
2023-09-28 ML勉強会
“LMDX: Language Model-based Document Information Extraction and Localization”
Vincent Perot, Kai Kang, Florian Luisier, Guolong Su, Xiaoyu Sun, Ramya Sree Boppana, Zilong Wang, Jiaqi Mu, Hao Zhang, Nan Hua
Abstract
大規模言語モデル(LLM)は自然言語処理(NLP)に革命をもたらし、多くの既存タスクの最先端を改善し、新たな能力を示している。このタスクは、多くの文書処理ワークフローの中核であり、事前に定義されたターゲットスキーマが与えられたビジュアルリッチドキュメント(VRD)からキーエンティティを抽出するものである。このタスクにLLMを採用する主な障害は、高品質の抽出に不可欠なレイアウト符号化がLLMにないことと、答えが幻覚でないことを保証する接地メカニズムがないことである。本稿では、任意のLLMを文書情報抽出に適応させる手法である、言語モデルに基づく文書情報抽出とローカライゼーション(LMDX)を紹介する。LMDXは、学習データの有無に関わらず、単数、繰り返し、階層の実体を抽出することができ、また、グラウンディングを保証し、文書内の実体を局所化することができる。特に、LMDXをPaLM 2-S LLMに適用し、VRDUとCORDベンチマークで評価することで、新たな最先端技術を確立し、LMDXがいかに高品質でデータ効率の良い構文解析器を実現するかを示す。
Eng.
Large Language Models (LLM) have revolutionized Natural Language Processing (NLP), improving state-of-the-art on many existing tasks and exhibiting emergent capabilities. However, LLMs have not yet been successfully applied on semi-structured document information extraction, which is at the core of many document processing workflows and consists of extracting key entities from a visually rich document (VRD) given a predefined target schema. The main obstacles to LLM adoption in that task have been the absence of layout encoding within LLMs, critical for a high quality extraction, and the lack of a grounding mechanism ensuring the answer is not hallucinated. In this paper, we introduce Language Model-based Document Information Extraction and Localization (LMDX), a methodology to adapt arbitrary LLMs for document information extraction. LMDX can do extraction of singular, repeated, and hierarchical entities, both with and without training data, while providing grounding guarantees and localizing the entities within the document. In particular, we apply LMDX to the PaLM 2-S LLM and evaluate it on VRDU and CORD benchmarks, setting a new state-of-the-art and showing how LMDX enables the creation of high quality, data-efficient parsers.
背景
- Visual Rich Document(VRD) Understanding 分野が近年発展している。その中でも、半構造体文書(請求書、税務申告書、給与明細、領収書、etc.)から指定された項目に該当する値を抽出するdocument information extraction(IE)タスクが産業界でもアカデミアでも注目されている。
- タスクの難しさw/yuyaコメント
- 様々なテンプレートがあり情報のレイアウトも様々である中で以下のようなことが必要。
- 文書中の文章の文脈の理解
- 異なるセグメントに存在する文章を空間的な整合性をもとに理解(文章としてではなく、レイアウトとして文脈を持つようなテキストの意味の理解)
- テーブル形式で表現された情報(請求書の明細情報や給与明細の控除項目など)の理解
- [yuya]テーブルは闇
- 文書の内容は、スタンプであったり、手書きであることも。
- [yuya]会社名などがハンコやロゴで表現されていたりはよくありますね。金額も。
- 文書が回転していたり、コントラストが一定でないなども。
- [yuya]特に従業員が自分で写真撮ってアップロードする領収書とかはやばい。
- 扱う問題設定上(請求書の読み取りタスクなどは間違えることが許されない)高い精度が求められ、確認や修正のためにヒューマンインザループに組み込まれることが多く、人間が扱いやすいように、文書内のドキュメントのどこから情報を抽出したのかを示す必要がある。
- [yuya]バクラクがこだわっているところですね!
- 無限にフォーマットの種類があるがアノテーションリソースは限られており、正解データも大量に得ることが難しい。
- [yuya]アノテーションにドメイン知識が必要な場面も多く、スケールしにくい。
- その結果、求められるのは、、、
- 抽出する情報は単一なこともあれば複数であることも階層的であることもある中で、高精度であることが求められ、ドキュメント内に抽出箇所を明示し、学習データが非常に少ないかまったくない中で実現する必要がある。
- 無理ゲーぽい。
Contributions
上記の課題を解決するLanguage Model-based Document Information EXtraction and Localization(LMDX)を提案
- LLMを利用して学習データなしでも、ドキュメント内の正確な位置を示しながら、単一な情報と階層的な情報の両方に対してdocument IEタスクを実行できるプロンプトの提案
- LLMのアーキテクチャを変更することなく、ドキュメントの空間情報をLLMに伝えるレイアウトエンコーディング方法の提案
- LLMのレスポンスを文書内の抽出された実体と位置情報(bbox)にデコードし、ハルシネーションをなくすアルゴリズムを提案
- LMDXのデータ効率を複数の公開されているベンチマークで評価、特にデータ数が少ない領域において大きなSOTAを達成
提案手法
大きく5つのステージに分けられる
- OCR
- Chunking
- Prompt generation
- LLM inference
- Decoding

1. OCR
- 既存のOCRサービス(たぶんVision API)を利用して、単語と文章のセグメント(かたまり)、位置情報(bbox) を抽出する。

2. Chunking
- 文章は任意の長さを受け付ける必要があるがLLMの入力トークン長には制限があるため、文書を文書チャンクに分割する。
- エンティティがページをまたぐことは少ないと考え、まず文書をページごとに分割する。
- それぞれの文書チャンクを含むプロンプトが最大入力トークン長以下になるように、文書ページの最後から行セグメントを削除していく(文書の頭から)。
- 削除した行セグメントを新しい文書ページとしてみなして、すべての文書チャンクが入力トークンの制限をクリアするまで繰り返す。

3. Prompt generation
- Chunkingで生成されたN個の文書チャンクそれぞれに対してLLMのプロンプトを作成する。
- プロンプトは以下の情報を含み、XMLライクな構造で各コンポーネントの開始と終了を表現する。
- ドキュメント情報
- タスク説明
- 抽出対象の項目のスキーマ

ドキュメント情報
- 「<セグメント内のテキスト情報> XX|YY」という形式で、処理された座標情報をsuffixに持つテキストセグメントをすべて結合してプロンプト内で表現される。
- 座標情報:bboxの値が正規化された上で、B個のバケットに量子化され、バケットのindex番号として表現される。(ビニングということですね。)
- 様々なバリエーション
- OCR結果のワード単位のセグメントを利用するのか、行単位のセグメントを利用するのか
- 量子化(ビニング)の粒度
- セグメントごとに利用する座標の数(中央の値を使ったり[x_center, y_center], 4角の情報を使ったり[x_min, y_min, x_max, y_max])
- プロンプト長の制限を考えて以下の設定を採用
- 行単位のセグメント、2つの座標(bboxの中央座標)、B=100での量子化を選択
- 訓練データセットのすべてのデータにおいて、入力トークンが6144、出力トークンが2084に収まるように選択。
タスク説明
- 単純に以下の内容をハードコード
- “From the document, extract the text values and tags of the following entities”
抽出対象の項目のスキーマ
- JSON形式で表現
- key: 抽出したいエンティティの種類
- value: 形式(型)
- 単一なのか複数(array)なのか、階層構造なのか
- JSONはインデントしないことになっている。
- JSON形式で出力
- key: 抽出したいエンティティの種類
- value: 抽出した情報(エンティティ)
- JSONは階層的な情報をうまく表現でき、トークン効率がよく、LLMの学習データの中にもよく存在するため選ばれている。
- エンティティはプロンプトに含まれるドキュメント情報と同じ形式で表現される、つまり座標情報も含む。これにより、文書内のどこからエンティティを抽出したのかを示し、ハルシネーションを防ぐことができる。
- エンティティは複数のOCRセグメント(行セグメントや単語セグメント)をまたがることができる。
- 以下のような形で、セグメントを跨った場合でもそれぞれのセグメントの識別子(座標情報)を伴う
- こんなうまいこと出力してくれるんか
- 見つけられなかったエンティティは null or [] で表現
- チャンクごとのN個のプロンプトそれぞれに対してK回推論を行い、最終的な出力を決定する。
- さすがにこれはコスト厳しいー
- 「4. LLM inference」で説明したLLMの生の出力を、元の文書内のエンティティと位置に紐づける。
- スキーマに指定していないのに抽出された種類エンティティは破棄
- 単一の値を抽出するように指定したのに複数の値が抽出されていた場合、最も出現頻度の高いものを採用
- 座標情報をもとに元の文書中の該当するテキストセグメントを特定、抽出されたテキストが正確に元のテキストと一致しているかどうかを検証
- 抽出したエンティティに含まれるすべての単語セグメントを包含する最小のバウンディングボックスを計算し、エンティティバウンディングボックスを計算
- 同じ文書チャンク内のK個の出力からエンティティ種ごとに採用するエンティティを多数決で決定。
- N個の文書チャンク間の予測値を連結して、文書レベルの予測値を獲得
- どうやるんや?

4. LLM inference
5. Decoding
評価実験
ファインチューニング・実験設定
- LLMにはPalM2 smallを利用。
- 2段階でファインチューン
- 1段階目では様々なパターンの文書を集めた上で内部ツールでアノテーションしたものを利用。様々な文書や抽出タスク、階層構造パターンを学習させる意図。
- 2段階目では解きたいタスクに特化したファインチューン。ゼロショットの実験設定ではここはskip。
- それぞれのファインチューンに利用されるデータセットは重複しない。
- training parameters
- batch_size: 8
- dropout: 0.1
- lr: 10e-6
- CE
- inference parameters
- temp: 0.5
- Top4: 40
- K(チャンクごとの推論回数): 16
- 入力トークン: 6144
- 出力トークン: 2048

データセット・タスク
大きく2つのデータセット
- Visually Rich Document Understanding (VRDU)
- 2種類のデータセットを含む
- Registration Form
- 6つのエンティティタイプ
- Ad-buy From
- 14のエンティティタイプ、1つの階層的なエンティティを含む
- データセットの切り方に応じた複数のタスク設定
- Single Template Learning (STL)
- train/test で同じひとつのフォーマットのみ使用
- Mixed Template Learning (MTL)
- train/test で同じ複数のフォーマットを使用
- Unseen Template Learning (UTL)
- train/testで異なるフォーマットを使用
- それぞれのデータセットで4000stepファインチューン
- Micro-F1で評価
- Consolidated Receipt Dataset (CORD)
- インドネシアの店舗の領収書データセット
- 30のエンティティタイプ
- normalized Tree Edit Distance accuracy metricで評価
- train:val:test=800:100:100
- データ効率の検証のため、trainデータから10/50/100/200件サンプリングしたものでも実験
- 12000stepファインチューン
実験結果
ベースライン
- LayoutLMv3 large
- Donut
Visually Rich Document Understanding (VRDU)

- LMDXはファインチューンに利用した学習データが10件でも圧倒的に高い性能が出ている。
- LMDXは学習データが10件のときと200件のときで性能差が小さい → 学習データ効率が良い
- たとえばRFのMixedだと、LMDXは92.78 - 87.72、LayoutLMv2は89.19 - 69.44
- LMDXはゼロショットでも十分に高い性能で、学習データが小さい場合(10-100くらい)はベースラインにも勝利しているのが見られる。
- LMDXはUnseenの設定でもめちゃ強い(汎化できている)
- たとえばRFだと、LMDXはSingleに対して5pt.くらいしか性能低下していないが、LayoutLMv2は2,30pt.ほど低下
- 階層構造を持つエンティティ(Line Item)に対して
- ゼロショットでもベースラインの一番良い結果に近い性能(21.21 vs. 25.46)
- |D|=200だとLMDXが圧倒的
Consolidated Receipt Dataset (CORD)
- 同じような傾向
- LMDXは|D|=800から|D|=10で4pt.ほどしか性能低下せず。LayoutLMv3は20pt.以上低下。
Ablations
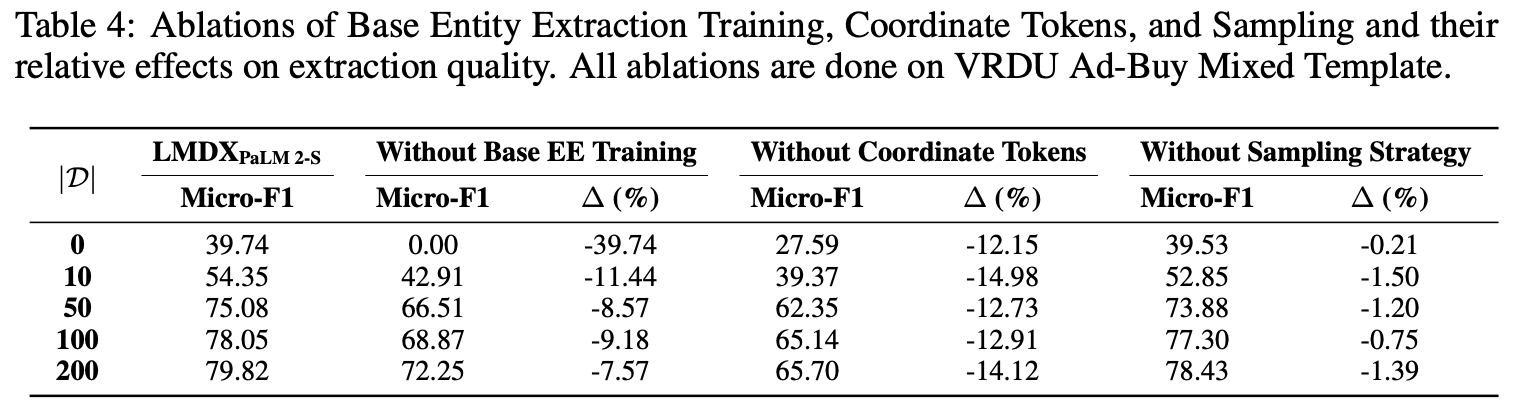
- VRUD Ad-buy Form Mixed Template Task
- 第一段階のファインチューンを行わない場合
- zero/few-shotでは出力形式が安定せず大きく性能低下(そりゃそう)
- でも200件で二段階目のファインチューン行えば70%overは十分に強い。
- 座標トークンを、その行のインデックスに置き換えると(テキストセグメントの識別子としては機能するが、位置情報はかなり失われる)全体的に10pt.以上性能悪化
- チャンクごとに複数回の推論を行いサンプリングをやめても、そこまで性能落ちず(コストに対して得られる性能改善が小さいのでやる意味小さそう)
エラー分析
- 意味が異なる複数のセグメントをひとつのセグメントに含めてしまうことで起こることが多い(わかる〜)
- 左はいらんテキストまで出力に含めてしまっており、右は同じ行に複数のエンティティタイプがある(Invoice Period, Flight Dates)際にどっちがどっちかわからなくなっている。
感想
- 準構造化文書からの情報抽出タスクについての難しさなどが整理されている点でも有益だと感じた。
- アルゴリズムやプロンプト、実験設定などがちゃんと詳細に公開されていて誠実な論文だと感じた。
- 最終的な(2段階目)ファインチューンで利用するデータセットサイズが大きくて200は小さすぎる?データセット大きくしたら普通にLayoutLM系が強かったりするのかしら。画像とかうまく使える分、そうなる気がする。
- とはいえ、実運用ではそんなにデータセット集められないケースも多いので少ないデータセットで高い性能が出るのはありがたい。
- 最初の(1段階目)ファインチューンで利用するデータセットを準備するの、いち企業では無理ゲーだなと思っていたが、2段階目だけでもそこそこ性能出そうなのは希望の光
- エラー分析、わかる〜って気持ちが強すぎた。