
2025-06-24 機械学習勉強会
今週のTOPIC[論文] Reinforcement Learning Teachers of Test Time Scaling[report] Llama 3.1 Swallow 8B v0.5[論文] TaskCraft: Automated Generation of Agentic Tasks[blog] 帳票VQAの舞台裏:どうやってモデルを育ててきたか[論文] Drag-and-Drop LLMs: Zero-Shot Prompt-to-Weights[論文]Don't Do RAG: When Cache-Augmented Generation is All You Need for Knowledge Tasks[Publication] An Introduction to Google’s Approach to AI Agent SecurityメインTOPICText-to-LoRA: Instant Transformer Adaption1. Introduction2. Preliminaries(予備知識)3. Text-to-LoRA: Learning to Compress and Generate LoRAs3.1. Text-to-LoRA Architectures 3.2. Training Text-to-LoRA via LoRA Reconstruction3.3. Training Text-to-LoRA via Supervised Fine-Tuning4. Experiments4.1. LoRA Compression4.2. Zero-Shot LoRA Generation5. Ablations and Analyses5.1. Increasing Training Compute Proportional to the Number of Training Tasks5.2. Task Embedding Models5.3. Varying Task Descriptions5.4. Training Schemes5.5. Visualization of T2L Activations7. Discussion and Limitations
今週のTOPIC
※ [論文] [blog] など何に関するTOPICなのかパッと見で分かるようにしましょう。
技術的に学びのあるトピックを解説する時間にできると🙆(AIツール紹介等はslack channelでの共有など別機会にて推奨)
出典を埋め込みURLにしましょう。
@Naoto Shimakoshi
[論文] Reinforcement Learning Teachers of Test Time Scaling
- Sakana AIの新作
- blog: https://sakana.ai/rlt/
- 従来のLLMにおける強化学習のアプローチは「Learning to Solve」
- 疎な報酬:正解に辿り着くまで学習のヒントがなくて非効率
- 高コスト:正解に辿り着くのにRandom性があるので、巨大なモデルと計算資源が必須
- 提案アプローチ「Learning to Teach」
- 問題と正解をpromptで与えて最適な説明の生成に特化させる教師を作成
- 教師から生徒モデルを学習させ、そのFBに密な報酬を与える

- 訓練方法
- 教師モデルはExplanationがどれくらい生徒の回答に寄与したかで報酬を得る。教師の本当の役割に集中できる。
- まずRLTの説明生成の質を上げるために強化学習 → 説明文作成 → 生徒モデル学習
- 報酬
- が生徒、 が教師
- Solution Understanding Reward
- 回答部分の対数尤度の平均値と最小値を用いて、自信を持って答えているかを表現
- Explanation Reward
- Explanationの部分が生徒にとって自然に思いつく内容なのかをKL Divergenceで定義。教師に答えを渡してるからこその説明にならないようにする意味合い。
- この辺りの設計がいいのかを相関分析などもしている。
- min/max項を設けているのは長さのbiasを考慮するため。長いと最も困難な部分などが薄まってしまう。
- 最終的なReward
- 推論時は生徒モデルだけで良い

例

- 結果
- 従来の手法よりAIME, MATH, GPQA Diamondのスコアで上回る。671BやGPT-4oなどの支援も必要ない。
- 教師モデルは全て7Bモデルで生徒は7B or 32Bという高コスパ。小さな教師 → 大きな生徒でも強い。

@Shun Ito
[report] Llama 3.1 Swallow 8B v0.5
- 東京科学大学情報理工学院の岡崎研究室と横田研究室、国立研究開発法人産業技術総合研究所の研究チーム
- Llama 3.1 8Bをベースに日本語性能を向上させた Llama 3.1 Swallow 8B v0.5 を公開
- 構築方法
- Llama 3.1 Swallow 8B v0.5ベースモデル: Llama 3.1 8Bに対して継続事前学習
- SageMaker HyperPod (H200 x 4ノード)
- Llama 3.1 Swallow 8B v0.5指示チューニングモデル: Llama 3.1 Swallow v0.5ベースモデルにSFT
- 性能
- 8Bベースモデル
- 数学・コーディングならQwen3-8B-Base, 日本語能力ならGemma-2-Llama Swallow 9BやLlama 3.1 Swallow 8B v0.5
- こういう細かいが気をつけるべきことを把握しておくのが大切。。。
- 8B事後学習モデル
- 70Bよりも性能は落ちるが、8Bではどのタスクもv0.3 → v0.5にかけて改善
- (Gemma系もやや性能高め)

※ PLaMo 2 8Bはプロンプトの末尾に改行を付与するかどうかでJHumanEvalのスコアが大きく変動します。Swallowプロジェクトの評価ではプロンプトの末尾に改行を追加することになっていますが、改行を付与しない場合にはPLaMo 2 8BのJHumanEvalのスコアは0.213から0.397に向上します。 SwallowプロジェクトではすべてのLLMに対して同一の評価条件を採用しているため、先ほどの評価結果では改行を付与した場合のスコアを採用しています。

@qluto (Ryosuke Fukazawa)
[論文] TaskCraft: Automated Generation of Agentic Tasks
OPPO AI Agent Team
自律的エージェントに必要な多段階のタスクを自動で生成するためのフレームワーク TaskCraft を提案した論文
既存の評価には下記の課題があった
- GAIAやHLEなどのベンチマークは人手で構築されており、スケールしない
- Self-InstructなどのLLMによるデータ生成手法は、ツールを使うようなタスクには向かない
TaskCraftは下記のような流れでエージェントが解くべきタスクを生成する
- Atomic Task(基本単位)
- 1回のツール呼び出しで解けるタスク。
- 例:「このPDFの中で2025年の売上はいくらか?」(PDFツールが必要)
- 拡張戦略(難易度の調整)
- Depth-based Extension(深さ方向)
- タスクを多段階に分解し、前の出力を次の入力にするようなチェーンを作る。
- 例:映画名を取得 → その監督を調べる。
- Width-based Extension(幅方向)
- 複数のサブタスクを結合し、複合問題にする。
- 例:「EPSとPERの両方を答えよ」
生成させたデータを既存エージェント(Smolagents)やLLMに解かせ、エージェントだと解くことができるものなどに絞ってデータセットを構築するなどの工夫をしている。
今回のデータでSFTを行うことで性能が向上することが確認できている
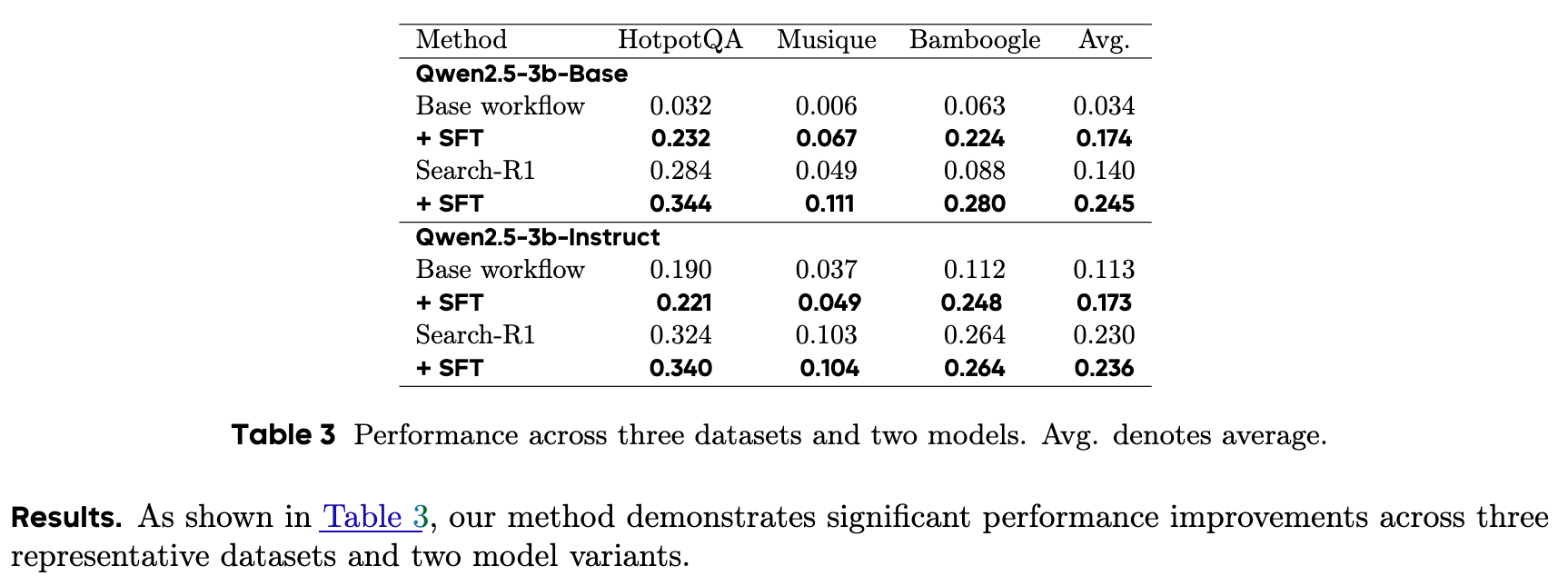
@Yosuke Yoshida
[blog] 帳票VQAの舞台裏:どうやってモデルを育ててきたか
- VQAにおける質問方法の工夫
- 初期のアプローチでは、1つの帳票画像に対して複数の質問-回答ペアを用意し、各エポックでランダムに1つだけの質問-回答ペアをサンプリングして学習 (Separated VQA)
- Separated VQAでは、項目ごとに分離されているため、個別分析がしやすい反面、学習効率には改善余地
- 各画像に対してK個の項目があり、全体でN件の学習データがある場合、1エポックあたりの1項目に関する学習はN/K回になり非効率
- また、各項目の抽出は独立して学習されるため、項目同士の関係性を生かしきれない可能性
- 複数項目を1つの質問にまとめて回答させるJoint VQA方式に変更
- Joint VQAの場合は、一枚の入力画像から複数項目の出力を同時に学習するため、1エポックあたりの1項目に関する学習はN回になり、Separated VQAのK倍
- 項目間の関係性を学習してくれているかは未検証

- 細かい文字の誤認識や、存在しない情報を生成してしまう(いわゆるハルシネーション)
- 入力画像の解像度向上
- 画像サイズを拡大することで、小さな文字や補足説明といった細かい情報の読み取り精度が向上
- 入力画像が1枚に限定されており、複数ページの帳票への対応が不十分
- 動画版のVLMで実現されている構造を流用し、複数枚の画像を扱う構造にモデルを改修し、最大4ページまでのマルチページ入力に対応
- 「正しい予測をしているにもかかわらず、自信がないためにその回答を捨ててしまう」という現象
- 確信度が低下する要因は大きく2つ
- 学習データにほとんど登場しないパターン
- 外国語で記入された書類や特殊なレイアウト
- よくあるパターンだが、微妙な差異が存在するケース
- 既知のテンプレートに似ているものの、文字の配置や表の形状がわずかに異なるケースや、画質やフォントの揺らぎによる違い
- 既存データセットに対し、モデルの推論時にスコアが低かったサンプルを自動で抽出し、それらを用いて再学習
- 再学習後、以前はスコア不足で破棄されていたケースの多くが確信度閾値を上回るようになり、実運用で採用可能な出力が増加
- 構造的な制限(最大トークン長・固定画像サイズ)によって、特定条件下で性能が頭打ち
- 長文入力対応:最大トークン長の拡張
- 書類によっては、詳細な説明が付随するケースが存在し、入力テキストがモデルのトークン上限を超える
- Position Embeddings(位置埋め込み)の上限を拡張し、長文テキストの切り捨てを防止
- 既存モデルの重みを活かしつつ拡張に対応(事前学習からの再構築は不要)
- (コスト効率よく)トークン数の上限変更を前提にした再ファインチューニングを実施
- 動的な画像サイズ入力:リサイズによる情報損失を避けるために
- これまでのモデルでは、入力画像を固定サイズにリサイズして処理
- リサイズによる画質劣化が精度低下の原因となる
- 元の画像解像度を保持したまま、あるいは動的に適切な解像度で処理できる柔軟な画像入力方式の導入を検討
- 細かい文字や位置関係が重要なフィールド(例:品目リストや注釈など)の認識精度向上が期待

学び
- 「モデルの構造そのものはもちろん重要だが、それより、データの与え方(formulation)の方も性能に与える影響が大きい」という実感
- Separated VQA から Joint VQA へ移行したことで、当初試みていたどのモデル構造の改良よりも大きな改善が得られた
- 「何を使って学ばせるか」以上に、「どう教えるか」がモデル性能を左右
- 小さな改善の積み重ねが最終的に大きな差を生む
- 画像解像度の向上、複数ページの取り込み、確信度の低い予測のフィルタリングなど、個々の施策は控えめな効果に見えましたが、積み重ねていくことで全体としての性能向上
@Takumi Iida (frkake)
[論文] Drag-and-Drop LLMs: Zero-Shot Prompt-to-Weights
| 論文タイトル | Drag-and-Drop LLMs: Zero-Shot Prompt-to-Weights |
|---|---|
| 著者 | Zhiyuan Liang¹, Yuhao Zhou¹, Xuanlei Zhao, Dongwen Tang, Wangbo Zhao, Zekai Li¹, Peihao Wang², Michael M. Bronstein, Yang You, Mingjia Shi¹, Konstantin Schürholt, Damian Borth³, Zhangyang Wang², Kai Wang¹ |
| 所属機関 | ¹National University of Singapore, ²UT Austin, ³University of St. Gallen, Oxford University |
| 投稿日 | 2025/06/19 |
| 論文リンク | https://jerryliang24.github.io/DnD |
概要
Drag-and-Drop (DnD)というLoRAの行列を直接生成することで、PEFTにかかる時間を大幅に削減。つまり、学習してLoRA行列を獲得するのではなく、生成して一発でLoRA行列を得るので数秒あれば新たなデータ・ドメインに適応できる。

LoRAだと1タスク1学習しないといけないため、この学習をさらに高速化できればPEFTのスケーラビリティがより上げられる。
DnDが目指すものとしては、「プロンプト→重み」という順伝搬を作ること。
DnDの学習・推論パイプライン

- Step 1:学習データ(LoRAのチェックポイント)の収集 様々なデータセットでLoRAを学習しまくって、プロンプトとLoRA重みのペアを作る。
データセットで学習されたLoRAと同じデータセットからランダムサンプリングされたプロンプトバッチでペアを作る。
論文中では、この少数のプロンプトバッチのことを「タスクの指紋」といっている。
Qwen2.5で以下のデータセットでLoRAチェックポイントを生成していく。

- Step 2: テキストエンベディングを入力として受け取るパラメータ生成器で、LLMの全層に対するLoRAパラメータ(いわゆるBとA行列)を生成。
Hyper-Convolutionというモジュールをカスケードした構造(下図)

- Step 3: 生成したLoRAパラメータとペアになっているLoRA行列(GT)とでMSEロスを計算して、パラメータ生成器を更新

役割
- テキストエンコーダ:タスクの性質(指紋)を理解する
- パラメータ生成器 :その理解を高次元なLoRAパラメータ空間に変換する
結果
未知のテストデータでゼロショット推論。DnDが良いAccuracyを達成。

(左図)単純にペアとなるプロンプトを増やしていくよりも、ランダムサンプリングしていくほうがスケールできて、性能があがる。
(中図)LoRAのイテレーションを増やすと逆転するが、DnDはフルショットのLoRAよりもAccuracyも高い。オーバーヘッドは圧倒的にDnDが良い。
(右図)256ショットまではDnDがFew-shot tuning (FS), In-Context Learning (ICL)よりもAccuracy面でも良い。

Ablation Study
- 条件づけとしては、純粋なプロンプトのみのほうが良い結果になる。(解答はむしろノイズになる)
- テキストエンコーダは、Sentence-BERTが最も良かった。一方で、大規模なQwen2.5-7Bは、一度に処理できるバッチサイズが厳しかったり、多様で独立した埋め込みを生成するのに適していなかったりして、失敗に終わった。

感想:一瞬でファインチューニングできるようなもんだから、できたら強そう。
@Hiromu Nakamura
[論文]Don't Do RAG: When Cache-Augmented Generation is All You Need for Knowledge Tasks
RAGには検索処理の遅延、文書選択の誤り、システムの複雑化といった課題がある。
コンテキストウィンドウが大幅に拡張されたLLMの登場を受け、リアルタイムの検索を回避するCAGを提案
CAGは、関連するリソースを事前にすべてLLMのコンテキストにロードし、ランタイムパラメータをキャッシュします。推論時には、外部への検索なしでこれらのパラメータを利用して応答を生成。
CacheはTransformerのKey-Value Cacheを使うパターンとテキストそのものを「キャッシュ」としてLLMの長いコンテキストに事前に読み込むパターンがある。

SQuAD 1.0とHotPotQAという2つのQAベンチマークでCAGの有効性を検証。文書数やトークン数を変えた複数のテストセットを用意し、RAG(BM25によるスパースリトリーバsparse search、OpenAI IndexesによるDense search)と比較。

かつレスポンスタイムも良い

補足)HotPotQAのsize例
• Small:16文書(約21,000トークン)
• Medium:32文書(約43,000トークン)
• Large:64文書(約85,000トークン)
• CAGの効率性とRAGの柔軟性を組み合わせた「ハイブリッド型」も提案されているらしい。
ponの感想:
- サービスのマニュアルとかなら収まりそう。レスポンスタイムも良くなるので検討の余地はある。
- LargeからBERTScoreの差が縮まってくる。どれくらいの大きさから負けてくるのかは気になる。
- 動的な更新が必要なデータへの対応ができないから利用範囲むずい。
@ShibuiYusuke
[Publication] An Introduction to Google’s Approach to AI Agent Security
概要
このドキュメントは、自律的にタスクを実行するAIエージェントの可能性と、それに伴うセキュリティ上のリスクについて論じています。特に「不正なアクション(Rogue actions)」と「機密データの漏洩(Sensitive data disclosure)」を主要なリスクとして挙げ、これらのリスクに対処するためのGoogleのセキュリティアプローチを説明しています。Googleは、従来のセキュリティ対策とAIの推論に基づく防御を組み合わせた「ハイブリッドな多層防御」を提唱しており、その中核となる3つの基本原則(人間の管理者、権限の制限、アクションの可観測性)を詳述しています。
- Introduction: The promise and risks of AI agents
- ユーザーの目標達成のために自律的に行動し、ビジネスや個人のテクノロジーとの関わり方を変える大きな可能性を秘めたAIエージェントの登場。
- その自律性ゆえに生じる「不正なアクション」や「機密データの漏洩」といった新たなセキュリティリスクの発生。
- AIの能力を活かしつつリスクを管理するための、従来の対策を超えた新しいアプローチの必要性。

- Security challenges of how AI agents work
- AIエージェントの動作プロセスの各段階(入力、知覚、推論、ツール連携、記憶など)に存在するセキュリティ上の課題。
- 信頼できる指示と信頼できない外部情報の区別の困難さ、および悪意のある指示(プロンプトインジェクション)によるエージェント乗っ取りの危険性。

- Key risks associated with AI agents
- 不正なアクション: プロンプトインジェクションや指示の誤解による、エージェントの意図しない有害な行動のリスク。
- 機密データの漏洩: エージェントが騙され、攻撃者に機密情報を漏洩するリスク。URLへのデータ埋め込みなどの手口。
- Core principles for agent security
- Principle 1: Agents must have well-defined human controllers 明確な人間の管理者: 行動に責任を持つ人間の管理者の明確な定義。重要な操作に対する人間による承認の必須化。
- Principle 2: Agent powers must have limitations 権限の制限: 目的やタスクに応じたエージェントの能力やアクセス情報の動的な制限(最小権限の原則)。
- A2Aの認証認可:‣
- Principle 3: Agent actions and planning must be observable アクションと計画の可観測性: 行動、推論プロセス、データソースなどの記録による、透明性と監査可能性の確保。
- A2A Tracing, observability & monitoring: ‣

- Google’s approach: A hybrid defense-in-depth
- 従来の決定論的セキュリティとAIの推論を活用した動的防御を組み合わせたハイブリッド戦略の採用。
- 推論プロセスが侵害された場合でも最終的な被害を食い止める、多層的アプローチによる防護壁の構築。
- 継続的なテストや専門家チーム(レッドチーム)による攻撃シミュレーションを通じた、セキュリティの常時検証と強化。

- 感想
- 今後はAI AgentのためのIAMやchaos monkeyみたいなツールが出てくる気がする。
メインTOPIC
Text-to-LoRA: Instant Transformer Adaption
1. Introduction
背景
- LLMは非常に高い汎用的な能力を持つ一方で、特定のタスクを高い性能で取り扱うためにはタスクに特化させる必要がまだ存在する。
- モデルのパラメタすべてを学習しなおすのではなく、一部のパラメタのみを学習する LoRA(Low-Rank Adaptaion) のような手法が一般的になってきた。
- LoRAが効率的なファインチューンの手法であるといえども、下流タスクごとにデータセットを準備する必要があるし一定以上の学習コストもかかる。また、ハイパーパラメターの調整も必要。まだまだ効率性や柔軟性におけるエンジニアリングのオーバーヘッドが大きい。
- 最近は、LoRAによって学習された低ランク行列を下流タスクの性能を保ちつつさらに圧縮する手法や、複数のLoRAを新しい未知のタスクにおける推論に利用する手法なども提案されている。
- これらの手法の根幹には、既存のLoRAをうまく圧縮したりうまく組み合わせたりするための行列分解や次元削減の技術の発展が存在する。
以上を踏まえた上でのRQ
- 多くの事前学習済みLoRAを圧縮するために、エンドツーエンドでニューラルネットワークを訓練できるか? / Can we end-to-end train a neural network to compress many pre-trained LoRAs?
- (補足)たくさんのタスク特化 LoRA をうまく組み合わせまくればいろんなタスクに対応できるはずだけど、そのままのサイズでは使いづらいから圧縮したいよね。でも現状はいろんな分解・圧縮手法に依存しているから、e2eで実現しちゃえると嬉しいよね。というお気持ちだと解釈した。
- テスト時に未知のタスクに対する自然言語指示のみに基づいて、新しいタスク固有のLoRAアダプターをデコードできるか? / Can we decode new task-specific LoRA adapters solely based on natural-language in- structions for an unseen task at test time?
- (補足)個別のファインチューニングはコストが高いのでそもそもやりたくない。タスクを説明するだけで特化LoRAができたら最高じゃん。
提案手法
- 推論時に自然言語によるタスクの説明をもとにゼロショットでそのタスクに合わせたLoRAアダプタを生成するハイパーネットワークであるT2L(Text-to-LoRA)の提案。
- タスクごとの異なるLoRAアダプタが同じ適用メカニズムを基盤として共有しており、特別な構造を持たなくても、e2eでうまく同時に学習できるという仮説のもと。

Contributions
- テキスト記述に基づいて、単一のフォワードパスでLoRAアダプターを生成するハイパーネットワークベースのアーキテクチャを導入。事前学習済みアダプターの蒸留と教師ありマルチタスクファインチューニングの両方で訓練可能。
- T2Lが数百のLoRAアダプターを効率的にエンコードできることを示し、損失のある圧縮でもタスク特化型LoRAアダプターの性能を維持することを示した。また、適切な自然言語記述があれば、未知のタスクにも汎化可能であることも示した。
- T2Lのデータセットによるスケーリング、異なるタスク記述埋め込みの影響、トレーニングルーチン、テキストベースのタスク記述など様々な観点でのAblation Studyを実施
- T2Lの生成物の性質を分析し、次元削減空間で生成されたLoRAを可視化すると、意味のあるLoRAクラスターが見つかることを発見。
2. Preliminaries(予備知識)
LoRA(Low-Rank Adaptation)
- 事前学習済みモデルの重みを固定し、低ランク行列∆W のみを学習。
- ∆W は基盤モデルへのアダプターとして機能。
- 各線形変換 h = W₀x に対して:h = W₀x + ΔWx = W₀x + B^T Ax
- A, B ∈ R^(r×d) はランクr < dの重み行列
ハイパーネットワーク
- 別のベースネットワークのパラメータを生成するニューラルネットワーク
- ベースネットワークよりもはるかに小さなパラメタ数であるため、ベースネットワークの”間接的なエンコーディング”として機能
- 「適当なベクトル → hypernetworks → 欲しいベースネットワーク」となるように学習する。
- 下流タスクでe2eでファインチューニングして学習。
- 蒸留みたいなイメージか。
3. Text-to-LoRA: Learning to Compress and Generate LoRAs
基本構造
- 対象のベースモデルについて、モジュール(m)と層インデックス(l)ごとに、タスク(t)の記述(z)に基づいて2つの低ランク行列A, BつまりΔWを生成する
- f は自然言語で記述されたタスクを処理する適当なエンコーダー


3.1. Text-to-LoRA Architectures
- ハイパーネットワークのパラメタサイズのほとんどは最終出力層に依存する(はるかに大きい生成対象のベースモデルのパラメタに依存するため)。
- ハイパーネットワークのサイズと性能のトレードオフを検証するため、L / M / S の3パターンを用意。
- L :最も大きい。最終線形層が低ランクのAとB行列を同時に出力。
- M:中間サイズ。低ランクのAとB行列間で出力層を共有する。学習可能な埋め込みによって、AかBのいずれかを出力。
- S:最も小さい。一度に低ランク行列の1つのランクのみを出力。学習可能な埋め込みによって、AかBのいずれかを出力を決めるのと、ランクも決める。
3.2. Training Text-to-LoRA via LoRA Reconstruction
- T2Lを学習する最も直接的な方法は、事前学習済みタスク固有のLoRAを再構築する設定。reconstruction lossを用いる。
- 一般的にはone-hot なり適当な学習可能なベクトルを初期値とすればいいが、今回はゼロショットでタスクを解くためのLoRAアダプタを生成したいので、タスク記述のenbedding を利用する。
3.3. Training Text-to-LoRA via Supervised Fine-Tuning
- あるいは下流タスクを用いて直接教師ありで学習することも可能。あくまで中間的な生成物であるLoRAアダプターを必要とせず(その再現を目的としない)、e2eの学習を可能とする。
- 既存の学習済み特化LoRAアダプターが、ダウンストリームタスクの種類に応じた分布になっていない場合、このほうが嬉しいはず。
- 似ている下流タスクを解いているLoRAアダプタは似ていてくれると嬉しい、汎化が期待できるが、実際はそうはなっていないであろうという仮説。
4. Experiments
目的
- T2Lの異なるアーキテクチャ(L / M / S)と、異なる学習方法(Reconstruction / e2e SFT)を比較
- アダプターの圧縮による影響や、ゼロショットLoRA生成によるタスク性能を調査
ベースライン
- タスク特化のLoRA
- 要素ごとの平均LoRA(element-wise averaged LoRA)
- マルチタスクLoRA(すべての訓練タスクで訓練された単一のLoRAアダプタ)
設定
- ベースのLLMとしてはMistral-7B-Instruct18 を利用。一部設定では Llama-3.1-8B-Instruct と Gemma-2-2B-Instruct も。
- タスク記述のエンコードには gte-large-en-v1.5 を利用。
- LoRAアダプタのランクは 8 に固定。ベースLLMの各アテンションブロックの q, v モジュールのみを対象にした(トータル 3.4M パラメタ)。
- この構成でハイパーネットワークの L、M、Sはそれぞれ55M、34M、5Mの訓練可能なパラメータを持つ。
データセット
- LoRAアダプターの訓練には SNI データセットを使用。
- 500タスクを利用し、479を訓練、11を検証ように(10は消えた)。
- 評価には、推論、数学、コーディングなどなど様々な種類のLLMの能力を測れるように10のベンチマークを利用
4.1. LoRA Compression
- Reconstruction学習によって再構築されたLoRAアダプタを利用した性能が、タスク特化に学習されたLoRAアダプタと比較してどうか?(圧縮しても性能を維持できるか?)
- ベースモデル(純粋LLM)とOne-Hot を使った場合の T2L とタスク定義の埋め込みベクトルを使った場合のT2L ととタスク特化 LoRAでの比較
- T2Lはどちらの埋め込みを使った場合でも、タスク特化LoRAの性能に負けず劣らない、場合によっては性能を上回る(緑のハイライト)ことを示した。
- 圧縮が正則化的な役割を担ったからではと考察。タスク特化がベースモデルに負けていたりさほど伸びていない PIQA やWG で顕著なことからも。

- 訓練タスクを増やすと?
- Reconstructionエラーはどんどん大きくなるが、性能劣化は下げ止まる。
- → 訓練タスクをたくさん増やしてSFTが有効!(ちょっとよくわからんかった)

4.2. Zero-Shot LoRA Generation
- T2Lが未知のタスクに対して有用なLoRAアダプターを生成できるのか?マルチタスク
- SFTで学習したT2Lは、一貫してマルチタスクLoRAを上回る(Bold)
- SFTで学習したT2Lは、一部のタスクでは特化 LoRA を上回る(緑ハイライト)

5. Ablations and Analyses
5.1. Increasing Training Compute Proportional to the Number of Training Tasks
- 訓練タスク数・計算資源を増やすと T2L の性能は高くなる。
- ただしSはモデルサイズが限られているためか、479タスクまで増やした際の恩恵がなかった(性能が落ちた)

5.2. Task Embedding Models
- gte-large-en-v1.5とMistral-7B-Instructという2つの異なる埋め込みモデルを使用して比較
- あんまり性能が変わらなかった(変わらず高かった)ので、テキストエンコーダーに対してロバスト

5.3. Varying Task Descriptions
- タスクの記述によってどこまでパフォーマンスに差が出るのが比較
- Train: Training descriptions of corresponding tasks.
- Eval: Unseen descriptions of corresponding tasks.
- りーくっぽい設定?
- Random strings: Random literal strings.
- Train (random): Training descriptions randomly sam- pled from other tasks.
- タスクとその記述が一致している場合に高い性能。つまり、正しいタスクの記述に意味がある。
- ランダムでもそこそこ性能出るなとは思った。

- 定性的な比較
- (i)がベースモデルで間違った推論をしており、(ⅱ)は微妙な記述しかないのでまだ不正解。
- (ⅲ)(ⅳ)ともにいい感じの記述をすると正解に辿り着いているが、前者は数学っぽい思考で解いていて、後者はプログラミングっぽく解いている。
- → T2L の操作可能性の示唆

5.4. Training Schemes
- Reconstruction vs SFT

5.5. Visualization of T2L Activations

- T2Lのタスクエンコーダー(左)と最終出力 / アダプター(右)をt-SNEでplot
- 同じタスク(同じ色・形)がいい感じにクラスタリングされていることがわかる。
- MBPPとHumanEvalのような、似ているタスク(コード生成系)が近くにクラスタリングされていることも見える → 未知タスクに対しても汎用的に対応できる
7. Discussion and Limitations
Disucusison
- T2Lは、高品質で一貫したタスク記述を保証するために、GPT-4o miniによって生成された記述に依存している。一方、実世界では、ユーザーが質の低い記述を入力する可能性があり、その場合、生成されるアダプターの性能が低下する可能性がある。
- T2Lは主にLLM適応に焦点を当てていますが、他のLLMや視覚言語モデルにも直接適用できる。
- 小規模なベースモデルで訓練されたT2Lが、同じアーキテクチャクラスのより大規模なモデルに効果的に転送できる可能性は、未開拓の領域
Limitation
- T2Lは出力空間としてLoRAのみを考慮している。テキスト記述が与えられた場合にLLMを調節するより効率的な方法が存在する可能性もある。
- T2Lによる圧縮は、適切に設計された誘導バイアスを使用することでさらに最適化できる可能性がある。
- T2Lはロバストさとスケーラビリティの兆候を示すものの、ゼロショットでタスク固有のLoRAのベンチマーク性能には達していない。