2025-07-25 機械学習勉強会
今週のTOPIC[blog] Context Engineering for AI Agents: Lessons from Building Manus[blog] LLM Servingを支える技術[oss] LMCache[blog]コンテキストエンジニアリングがなぜ重要なのか[論文] Zep: A Temporal Knowledge Graph Architecture for Agent MemoryInfiniteHiP: Extending Language Model Context Up to 3 Million Tokens on a Single GPU1. Introduction背景と課題既存手法InfiniteHiPの概要2. Related Works3. Motivations and Observations4. Designs of InfiniteHiP5. Experiments5.1. Experiment Setting5.2. Results5.3. Analysis
今週のTOPIC
※ [論文] [blog] など何に関するTOPICなのかパッと見で分かるようにしましょう。
技術的に学びのあるトピックを解説する時間にできると🙆(AIツール紹介等はslack channelでの共有など別機会にて推奨)
出典を埋め込みURLにしましょう。
@Yuya Matsumura
[blog] Context Engineering for AI Agents: Lessons from Building Manus
- Manusプロジェクトの立ち上げ当初、オープンソースの基盤を使用してエンドツーエンドのエージェントモデルをトレーニングするか、フロンティアモデルのインコンテキスト学習能力に基づいてエージェントを構築するかという重要な決断に直面しました。
- 過去のNLPの時代、BERTなどのモデルは新しいタスクに移行する前にファインチューニングと評価が必要であり、このプロセスには数週間かかることもありました。このような遅いフィードバックループは、特に製品市場適合性(PMF)以前の急速に変化するアプリケーションにとっては致命的であるという苦い経験があったため、Manusはコンテキストエンジニアリングに賭けることを選択しました。これにより、改善を数時間で出荷できるようになり、製品を基盤となるモデルから独立させることができました。
- しかし、コンテキストエンジニアリングは決して単純なものではありませんでした。それは実験科学であり、より良いコンテキストの形成方法を発見するたびに、エージェントフレームワークを4回も再構築しました。このアーキテクチャ探索、プロンプト調整、経験的推測といった手動のプロセスを、彼らは「確率的卒業降下(Stochastic Graduate Descent)」と呼んでいます。
Design Around the KV-Cache(KV-キャッシュを中心に設計する)
AIエージェントが製品段階にある場合、KV-キャッシュヒット率が単一の最も重要な指標であるとされています。これはレイテンシとコストの両方に直接影響します。
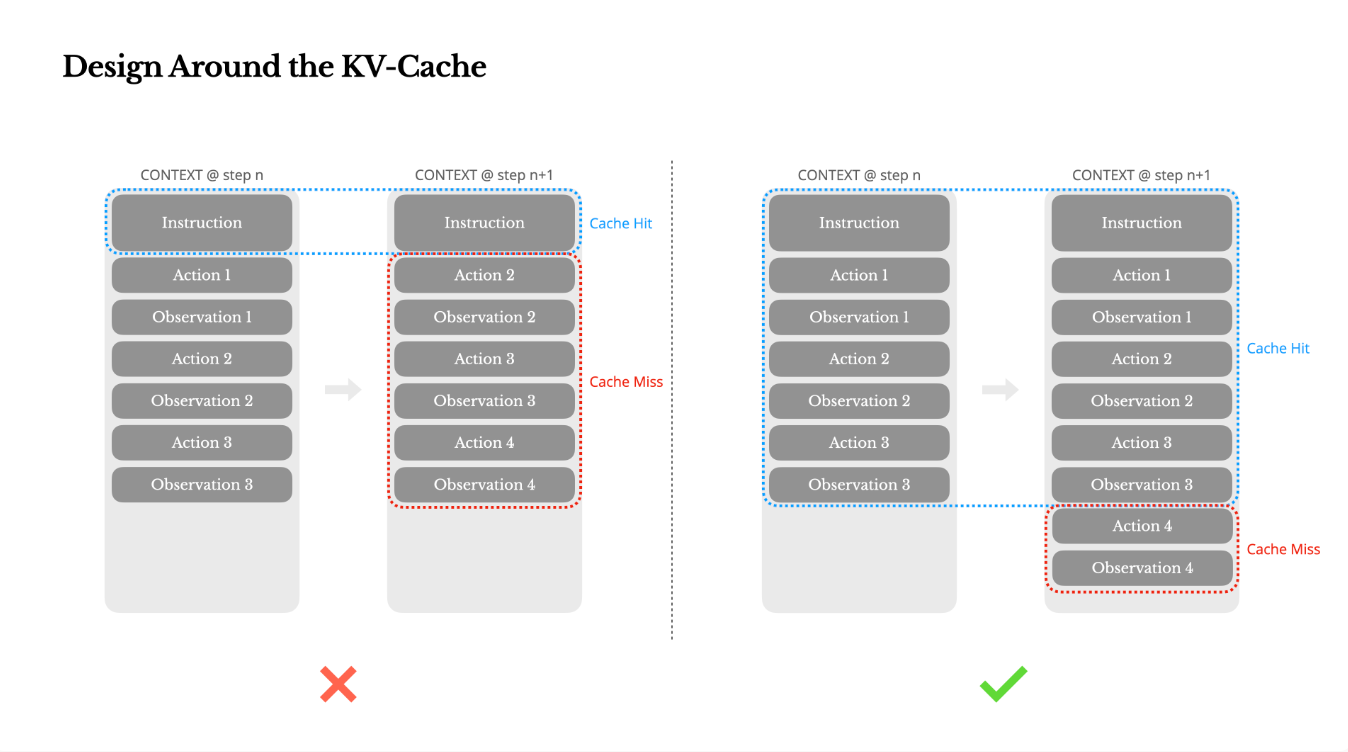
- エージェントの動作の中では、出力(通常は構造化された関数呼び出し)が比較的短いにもかかわらず、コンテキストがステップごとに増加する。
- Manusでは、平均的な入力対出力のトークン比率は約100:1にも。
- 同一のプレフィックスを持つコンテキストはKV-キャッシュの恩恵を受けることができ、これにより、初回トークンまでの時間(TTFT)と推論コストが大幅に削減される。
- たとえば Claude Sonnetでは、キャッシュされた入力トークンは0.30 USD/MTokであるのに対し、キャッシュされていないトークンは3 USD/MTokと、10倍の差がある。
- KV-キャッシュヒット率を向上させるための重要な実践方法には以下があります:
- プロンプトプレフィックスを安定させる: LLMの自己回帰的な性質上、わずか1トークンの違いでもキャッシュが無効になる可能性があります。システムプロンプトの冒頭にタイムスタンプ(特に秒単位の精度)を含めることは、キャッシュヒット率を低下させる一般的な間違いです。
- コンテキストを追記専用にする: 以前のアクションや観測を修正することを避けてください。シリアライゼーションが決定論的であることを確認することが重要です。多くのプログラミング言語やライブラリはJSONオブジェクトのシリアライゼーションにおいて安定したキー順序を保証しないため、これが原因でキャッシュが静かに破損することがあります。
- 必要に応じてキャッシュブレークポイントを明示的にマークする: 一部のモデルプロバイダーや推論フレームワークは自動的な増分プレフィックスキャッシュをサポートしていないため、コンテキストに手動でキャッシュブレークポイントを挿入する必要があります。ブレークポイントを設定する際は、キャッシュの有効期限を考慮し、少なくともシステムプロンプトの終わりまでを含めるようにしてください。また、vLLMのようなフレームワークを使用してモデルを自己ホストしている場合は、プレフィックス/プロンプトキャッシュが有効になっていること、およびセッションIDなどの技術を使用して分散ワーカー間でリクエストが一貫してルーティングされるようにしてください。
Mask, Don't Remove(削除ではなくマスクする)
エージェントがより多くの機能を持つようになると、そのアクションスペースは自然と複雑になり、ツールの数が爆発的に増加します。動的にツールを追加または削除しようとすると、以下の2つの主な理由から問題が生じる可能性があります:
1. ほとんどのLLMでは、ツール定義はシリアライゼーション後、コンテキストの先頭付近(通常はシステムプロンプトの前または後)に配置されるため、変更があるとそれ以降のすべてのアクションと観測のKV-キャッシュが無効になります。
2. 以前のアクションや観測が、現在のコンテキストで定義されなくなったツールを参照している場合、モデルは混乱します。制約なしのデコーディングでは、これがスキーマ違反や幻覚的なアクションにつながることがよくあります。
この問題を解決しつつアクション選択を改善するために、Manusはコンテキストアウェアなステートマシンを使用してツールのアベイラビリティを管理します。ツールを削除する代わりに、デコーディング中にトークンロジットをマスキングして、現在のコンテキストに基づいて特定のアクションの選択を防止(または強制)します。
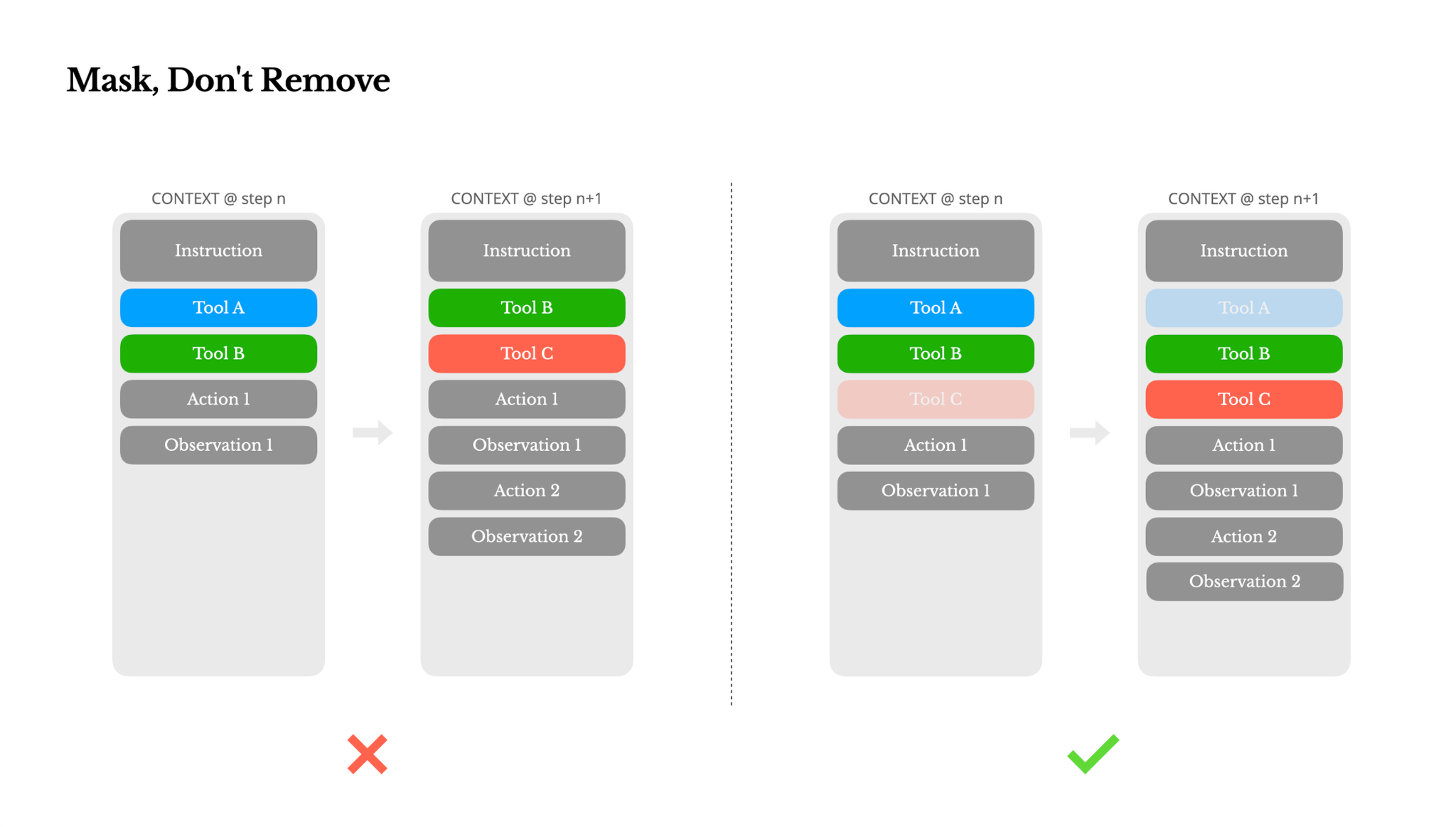
実際には、ほとんどのモデルプロバイダーや推論フレームワークは、レスポンスプリフィルの何らかの形式をサポートしており、これによりツール定義を変更することなくアクションスペースを制約できます。関数呼び出しのモードは一般的に3つあります(Hermes形式を例にとると):
- Auto: モデルが関数を呼び出すかどうかを選択できる。
- Required: モデルが関数を呼び出す必要があるが、選択は制約されない。
- Specified: モデルが特定のサブセットから関数を呼び出す必要がある。
Manusでは、アクション名を意図的に一貫したプレフィックス(例: ブラウザ関連のツールはすべて、コマンドラインツールは)で設計することで、特定の状態でエージェントが特定のツールグループからのみ選択するように簡単に強制できます。これらの設計は、モデル駆動型アーキテクチャの下でもManusエージェントループが安定していることを保証するのに役立ちます。
Use the File System as Context(ファイルシステムをコンテキストとして使用する)
現代のフロンティアLLMは128Kトークン以上のコンテキストウィンドウを提供していますが、実際のエージェントシナリオでは、それが十分でない場合が多く、時には負債となることもあります。一般的な課題は以下の3点です:
1. 観測が巨大になる可能性がある: 特にエージェントがウェブページやPDFのような非構造化データとやり取りする場合、簡単にコンテキスト制限を超えてしまいます。
2. モデルの性能が低下する傾向がある: コンテキストが長くなると、技術的にウィンドウがそれをサポートしていても、モデルの性能は低下する傾向があります。
3. 長い入力はコストがかかる: プレフィックスキャッシュを使用しても、すべてのトークンを送信してプリフィルするためにコストがかかります。
この問題に対処するため、多くのエージェントシステムはコンテキストの切り捨てや圧縮戦略を実装していますが、過度に積極的な圧縮は必然的に情報損失につながります。根本的な問題は、エージェントは本質的にすべての以前の状態に基づいて次のアクションを予測しなければならず、どの観測が10ステップ後に重要になるかを確実に予測することはできないという点です。
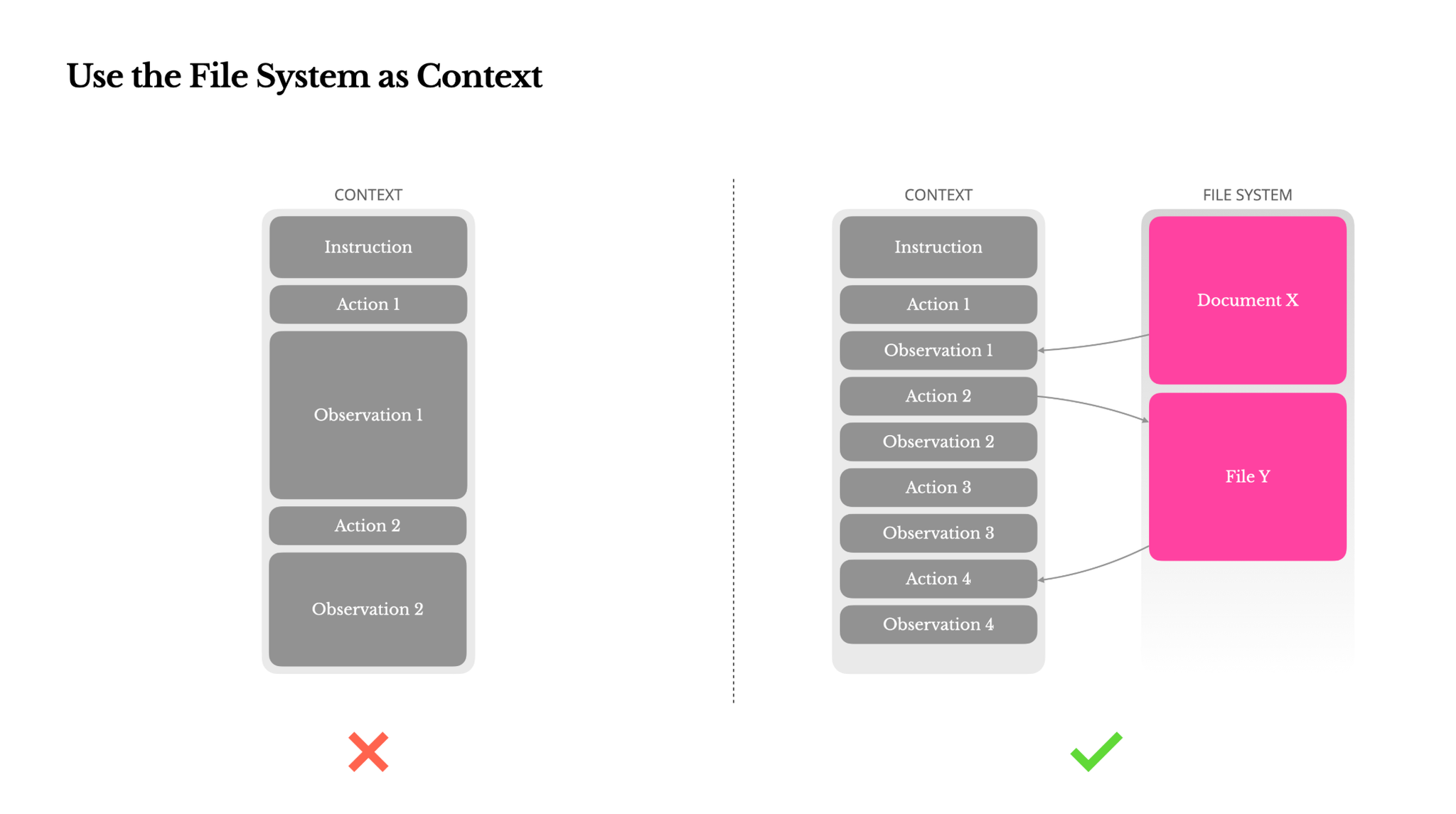
そこでManusでは、ファイルシステムを究極のコンテキストとして扱います。これはサイズが無制限で、本質的に永続的であり、エージェント自身が直接操作できます。モデルはファイルにオンデマンドで書き込み、読み込むことを学習し、ファイルシステムを単なるストレージとしてだけでなく、構造化された外部化されたメモリとして使用します。
Manusの圧縮戦略は常に復元可能に設計されています。例えば、ウェブページのコンテンツはURLが保持されていればコンテキストから削除できますし、ドキュメントのコンテンツもサンドボックス内でパスが利用可能であれば省略できます。これにより、Manusは情報を永久に失うことなくコンテキスト長を短縮できます。この機能の開発中、筆者はステートスペースモデル(SSM)がエージェント設定で効果的に機能するためには何が必要かを想像しました。SSMはTransformerとは異なり、完全なアテンションを欠き、長距離の逆方向依存関係に苦戦しますが、ファイルベースのメモリをマスターし、長期状態をコンテキスト内に保持するのではなく外部化できれば、その速度と効率が新しいクラスのエージェントを可能にするかもしれません。
Manipulate Attention Through Recitation(繰り返しでアテンションを操作する)
Manusを使ったことがあるユーザーは、複雑なタスクを処理する際に「todo.md」ファイルを作成し、タスクの進行とともにステップバイステップで更新し、完了した項目にチェックを入れるという奇妙な動作に気づくかもしれません。これは単なる可愛らしい行動ではなく、アテンションを操作するための意図的なメカニズムです。
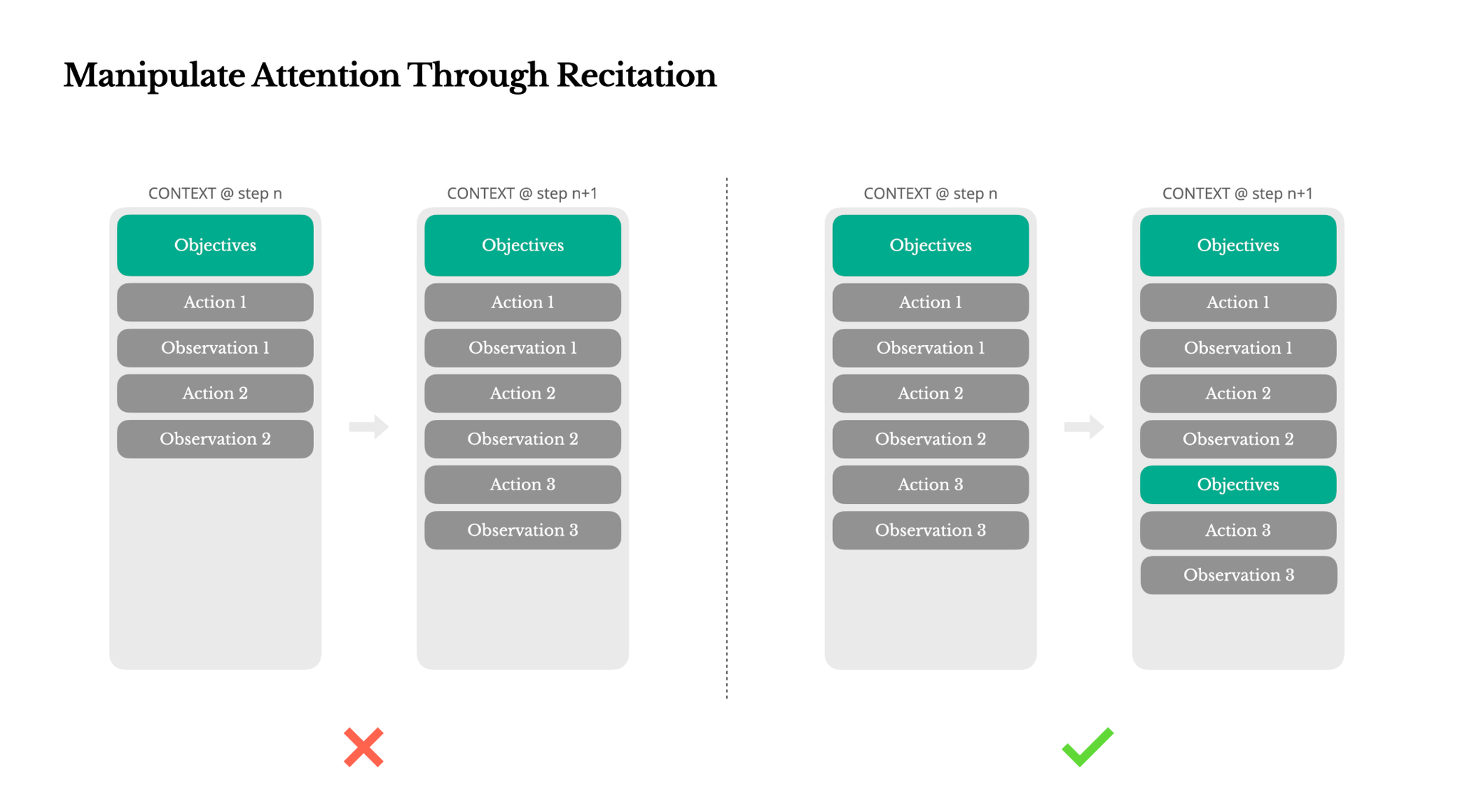
Manusにおける典型的なタスクは、平均で約50回のツール呼び出しを必要とします。これは長いループであり、Manusは意思決定のためにLLMに依存しているため、特に長いコンテキストや複雑なタスクでは、話題から外れたり、以前の目標を忘れたりする脆弱性があります。todoリストを継続的に書き換えることで、Manusは目標をコンテキストの末尾に繰り返し記述しています。これにより、全体的な計画がモデルの最近のアテンション範囲に押し込まれ、「中途半端に失われた(lost-in-the-middle)」問題を回避し、目標の不整合を減らします。実質的に、特別なアーキテクチャの変更を必要とせずに、自然言語を使用して自身の焦点をタスク目標に偏らせているのです。
Keep the Wrong Stuff In(失敗をそのままにする)
エージェントは間違いを犯します。これはバグではなく、現実です。言語モデルは幻覚を起こし、環境はエラーを返し、外部ツールは誤動作し、予期せぬエッジケースが常に発生します。複数ステップのタスクでは、失敗は例外ではなく、ループの一部です。それにもかかわらず、これらのエラーを隠そうとするのが一般的な衝動です。トレースをクリーンアップし、アクションを再試行し、モデルの状態をリセットして「温度」に任せる、といったことです。それはより安全で、より制御されているように感じられますが、コストがかかります。失敗を消去することは証拠を消去することです。そして、証拠がなければモデルは適応できません。
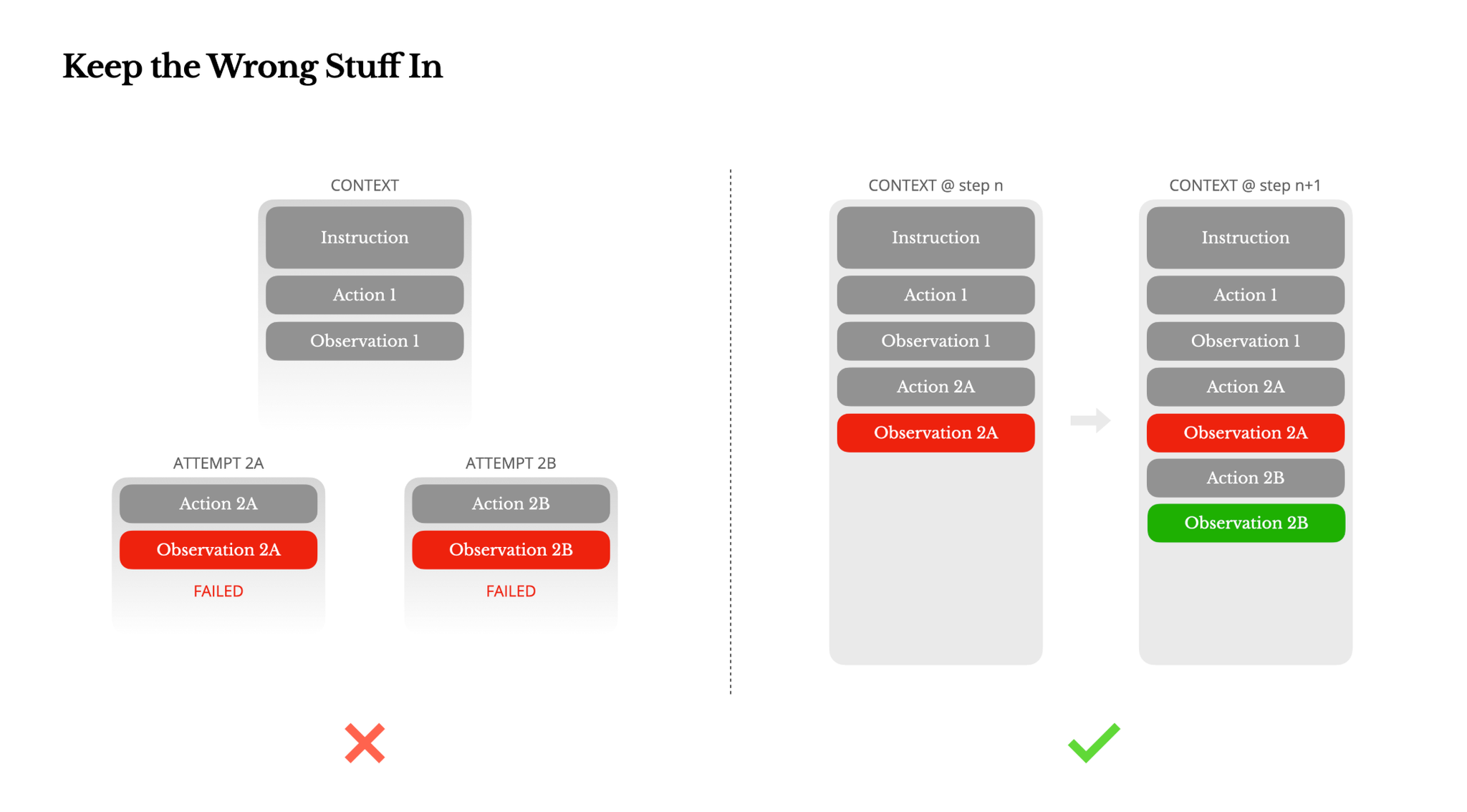
Manusの経験上、エージェントの行動を改善する最も効果的な方法の1つは、驚くほどシンプルです。それは間違った道をコンテキストに残しておくことです。モデルが失敗したアクションと、結果として生じる観測やスタックトレースを見ると、暗黙的に内部の信念を更新します。これにより、同様のアクションへの事前確率がシフトし、同じ間違いを繰り返す可能性が減少します。実際、エラー回復こそが真のエージェント行動を示す最も明確な指標の1つであると彼らは考えています。しかし、理想的な条件下でのタスクの成功に焦点を当てる学術研究や公開ベンチマークでは、依然として十分に評価されていません。
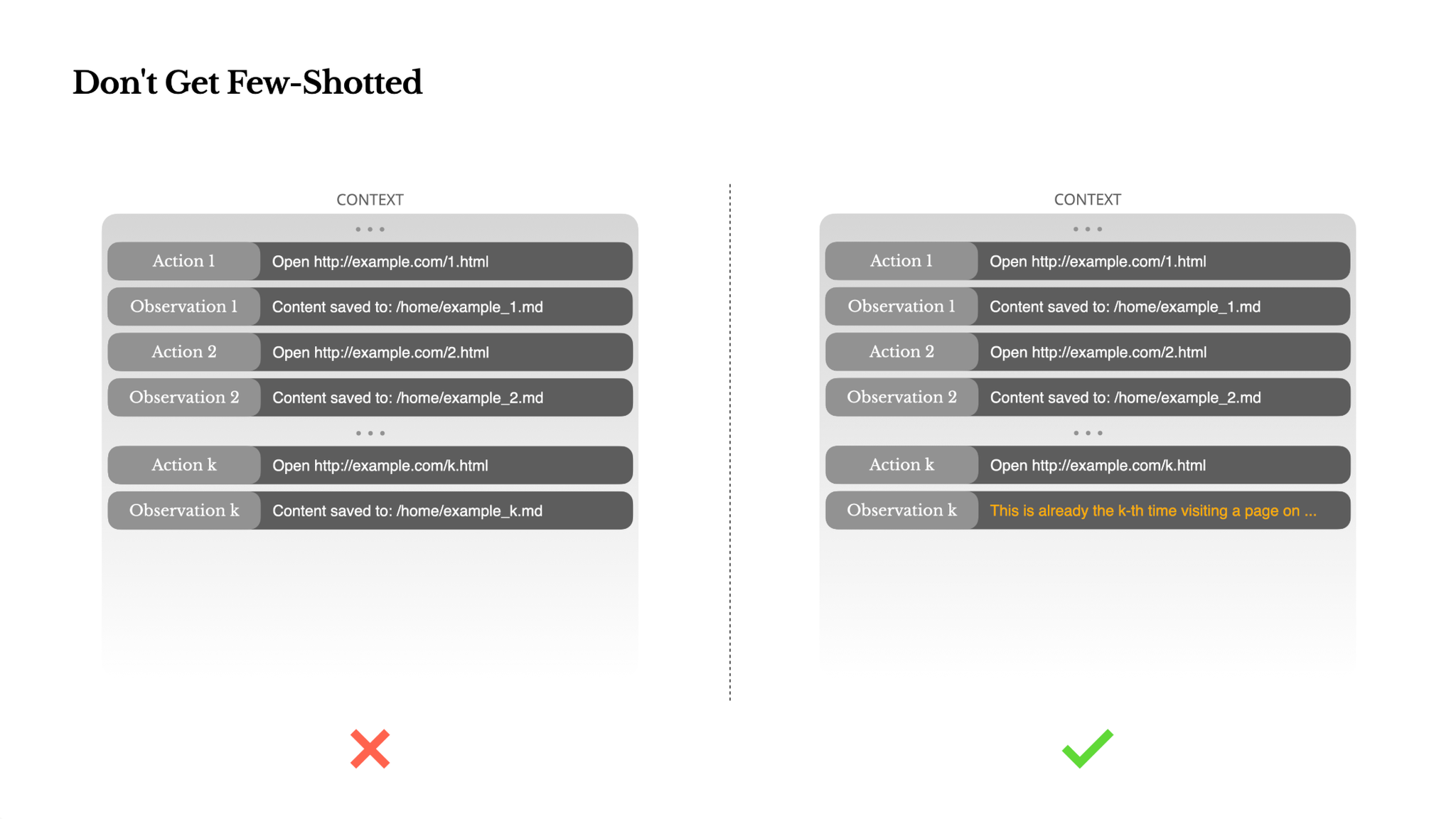
Don't Get Few-Shotted(フューショットで固定化されない)
フューショットプロンプティングはLLMの出力を改善するための一般的なテクニックですが、エージェントシステムでは微妙な形で裏目に出ることがあります。言語モデルは優れた模倣者であり、コンテキスト内の行動パターンを模倣します。コンテキストが類似した過去のアクションと観測のペアで満たされている場合、モデルはそのパターンに従う傾向があり、それが最適でなくなっても従い続けます。これは、反復的な決定やアクションを伴うタスクでは危険な場合があります。例えば、Manusが20の履歴書をレビューするのを手伝う際、エージェントはしばしば同じようなアクションを繰り返すリズムに陥り、コンテキストにそれが示されているという理由だけでそうします。これは、ドリフト、過剰な一般化、または時には幻覚につながります。
解決策は、多様性を増やすことです。Manusは、アクションと観測に少量の構造化されたバリエーション(異なるシリアライゼーションテンプレート、別の表現、順序やフォーマットの軽微なノイズなど)を導入します。この制御されたランダム性がパターンを破り、モデルのアテンションを微調整するのに役立ちます。言い換えれば、フューショットによって溝にはまってはならないということです。コンテキストが均一であればあるほど、エージェントは脆くなります。
@Shun Ito
[blog] LLM Servingを支える技術
- LLMのservingで使われているテクニックを体系的に紹介している記事
- バッチ推論
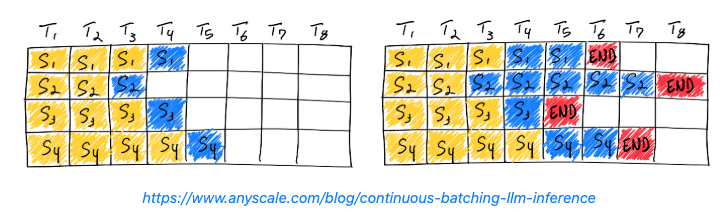
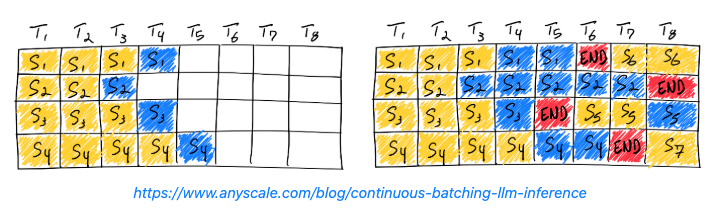
- Continuous Batching
- 1つ前のバッチ処理がすべて終わってから次のバッチを開始するのではなく、バッチに空きが出るたびに新しいリクエストを割り当てていく
- KVキャッシュマネジメント
- リクエストそれぞれに最大コンテキスト長までKVキャッシュ用のメモリを確保するのは冗長
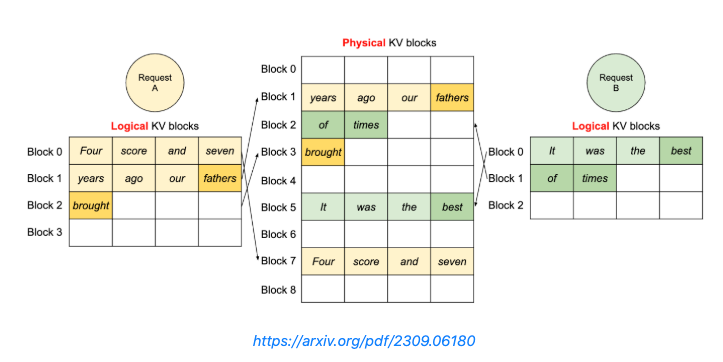
- PagedAttention
- 固定サイズの物理バッファを用意し、リクエストが終了したタイミングで解放する
- Prefixキャッシュ
- プロンプトのprefixが共通であればそれを使い回すようなキャッシング
- 例: RadixAttention
- アルゴリズムの工夫
- モデルの計算を簡略化して効率改善する
- 量子化
- Weight-only quantization: 重みパラメータのみ量子化
- 重みが小さくなりmemory-boundの領域で計算効率が上がる。小さなバッチサイズで推論をする際に有効
- Weight-activation quantization: 重みパラメータと入力値(activation)両方を量子化
- 行列計算が低ビットになり、Tensor Coreなどの低ビット計算に最適化されたハードウェアが利用可能。バッチサイズが大きくcompute-boundなケースでも推論のスループットを高められる
- KVキャッシュのスパース化
- 長系列に対応しメモリ消費を抑えるため、KVキャッシュのうち重要なものだけを残しそれ以外は捨てるようにする
- StreamingLLM: 最初の数トークンのKVキャッシュは常に保持しておくようにする(文頭のトークンは人間的には意味がなくてもLLM的には重要=attentionスコアが高くなることが多いというヒューリスティックに基づいている)
- パラメータのスパース化
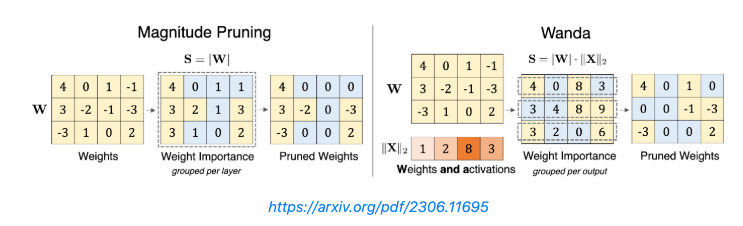
- Wanda: 重みと対応するactivationの値の積の絶対値が小さい(=出力に与える影響が小さい)ものをプルーニングし、推論効率を上げる
- 投機的デコーディング(Speculative Decoding)
- 以前の勉強会で紹介された、小さいLLMを使って大きいLLMのトークン生成を高速化する手法
- 構造的デコーディング(Structured Decoding)
- LLMの生成する文章を特定のフォーマットに制御する。生成時のlogitsを操作し、次のトークンが確定する場合は推論のサイクルを減らせる
- マルチモーダル
- モデルアーキテクチャの工夫
- MQA, GQA, MLA
- Multi-Head Attention: 全てのheadにKey, Valueの別のheadがある
- Multi-Query Attention (MQA): Key, Valueのheadは1つのみ
- Grouped-Query Attention (GQA): Key, Valueのheadはグループごとに1つ
- 最近のLLMはほとんどこれ
- Multi-head Latent Attention (MLA): Key, Valueの値を低ランク行列に圧縮
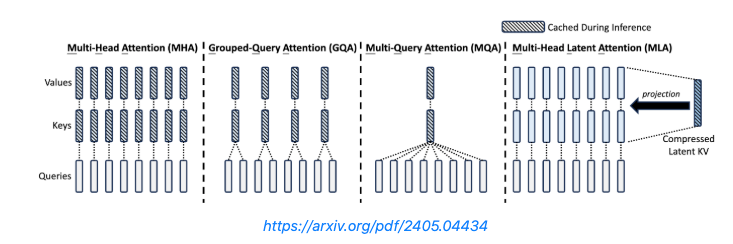
- その他様々な手法が紹介されているので、元ブログをぜひ!
@Yosuke Yoshida
[oss] LMCache
- LMCacheはLLMの推論エンジン拡張で、TTFT(最初のトークン応答時間)を短縮し、スループットを向上
- 再利用テキストのKVキャッシュをGPU・CPU・ローカルディスクに保存し、インスタンス間で再利用可能
- vLLMと組み合わせることで、QAやRAGなどの用途で3〜10倍の遅延削減とGPU節約が可能

@Takumi Iida (frkake)
[blog]コンテキストエンジニアリングがなぜ重要なのか
人からエージェントへ
これまでは、人が入力するプロンプトをどうするのかが大事だった。
しかし、最近ではエージェントが自律的に動作するようになっており、プロンプトだけではなく、その情報そのものをどう管理するかが大事になってきた。
複雑なプロンプトを与えたときの課題
LLMの問題解決能力を上回ってしまうと、タスクを完了できないことがある。
- 入力長の限界: LLMには入力可能な文章量に制限があるため、その中で解決できないと、それ以上何もできなくなってしまいます。
- 認識の限界: 複数の指示をLLMに任せると"Lost in the Middle"などの問題などにより解決すべき問題を見失うことがあります。
Lost in the middle = 長文コンテキストの真ん中の情報を見逃してしまうこと
コンテキストエンジニアリングでどう解決するか
LLMに適切なコンテキストを渡して、LLMの限界に到達しないようにする。
- 書き出し: 重要な情報を外部に保管して再利用可能にする
- 選択: 必要なコンテキストだけを取得して、余計な情報を持たない
- 圧縮: コンテキストを厳選して、密度の高い情報にする
- 分割: 複雑な問題を分解して、独立した扱いやすい問題にする
書き出し
書き出しによって、外部に情報を残して置くことで、セッションを再開可能にしたり、Lost in the Middleで情報が消えることを防げる。
書き出しのコツ:
- 出力の内容を指定して、情報が散漫にならないようにする
- RAGと組み合わせて、効率のよい検索と組み合わせる
- 単純にデータ量を制限して古いデータを破棄する
選択
- メモ書き、記憶の読み込み
- Toolの選択
- 情報の検索(RAGやWeb検索)
Tool選択は思っているよりも精度が出にくい部分。問題なく選択できるようになるのは、o3, gemini-2.5~, claude-3.7-sonnet~と比較的最新の、最高性能のものに絞られてくる。
圧縮
コンテキストの圧縮や切り捨て
割と情報が抜け落ちてしまうので、圧縮はできれば避けたい。圧縮なく解ききれるくらい、タスクを細かくするのが有効。
分割
LLMが解くべき問題を分割し、分割した問題を複数のエージェントが分担して解決したり、同じセッション内でも短くゴールを設定して問題を解決する方法がある。
とはいえ、可能なら処理は分割しないほうがいいらしい。
→ 分割過程でミスが発生する可能性もあるため
@Hiromu Nakamura
[論文] Zep: A Temporal Knowledge Graph Architecture for Agent Memory
Greptileが基盤として採用しているZep(動的で時間認識型のナレッジグラフエンジンであるGraphitiを搭載したメモリレイヤーサービス)に関するpaperを読んだ(ちょい古いが)。
Zepは、ベースライン実装と比較して、応答遅延を90%削減しながら、最大18.5%の精度向上という顕著な結果を達成する。セッションを跨いだ情報合成や長期的なコンテキスト維持といった、エンタープライズにとって重要なタスクにおいて特に顕著
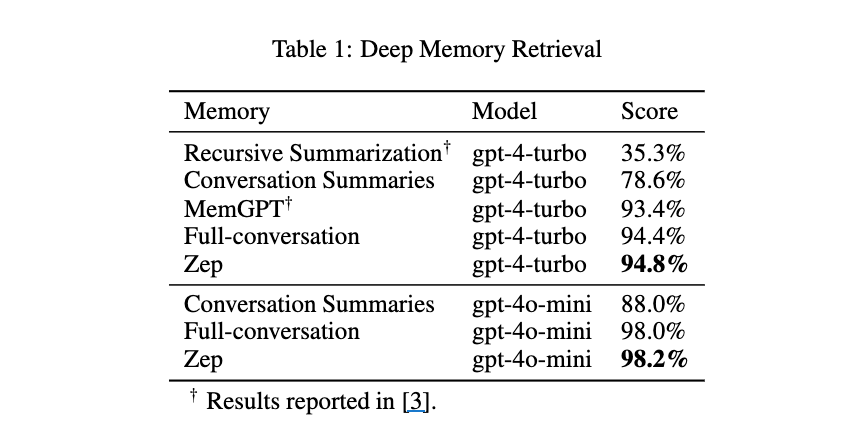
- 「MemGPT」が主要な評価指標として確立した「Deep Memory Retrieval (DMR)」ベンチマークにおいて、94.8%というMemGPTの93.4%を上回る優れた性能を示した。
- さらに、より包括的で挑戦的な「LongMemEval」ベンチマークでも、精度が最大18.5%向上し、同時に応答遅延がベースライン実装と比較して90%削減された。
提案手法zep(Graphiti)の特徴
- 各サブグラフの役割と貢献
- エピソードサブグラフ
- 役割: 生の入力データ(メッセージ、テキスト、JSONなど)を非可逆的に保存し、時間的な順序を維持する。セマンティックエンティティや関係性を抽出する際の基盤となる。
- 寄与: 正確な過去のコンテキスト提供: 過去の会話や入力内容を、そのニュアンスや具体的な表現を含めて正確に参照できる。
- 時間的な推論の基礎: 特定の時点での出来事や発言を正確に特定し、時間的な順序に基づいた推論を可能にする。
具体的なシナリオ: ユーザーが「先週の火曜日に私が言った『Xについて確認する』というメッセージの詳しい内容は何でしたか?」と質問した場合、正確なメッセージ内容と発言日時を基に、該当する会話ログを特定し、LLMに提供することで、ユーザーの正確な発言を引用・参照できる。
- セマンティックエンティティサブグラフ
- 役割: エピソードサブグラフから抽出されたエンティティ(人、物、場所、概念など)と、それらの間の関係性(ファクト)を構造化された形で表現する。
- 寄与: 構造化された知識の提供: LLMが生のテキストを解析してエンティティや関係性を特定する手間を省き、整理された形で知識を提供する。
- 複雑な事実の検索と推論: 特定のエンティティに関する複数の事実や、エンティティ間の複雑な関係性に基づいて、より高度な推論を可能にする。
- 幻覚の抑制: 抽出された事実に基づくコンテキストを提供することで、LLMが事実と異なる情報を生成する「幻覚」を抑制する。
具体的なシナリオ: ユーザーが「〇〇プロジェクトの担当者は誰で、現在の進捗状況はどうなっていますか?また、その担当者が以前関わっていた別のプロジェクトは何でしたか?」と質問した場合、「〇〇プロジェクト」というエンティティから「担当者」という関係性を辿り、「担当者」エンティティから「現在の進捗」や「過去のプロジェクト」という関係性を検索し、構造化された事実の集合をLLMに提供する。LLMはこの事実に基づいて、正確かつ詳細な回答を生成できる。
- コミュニティサブグラフ
- 役割: セマンティックエンティティのクラスター(コミュニティ)を形成し、これらのクラスターの高レベルな要約を提供する。ナレッジグラフ全体の広範な、相互接続された視点を提供する。
- 寄与: 高レベルな概念理解: 広範なトピックやドメインに関する概要をLLMに提供し、質問が具体的な事実を問うものでない場合でも、関連性の高い広範なコンテキストを構築できる。
- 検索空間の効率化: 特定のコミュニティに焦点を当てることで、ナレッジグラフ全体を検索する代わりに、関連性の高い情報グループに絞って検索できるため、情報取得の効率が向上する。
- 大規模なデータの要約とパターン認識: 個別のエンティティやファクトに深入りすることなく、全体的な傾向や頻繁に議論されるテーマを把握し、LLMがより抽象的なレベルでの要約や分析を行うことをサポートする。
具体的なシナリオ: ユーザーが「最近の会議録から、最も頻繁に議論されている顧客の課題は何ですか?」と質問した場合、会議録に関連するエンティティのクラスターを特定し、そのコミュニティの要約や関連する主要なキーワードをLLMに提供する。これにより、LLMは個々の会議の細かい内容に立ち入ることなく、全体的なトレンドや主要な課題を効率的に抽出し、要約して提示できる。
まとめると、依存関係は以下のようになります:
エピソードサブグラフ (Ge)
↓ (抽出)
セマンティックエンティティサブグラフ (Gs)
↓(クラスタリング)
コミュニティサブグラフ (Gc)
#### 検索
- コサイン類似度検索、Okapi BM25全文検索、および幅優先探索の3つの検索を採用
- Reciprocal Rank Fusion (RRF) や Maximal Marginal Relevance (MMR) などの既存のリランキングアプローチをサポートしている。
- さらに、Zepは、会話内でのエンティティまたは事実の言及頻度に基づいて結果を優先するグラフベースのエピソード言及リランカーを実装しており、頻繁に参照される情報にアクセスしやすくなるシステムを実現
#### 実験
DMR: Multi-Session Chatデータセットの500会話サブセット
LME: 平均約115,000トークンという長い会話コンテキストを提供し、より複雑な時系列推論タスクを含んでおり、エンタープライズユースケースをよりよく反映しているとされる。
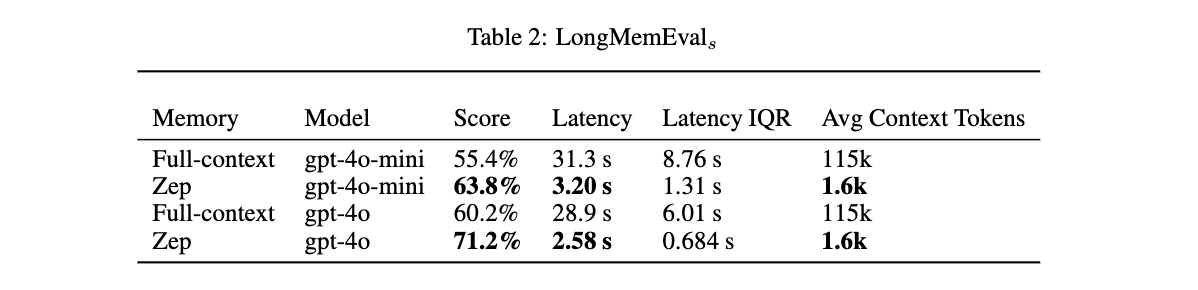
Zepが従来のRetrieval-Augmented Generation (RAG)アプローチでは扱いきれなかった動的な知識統合と長期記憶において、既存のシステムを上回る性能を持つことを、具体的な実験結果に基づいて示す出発点となっている。特に、より現実世界のシナリオに近いLongMemEvalでの優れた結果は、Zepの実用性を示唆する重要な点である。
InfiniteHiP: Extending Language Model Context Up to 3 Million Tokens on a Single GPU
- Heejun Lee, Geon Park, Jaduk Suh, Sung Ju Hwang
1. Introduction
背景と課題
- LLMの長文コンテキスト処理はマルチモーダルやRAGで重要だが、注意機構により計算・メモリコストがトークン数に対して二次的に増大
- KVキャッシュもトークン数に比例してメモリを圧迫
既存手法
コスト削減
- FlashAttention 2
- 注意スコアのメモリ書き込みを削減し、メモリと帯域の効率化
- ただし計算コストは変わらず
- 選択的注意(Xiaoら, Leeら)
- 動的 / 静的に注目トークン数を絞り、計算削減
KVキャッシュ最適化
- キャッシュ削除手法
- 不要な過去トークンを削除してメモリ節約
- HiP attention
- 頻繁にアクセスされるホットトークンはGPU、コールドトークンをホストメモリにオフロード
- HiP: Hierarchically Pruned Attention
コンテキスト拡張
- 多くのLLMは固定長のシーケンスで学習しているため、コンテキスト拡張が困難
- 長いシーケンスでのファインチューニングは高コスト & 高品質データが必要
- Out-of-Length (OOL) 汎化
- 事前訓練済みモデルを訓練なしで長いコンテキストに一般化
- Self-Extend
- 推論時にRoPE埋め込みをスケール
- 近傍のトークンに対しては通常の自己注意を用い、ウィンドウの外のトークンに対してはグループ化された自己注意を用いる
InfiniteHiPの概要
概要
- 長文コンテキストの注意コスト・KVキャッシュ・コンテキスト拡張問題を一括解決する統合フレームワーク
- 訓練不要で任意のTransformerベースのLLMに適用可能
コア技術
- 階層剪定モジュール
- 入力をチャンクに分割し、各チャンクで重要なトークンを選出、最重要なトップKチャンクのみを次段に渡す
- 最適化されたKVキャッシュ
- LRUベースのKVキャッシュ管理でHiP attentionを最適化
- RoPE調整
- 注意パターンに応じて柔軟にRoPEを調整
性能
- 300万トークンのデコードで7.24倍高速化
- VRAM使用量はFA2の3.34%
- 長文理解・推論・生成の性能を維持しながら高速化を実現
2. Related Works
- MInference
- アテンションヘッドを2つのタイプに分類し、疎なアテンションパターンを推定
- これを用いて内積の前に重要でないトークンを除去
- プリフィル段階を大幅に高速化するが、推論時間の大部分を占めるデコード段階には適用不可
- HiP Attention
- 階層的・反復的にトップKコンテキストブロックを推定
- プリフィル・デコード両方を高速化するが、グローバルスレッド同期で並列性を阻害
- Quest
- コンテキストを固定サイズページに分割し、キャッシュされた要素ごとの最小値と最大値のベクトルを利用して最大のアテンションスコアを推定
- InfLLM
- コンテキストをブロックに分割して代表トークンを選択
- 代表トークンは事前に選択されており、現在のクエリに基づいて変化しない
3. Motivations and Observations
注意機構のチャンクスパース性
- 128Kトークンコンテキストで、トップ2Kトークン(クエリに対して最も高いアテンションスコアを持つ上位2048個のキー)の12.5%以上を含むチャンクは2%未満 (左図)
- top-2Kトークンの12.5% = 256
- 256個以上のtop-2Kトークンを含むチャンク数
- 2,000チャンク × 2% = 約40個のチャンクのみ
- 64トークンチャンクの約75%はトップ2Kトークンを全く含まない (右図)
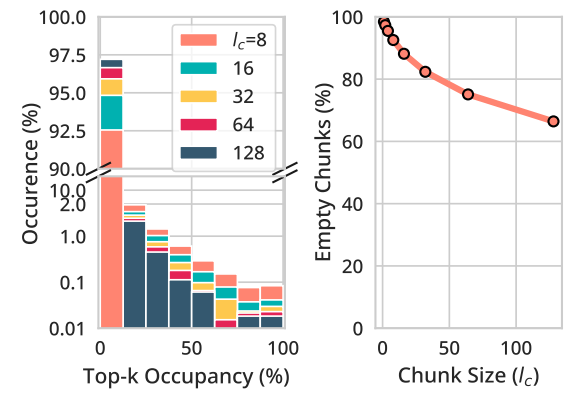
アルゴリズム設計への示唆
- 個別のトップKトークン選択の代わりに、トップKトークンを含むチャンクを選択する方が効率的
4. Designs of InfiniteHiP
Efficient Modular Context Pruning
- 複数段階の剪定
- コンテキストを固定長のチャンクに分割し代表トークンを選択
- 二分探索のようにチャンクを分割し最もアテンションスコアが高い可能性のあるトークンを選定
- チャンクスコア推定
- アテンションヘッド間でmax-poolingを行い各チャンクの最高スコアを代表値として、トップKキーチャンクを選択
- 反復処理
- 各段階で重要でないトークンを破棄し、スパースアテンションマスクを生成
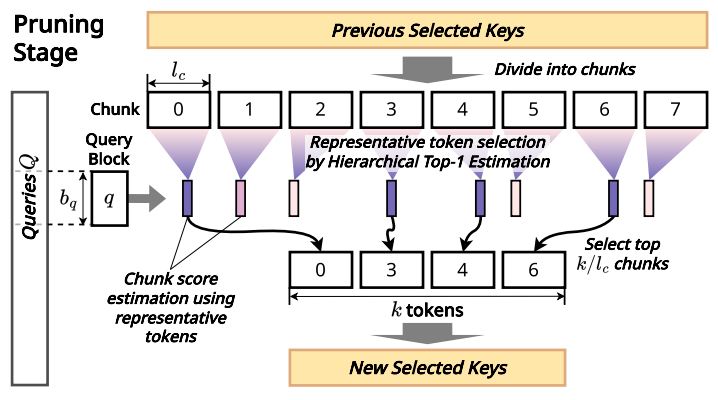
Sparse Attention Mask Caching
- スパースアテンションマスクが時間的局所性を示すことを観察
- デコードステップごとに再計算する代わりに、一定期間キャッシュを使い続けることで効率化
Dynamic RoPE for OOL generalization
- Chunk-indexed RoPE (最初の3層)
- チャンク内のすべてのキーに同じ位置IDを付与
- チャンク単位で大まかな位置関係を表現
- Relative-style RoPE (残りの層)
- 代表トークン選定の過程でチャンクが分割される際の左右ブランチに異なる位置IDを付与
- Chunk-indexed RoPEよりも細かな位置関係を表現
- StreamingLLM-style RoPE
- シンクトークン(プロンプトの最初のトークン)とストリーミングトークン(最近のトークンウィンドウ)、選択された中間のトークンを統合し、位置IDを付与
- 現在のクエリトークンを0として、それより前のトークンを負の相対位置として配置
- 動的RoPEトリックは計算オーバーヘッドを伴うため、OOL汎化能力が不要な場合は無効にする
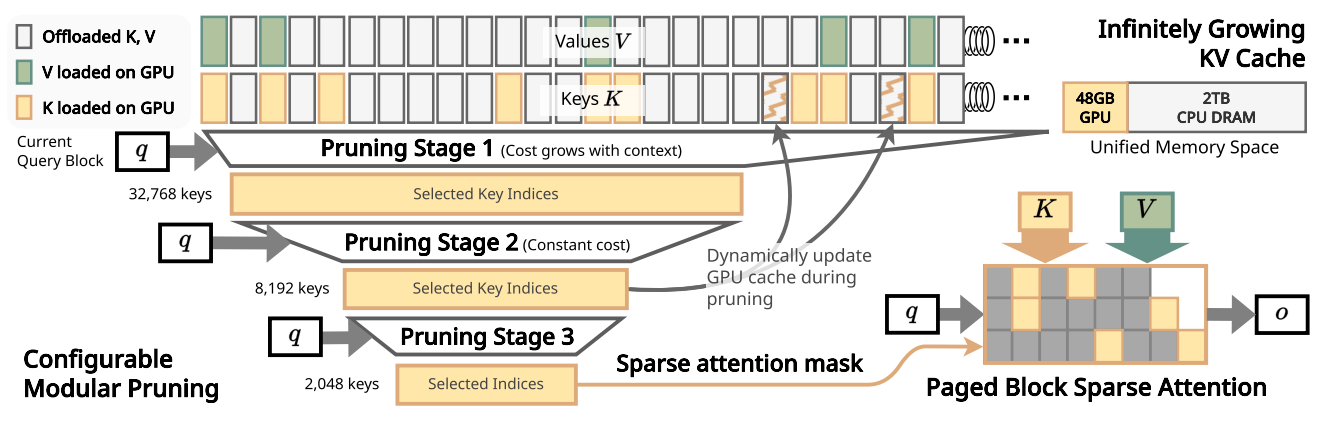
KV Cache Offloading
- NVIDIA UVM(Unified Virtual Memory)を活用し、ホットトークンをGPUで保持し、コールドトークンをCPU RAMに保持し、LRUで管理する
5. Experiments
5.1. Experiment Setting
Baselines
- 主に長文コンテキスト能力のために選ばれたベースラインと、InfiniteHiPの性能を比較
- 以下はAIに作成してもらったベースラインの手法の比較表

Benchmarks
- LongBench
- 平均32Kトークン、長文書QA・要約・マルチショット学習
- ∞Bench
- 100K+トークン、情報検索など多様なタスク
モデル
- instruction tuningされたLlama 3 8BとMistral 0.2 7Bを使用
5.2. Results
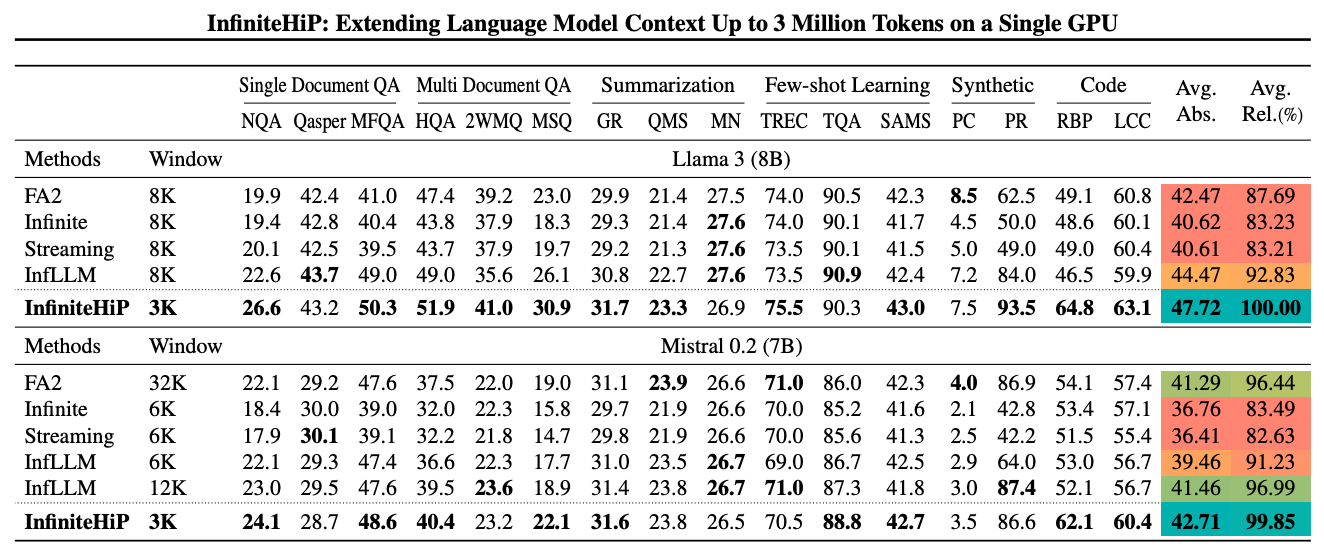
性能比較
LongBench
- ベースラインで最高性能の InfLLM と比較して、Llama 3は 7.17ポイント 向上、Mistral 0.2は 3.19ポイント 向上
∞Bench (100K+)
- 最高性能の InfLLM と比較して Llama 3 は 9.99ポイント 向上、Mistral 0.2は 4.32ポイント 向上
- (LongBenchと比較して)より長いコンテキストで性能差が拡大
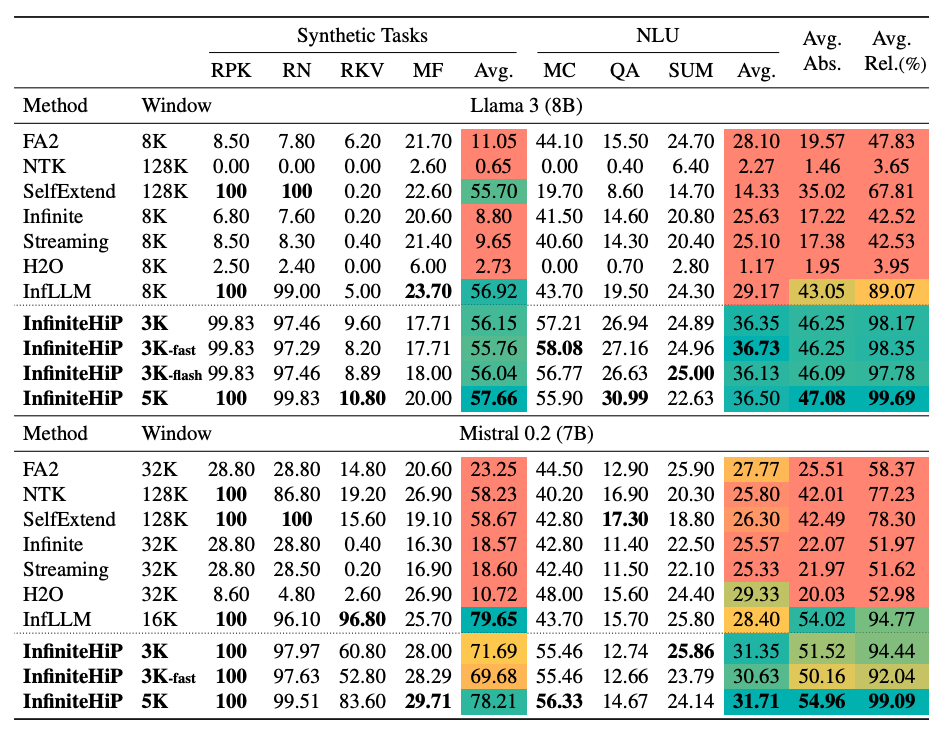
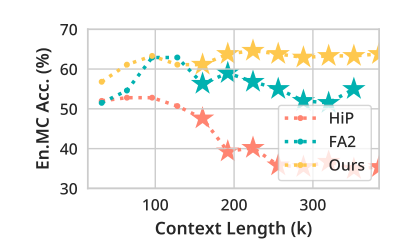
OOL汎化能力
- Llama 3.1 8Bを用いて様々なコンテキスト長における∞BenchのEn.MCスコアを比較
- InfiniteHiPはコンテキスト長が長くなるにつれて性能を向上させ続ける一方、OOL汎化能力のないベースラインは事前訓練コンテキスト長(128K)を超えると大幅に劣化
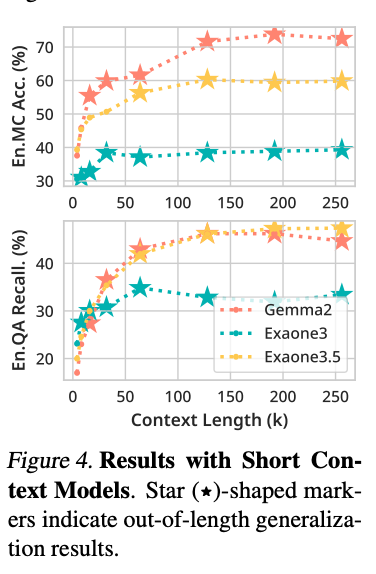
短コンテキストモデルでの拡張
- Exaone 3 (4K), Exaone 3.5 (32K), Gemma2 (8K)で実験
- Gemma2はFA2比でEn.MC 24.45%p、En.QA 22.03%p 向上
5.3. Analysis
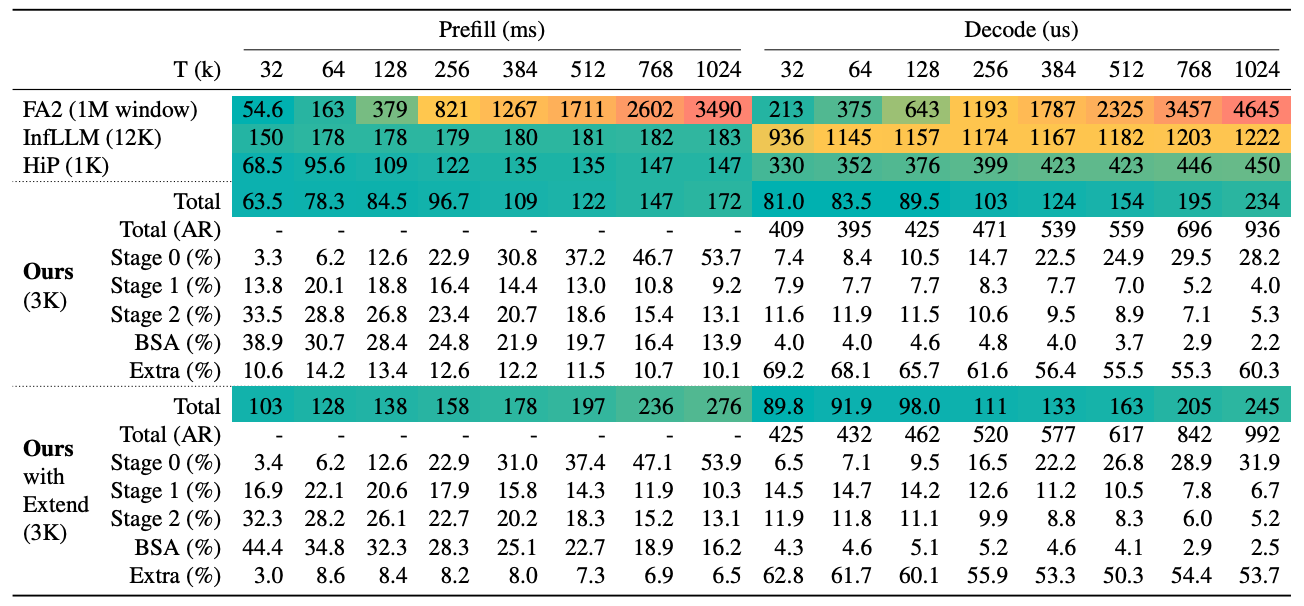
Latency
100万トークンコンテキストでレイテンシを比較
- Prefill
- FA2より20.29倍高速、InfLLMより6%高速、HiPと同等のレイテンシ
- Decode
- FA2より19.85倍、InfLLMより4.98倍、HiPを92%上回る
- コンテキスト拡張 (動的RoPE) 有効時
- プリフィル1.6倍減速、デコード5%減速
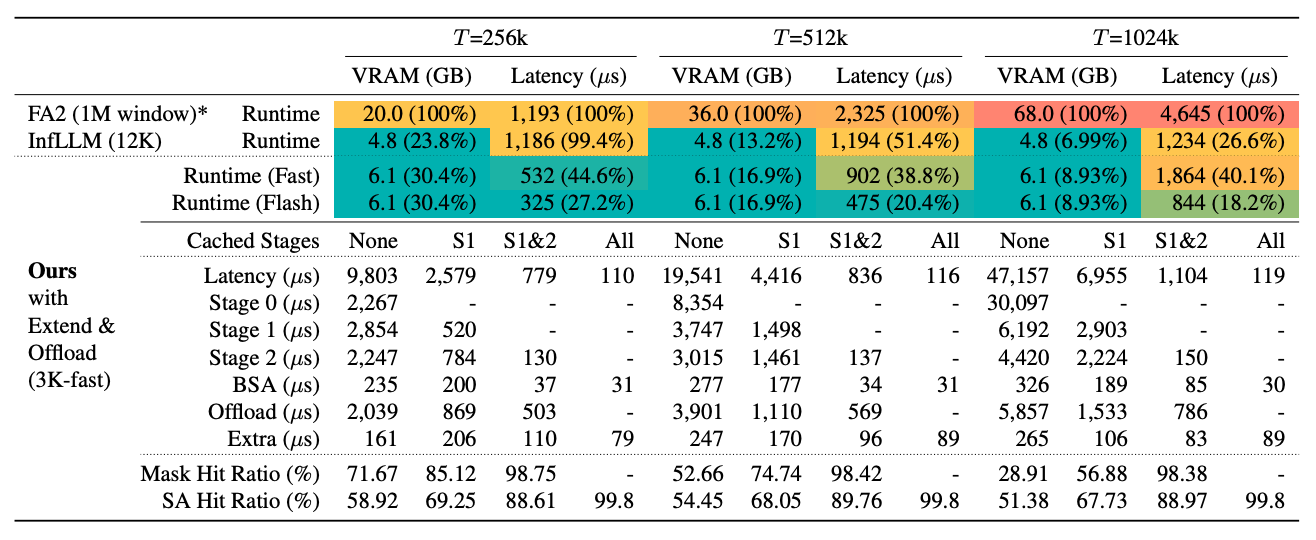
Latency with KV Offloading
- 256Kコンテキストデコードにおいて、InfLLMを3.64倍上回る
- KVキャッシュオフローディングでは、CPUメモリアクセスがVRAMアクセスよりレイテンシ面で31.5倍高価
- InfLLMは注意カーネル実行中にCPUメモリにアクセスしないため、トップK推定アルゴリズムの精度が犠牲
- 下流タスクでのモデル性能を維持するためにはより大きなブロックとコンテキストウィンドウサイズが必要
- 対照的に、我々はベースラインHiPのように注意カーネル実行中にCPUメモリにアクセスすることを選択
- これにより、アルゴリズム設計の柔軟性が向上し、下流タスクでより良い性能を発揮
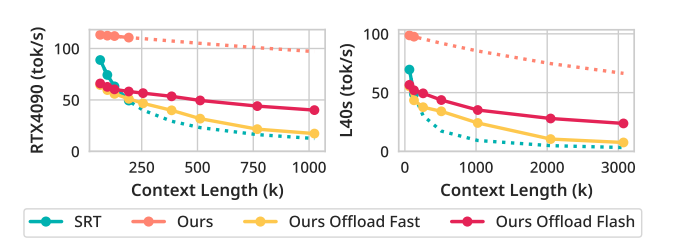
Throughput
デコードスループットの比較
- RTX 4090 (24GB)
- 1MコンテキストでSRT(SGLang Runtime with FlashInfer)の3.20倍
- L40S (48GB)
- 3MコンテキストでSRTの7.25倍
- マスク更新間隔調整
- Flash設定は、Fast設定と比較して3Mコンテキストで3.14倍改善
Accuracy of top-k estimation
- InfLLMより1.57ポイント、HiPより4.72ポイント優れたrecall