MLOps年末反省会: Triton Inference Server を深層学習モデル推論基盤として導入したので振り返る
背景
立ち上げからしばらくは、Python言語のウェブサーバーフレームワークであるFastAPIで実装した推論サーバーを利用していました。 内部ではPyTorchなどの深層学習フレームワークを用いて推論実行を行うという簡単なつくりです。
(これは完全に良いことなのですが)事業がスケールし始めメンバーが増えて色々な機能や手法の応用を考え出すフェーズになったとき、推論サーバーに対するワークロードが急に厳しくなってきました。 モデル数やそのスケール(パラメータ数)とリクエスト数が当初より急に大きくなりました。特に当時検証中であった「とある新機能」により、広告デザイナーがインタラクティブに利用中にもバッチ予測寄りの性質の大量の推論リクエストが発生することになったことが主因です。
いちばんの問題は処理時間のばらつきでした。 この対応中、ネットワーク周りも含めた全体の推論実行時間の分布を見て評価をしていたのですが、試行錯誤してもレスポンスが返ってくるまでの時間のばらつきは大きく、広告LP制作ツールのUXにとっても、また大規模バッチ処理の安定性にとってもなかなか厳しい状況でした。
評価
このプロットは推論実行速度(実環境のネットワークレイテンシー等を含む)の分布です
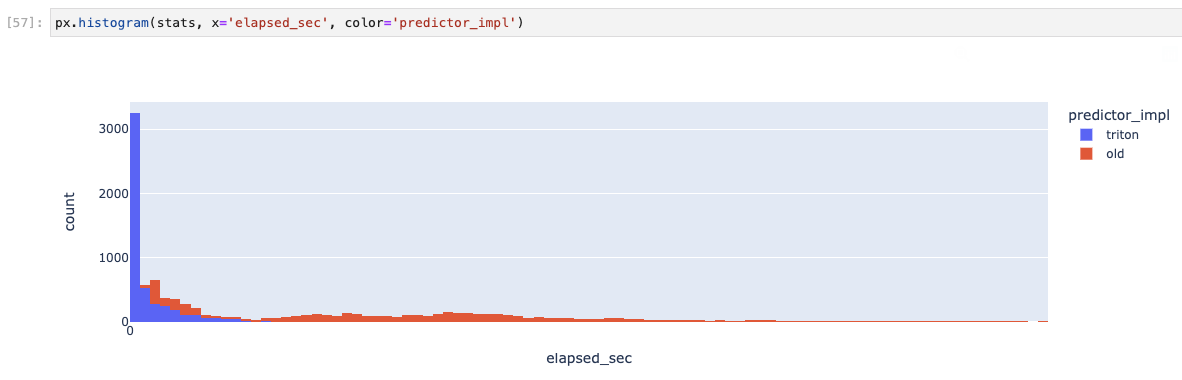
良かったこと
- 当時のパフォーマンスまわりの悩みが解決した。
- 現在はさらに要件が厳しくなったものの、スケールアップ・スケールアウトがしやすい基盤となったため、対応がしやすくなった。
- 研究開発寄りのメンバーと実運用化寄りのメンバーとで、やることの境界が明確になった。
- たとえばリサーチエンジニアはTorchScriptやONNX形式に正しく出力するところまで、MLエンジニアは前処理・後処理含めたモジュール化とモデル本体のTritonへのデプロイ、という感じになる。
- 最近活発に利用されているHugging Face Hub のように、可搬性とデプロイ容易性がある程度保たれた形式に変換できるようなモデルにしておくと、研究側・開発側ともにうれしい。
- 前処理や後処理をモジュール化して推論サーバー側に持たせることができたため、バックエンドサーバーではドメインモデルだけを考えれば済むようになった。
- 推論APIやペイロードのデータ構造に悩む必要がなくなった。
- GunicornやUvicornのパフォーマンスチューニングに悩まなくて良くなった。
- GPU利用時のボイラープレート的なコードがなくても安全に複数モデル間でGPUを共有できるようになった。
- 複数の深層学習フレームワークを共存させるコンテナイメージのビルドで苦労することがなくなった。
- 複数のモデルを安全に動かせるようになった。
- デプロイ環境のバージョンと依存関係の仕様が安定するようになった。
- gRPCにより通信の効率が良くなった(たぶん)。
- gRPC, 特にコード生成まわりのことがちょっとわかって楽しかった。