshida
[blog] Flash Attention 2 + 量子化でVLLMはどこまで軽くなる?ローカル運用に向けた画像枚数とメモリ使用量の検証
実験
- 利用モデル、想定の運用環境、出力したい最大トークン数が決まっている際に、VLLMに対して画像を何枚まで入力可能か検証
条件
- モデル
- Qwen/Qwen2-VL-7B-Instruct
- インスタンス
- AWS EC2 g5.xlarge(A10 GPU メモリ 24GB)
- 画像サイズ
- 872 × 1242
- 1 ~ 30枚
- 出力したい最大トークン数
- 512
- 実験パターン
- Flash Attention 2 の有無
- BitsAndBytes(以降、bnbと表記)による8bit量子化、4bit量子化の有無
結果


- Flash Attention 2の導入により、画像2枚でOOMしていた構成が、10枚まで処理可能になりました。Flash Attention 2は、Attention機構のメモリ使用量を から にするため、入力画像、つまりinputトークンが線形に増えていく今回の実験では効果が出やすいアルゴリズムであったと考えられます。
- 次に、量子化にも効果はありました。ただし、量子化のみだと、2 枚目でOOMしてしまいました。量子化はモデル自体の重みを小さくすることでメモリ節約はできますが、Self Attentionが で増えていく影響の方が今回は大きかったことが分かります。
@Takumi Iida (frkake)
[blog] uv, ruff, devcontainer, Claude Codeを使ったモダンなPython開発環境のテンプレート
筆者のモダンなPython環境のシェア記事
基本構成は以下
- uv: Rust製の高速なPythonの仮想環境・パッケージ管理ツール
- ruff: Rust製の高速なFormatter, Linter
- pytest: テストフレームワーク
- pre-commit: コミット前のFormat, Lintによるコード品質の担保
- devcontainer: 統一された開発環境の提供
- Docker, Docker Compose: コンテナ化されたポータブルな実行環境の提供
- GitHub Actions: CIの提供
- AI rules: ルール定義によるCursor, Claude Codeの適切なAI開発支援
pre-commitでは、uv.lockの自動同期やruffのフォーマッタ・リンターを動かしていて、良いなと思いました。
devcontainerを実際に使っている人初めてみた。
に設定を書くとuvやClaude Codeのインストールを自動でやってくれるようになり、便利そうだと感じました。
Docker/ Docker Composeでは、マルチステージビルドとビルダーステージのキャッシュを有効的に利用していて、勉強になりました。
キャッシュマウントというのは初めて知りました。
コンパイラとパッケージマネージャのディレクトリをキャッシュできるようになるようです。aptやpip、npmなど。
レイヤーキャッシュを効かせられるようになったり、キャッシュをイメージから除外できたりできるので、イメージの増大を防げるっぽい。
例)aptの場合は以下のように書けばいいらしい。ソース
aptは排他的アクセスを求めるため、sharing=lockedになっている。
Claude CodeなどのAIツールについては、AI Rulesをちゃんと書こうねというのと、型アノテーーションを書いておくといいよというのが書いてありました。
@Hiromu Nakamura
[論文] Emergent social conventions and collective bias in LLM populations
LLMの集団は個別バイアスがなくても、自発的に社会的慣習を形成するという主張。
N個のLLMがW個の単語をアウトプットする。各ラウンドで2つのLLMのペアが選択され、同じ単語をアウトプットしたら双方に+100ポイント、違う単語だったら-50ポイント。LLMにはどの単語を選ぶかの指示は与えず、プロンプト内の単語のリストは毎回ランダムソートされる。記憶コンテキストとして毎回Hラウンド分の結果を保持しプロンプトで与える。

ラウンドを重ねるとある一つの単語が出現する確率が1に近づく。
個別にバイアスがなくても集団バイアスが発生する。LLMのモデルごとに収束する慣習に偏りがある。

慣習が安定したコミュニティに一つのアウトプットを繰り返す少数派のエージェントを投入することで、慣習が覆ることも確認された。強い慣習(LLMによって集団バイアスとして形成される確率が高い単語によって作られた慣習)の場合、覆すのに必要な少数派の数やラウンド数は増える。慣習を覆すには覆す側の割合がある臨界点に達する必要がある。
シンプルなモデリングなので、ソーシャルネットワークや3つ以上の相互作用が発生する設定でのシュミレートがfuture work
この実験により、個人バイアステストに焦点を当てるだけでなく、集団バイアスにも焦点を当てた研究の重要性、マルチエージェントシステムの脆弱性の研究への発展を主張
@ShibuiYusuke
[論文] Agentic Neural Networks: Self-Evolving Multi-Agent Systems via Textual Backpropagation
- 複数のLLMを組み合わせたマルチエージェントフレームワークAgentic Neural Network(ANN)を提唱。複数層で構成されたニューラルネットワークアーキテクチャ的なマルチエージェントシステム。
- 各AIエージェントがノードとなり、複数ノード(エージェント)で構成されたレイヤーがteamとして特定のサブタスクを処理する。ANNでは動的にチーム間のコラボレーションを修正する。

- Forward phase
- 動的チーム選択:タスクを動的にサブタスクに分割し、各層に割り当てる。
- DynamicRoutingSelectメカニズムがタスクの複雑さと以前の実行軌跡に基づいて最適な集約関数を選択。
- Backward phase:
- Forward phaseの完了後、パフォーマンスが事前に定義されたしきい値を満たさない場合、ANNはbackword phaseで最適化。
- 大域的最適化 (Global Optimization):システム全体の連携を分析し、層間の接続とデータフローを調整して、全体的なシステムパフォーマンスを向上。テキストによるフィードバックを通じてエラーを特定し、ターゲットを絞った調整を提案。
- 局所的最適化 (Local Optimization):各層内のエージェントと集約関数を微調整。実行中に特定された非効率性やボトルネックに対処する目的。テキストによる評価が勾配信号のように機能し、プロンプトの更新と接続の改良をガイド。
- モーメンタムベースの調整:最適化の安定性を向上させるために、モーメンタムベースの最適化を採用し、エージェントパラメータの急激な変化を防ぐ。
- バリデーション:エージェントの相互作用が事前定義されたプロトコルに準拠しているかを確認するフォーマット検証と、最適化の有効性を評価するパフォーマンス検証が含まれる。

- 評価


- 感想
- 実装が公開されていないのが残念。
メインTOPIC:Reinforcement Pre-Training
| タイトル | Reinforcement Pre-Training |
|---|---|
| 著者 | Yao Tang, Tianzhu Yet, Zhifang Sui, Furu Weit, Qingxiu Dong, Li Dong, Yutao Sun |
| 所属 | Microsoft Research, Peking University, Tsinghua University |
| リンク | https://arxiv.org/abs/2506.08007 |
| 関連ページ | https://aka.ms/GeneralAI |
ひとことでいうと
Next Token Predictionで事前学習するのではなく、Next Token Reasoning(提案手法)で事前学習することで、下流タスクなどでの性能上がる。
Next Token Reasoningでは、単にNext Token Predictionするだけでなく、思考プロセスを入れるもの。そうすることで「なぜ次の単語はそれなのか?」「文法的には?」などの理由を伴った深い理解につながる。
Next Token Reasoningで事前学習することをこの論文ではReinforcement Pre-Training (RPT) と命名している。

RLHFでは、Next Token Predictionで事前学習した後にRLをしてファインチューニングをしていく。RLを仕上げとしてやっていく。ケーキとチェリーを別々に。
RPTでは、RLを一緒にやっていく。チェリーとケーキを混ぜ込んでるイメージ。
イントロ
RLHF
人の好みを使ったアライメントを行っており、うまくいっている。
やり方、「どっちの回答のほうが良いか?」を人が主観的に採点。
だが、以下のような課題がある
- スケーラビリティ:そのデータを集めるのにコストがかかる。
- 報酬ハッキング(Reward Hacking):報酬モデルが近道をしてしまって、表面上は高い性能になっているが、実際に人が見てみるといまいちな感じになる。
RLVR
報酬ハッキングを軽減するために、質疑応答ペアなどから得られる客観的でルールベースの報酬を利用
ただし、データが不足していたり、ドメインが限定されたりする。
例えば、
- 数学の問題:正解の数値と一致していればOK
- コードの生成:テストをパスしたらOK
RPT(提案手法)
事前学習をしっかり行うことで解決を図る。
一般的に、事前学習ではNext Token Predictionを行っている。
RPTでは、Next Token Predictionを行うときにそのReasoningも行う(Next Token Reasoning)。
具体的には、「なぜ次のトークンはそれなのか」などの判断根拠を伴った推論を行うことで、深い理解を伴った事前学習を行う。
RLHFとRLVRの課題感との関係でいえば
- スケーラビリティ: 事前学習コーパス自体から得られる検証可能な内在的報酬を使ってRLで訓練 (事後にRLするのではなく、事前学習段階でRLを使う) →人が介在しない
- 報酬ハッキング: Next Token Predictionと同じだが、「コーパス上(学習データ)の正解と一致してるかどうか」という客観的な指標でルールベースの報酬を決めている。加えて、Prefix Matching Rewardという厳しめの評価を入れている。 →報酬ハッキングの余地が軽減
RPTの貢献点
- Next Token Reasoningを導入したスケーラブルな強化学習 本論文だとRPTはNext Token Predictionをスケーラブルなものにリフレーミングしていると書いている
- ルールベースの報酬を定義したことで、報酬ハッキングを低減 →暗記的ではなく、汎化した推論が可能に
- 学習量が増えるとその分だけ性能が向上する(スケーリング則がある)
- 様々な下流タスクでも強い。ゼロショットでも
前提知識
Next Token Prediction (NTP)
Next Token Predictionは、 が与えられた時、以下の目的関数を最大化するタスク。
平たく言えば、が与えられた時、 に一番来そうなトークンを予測するタスク。
(を入力して を得る)
モデル
Reinforcement Learning with Verifiable Rewards (RLVR)
検証可能な答えを持つ特定のスキルの向上をするために強化学習を用いる方法。
次の2つの報酬 r(o, a)の期待値を最大化
- 質問qに対するモデルπの出力o
- 質問qの正解a
提案手法:Reinforcement Pre-Training (RPT)
タスク
RPTでは、Next Token Predictionではなく、Next Token Reasoningを行う。
入出力はNext Token Predictionと同じ
- 入力: のトークンをコンテキストとして入力
- 出力(GT):次のトークン
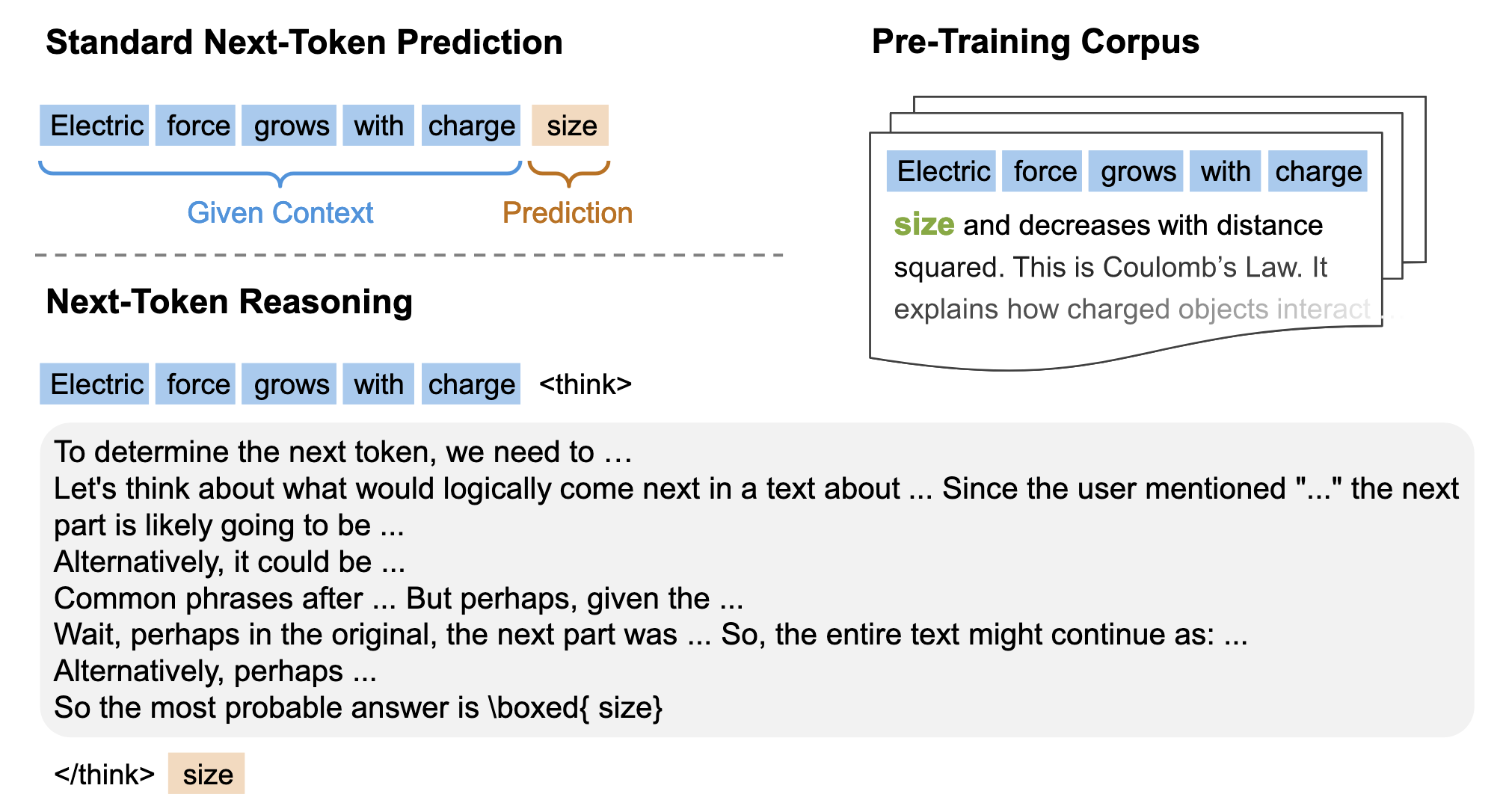
Next Token Reasoningでは、CoTを使ってNext Token Predictionをするイメージ。
上の図では、 という単語を予測するときに、「ユーザはこう言及しているから、次の単語はこれなのでは?」「でも、こういう情報が得られているから…」のように自己批判や自己修正などを行っている。
こうすることで、その背後にある隠れた知識の理解をすることができ、RLのスケーリングができるようになる。(自分自身でRLやってるからってことかな)
学習方法
RPTのモデルが出力をどう使い、学習するのかが下図。

処理の流れは以下
- Step 1:LLM がトークン を受け取る
- Step 2:LLM が思考過程を伴った 個の応答を生成( )
- Step 3:Prefix Matching Rewardで検証
- 数式は下記。
- やっていること:トークンのPrefixが合っていて、かつ妥当なトークン境界分合っているかをバイト単位で検証。ちょっとでも間違っていれば0点。きびし〜
- お気持ち:複数トークンにまたがる予測やボキャブラリー外のトークンにも対応できるようにしたい
- ルールベースの報酬にしているので、客観性がある →報酬ハッキングが生じにくい
- Step 4:報酬を最大化 Prefix Matching Rewardの期待値を最大化する。
実験
事前学習
| 学習データセット | OmniMATHデータセット |
|---|---|
| 内容 | 競技レベルの非常に難しい数学の問題と解答を集めたデータセット |
| 前処理 | トークンレベルのデータフィルタリング 小規模モデル(Deepseek-R1-Qwen-1.5B)で各トークンのエントロピー(予測の難しさ)を計算し、低エントロピー(簡単なもの)を除外。 |
| データ量 | 4,428の問題と解答 |
- 対象モデル:Deepseek-R1-Distill-Qwen-14B
- 学習フレームワーク: verl
- 推論フレームワーク:vllm
ハイパーパラメータ
| パラメータ | 値 |
|---|---|
| Actor gradient clip | 0.2 |
| Batch size | 256 |
| PPO mini batch size | 256 |
| Rollout number (=G) | 8 |
| Learning rate | 1×10−6 |
| Adam β | (0.9, 0.999) |
| Weight decay | 0.01 |
| Sampling temperature | 0.8 |
| Max prompt length | 4096 |
| Max response length | 8192 |
| Entropy loss coefficient | 0 |
利用しているプロンプト
一番いいのはv6ですが、メインの実験ではv0を使っているとのこと


評価1:Language Modeling
| 評価データセット | OmniMATHデータセット |
|---|---|
| 内容 | 競技レベルの非常に難しい数学の問題と解答を集めたデータセット |
| データ量 | 200サンプル(ホールドアウトの検証セット) |
| 前処理 | 学習データの前処理と同様。 エントロピーによって問題をEasy, Medium, Hardに分ける。 |
Next-token Reasoningを行っているRPT-14BはかなりAccuracyが良い(左表)。
RPT-14Bながらも、R1-Qwen-32Bと同等の性能(右図)。

スケーリング則が成り立つ
強化学習に費やされた総計算量(RL Compute)を増やすと、Next Token Predictionの性能が向上していく。

評価2:RPTのReinforcement Fine-Tuning
| 評価データセット | Skywork-OR1データセット |
|---|---|
| 内容 | 数学とコーディング |
| 学習データ量 | 256サンプル |
| 検証データ量 | 200サンプル |
| 前処理 | R1-Distill-Qwen-32Bを利用して、困難なタスクを特定 |
| パラメータ | 値 |
|---|---|
| PPOのミニバッチサイズ | 64 |
| エポック数 | 15 |
| トークン最大数 | 32,000 |
評価指標はおそらくAccuracy。
RPT-14Bは、追加の強化学習(ファインチューニング)を行う前からかなり性能が良い。ファインチューニングすると更に良くなる(After RL)。
Continual NTP training=RPTの事前学習と同じデータ(=OmniMATH)でNext Token Predictionで追加学習した場合の結果。良くなるどころか、劇的に劣化。

評価3:ゼロショット
| 評価データセット | SuperGPQA |
|---|---|
| 内容 | 大学院レベルの推論問題ベンチマーク 285もの専門分野にわたる、大学院レベルの知識と推論能力を問う問題を集めた、非常に広範なベンチマーク。 |
| 評価データセット | MMLU-Pro |
|---|---|
| 内容 | 様々な専門分野の知識を問うマルチタスクベンチマーク MMLUの改良版。四択問題から十択問題に。 分野的には、数学、物理、法律、工学、心理学などの14分野。 |
RPT-14Bは一貫してベースラインモデルよりもaccuracyが良い。

分析:次トークン推論パターン分析
R1-Distill-QwenとRPTの思考過程を6タイプに分類して傾向を観察。
- R1-Distill-Qwen Breakdown(分解)して、問題を小さなステップにして解いていくアプローチが多め
- Next-Token Reasoning (RPT) Hypothesis(仮説)を立てたり、Deduction(演繹的)アプローチをしたりすることが多め

RPTの思考パターンの例 こんなことが言われているらしい。 そもそもどういう入力でこういう思考過程になっているのかわからないが…
- 広い意味での文脈を考慮 calculating vector magnitude
- 重要なフレーズを特定 go over some…
- ブレインストーミング
- 仮説の生成 the next part is likely going to be…
- 代替案の検討 Alternatively, it could be…
- 構造的な手がかりを検討 markdown with headers
