
2024-04-18 機械学習勉強会
今週のTOPIC[slide] Evolutionary Optimization ofModel Merging Recipes (2024/04/17, NLPコロキウム)[slide] タイミーにおける H3を活用したレコメンドの改善事例[blog] LightGBMをGPUで回すと結果の再現性が得られない[blog]LLMを活用した大規模商品カテゴリ分類への取り組み[論文]An Empirical Study of Uncertainty in Polygon Annotation and the Impact of Quality Assurance[GitHub repo] ‣[slide] 生成AIによるプロダクトと生産性向上の舞台裏NVIDIA Triton Inference Server 概要アーキテクチャモデルリポジトリモデル構成モデルのバージョン管理動的バッチ処理モデルの同時実行モデルアンサンブルを使用した複数のモデルの実行アンサンブルモデル構成処理概要
今週のTOPIC
※ [論文] [blog] など何に関するTOPICなのかパッと見で分かるようにしましょう。
出典を埋め込みURLにしましょう。
Naoto Shimakoshi
[slide] Evolutionary Optimization ofModel Merging Recipes (2024/04/17, NLPコロキウム)
- 秋葉さんのモデルマージについての話
- 元々のアプローチとして重みレベルのモデルマージとレイヤーレベルのモデルマージがあった
- 目的としては、アンサンブル的な理由か、VLMのような複数能力を統合したいというお気持ち
- なぜ上手くいくのかという話の論文も紹介
- 日本語のLLMは英語LLMからの継続事前学習で、継続事前学習だとモデルマージが難しいという議論がある。手動で探索するの難しいから自動でやろうというのが、進化的モデルマージのモチベーション
- 結果的に や という複数の能力を統合したものが作れた
- モデルマージ時にtest scoreを使って最適化すると簡単に過適合するため、Open LLM Leaderboardのモデルマージ勢はちょっと信用できないかも?的な話も。
[slide] タイミーにおける H3を活用したレコメンドの改善事例
- こういう位置情報系だと単純に自宅からの距離とかを特徴量にしがち
- それだと異なる生活圏を持つ人の特徴を考慮できない
- この人はこのH3でどれくらい応募したことがあるんだろう的な特徴を作ることで大きく改善
- この考え方がどこでも使える話だと思っていて、「ある程度連続的なものをカテゴライズすることで特徴としてaggregationしやすくする」みたいな発想はとても重要
Yuya Matsumura
Yuta Kamikawa
[blog]LLMを活用した大規模商品カテゴリ分類への取り組み
- 2024年の商品カテゴリのリニューアルに伴い、30億以上の商品に新カテゴリを付け直す必要があった
- タスクとしては分類タスクになるが、旧カテゴリから新カテゴリへマッピングが複雑で、ルールベースでカテゴリを付け直すことが難しく、LLMを使って商品に新カテゴリをつけることになった
- 30億以上の全ての商品にLLMを使うのはコスト的に難しいので、一部商品だけLLMでカテゴリをつけて、それを正解としてkNNで分類タスクを解いた
- kNNでは商品のembeddingを使う必要があるが、OpenAI Embeddings API ()みたいなコストがかかるモデルでなく、OSSのモデルでも同等の精度だった
- Spotifyのvoyagerというvector databaseを使って、cpuで高速なベクトル検索を行うことで、30億以上の商品のカテゴリの予測を行った
Shun Ito
[論文]An Empirical Study of Uncertainty in Polygon Annotation and the Impact of Quality Assurance
- HCOMP2024 WORKS-IN-PROGRESS(short paper)
- ポリゴンアノテーションの品質に関する研究
- 例: 車の影に隠れているタイヤ周辺のアノテーションはアノテーターによるバラツキが大きい

- アノテーションに対するQAレビューが品質にどう影響するか実験
- QAレビュー: 専門家がアノテーションに関して指摘を入れる
- 最初のアノテーション > QAレビュー → 再度アノテーション で品質がどう変わるかを実験する
- 実験結果: QAレビューによってアノテーションのバラツキが抑えられている(縦軸は誤差のような指標)

- 一方で、曲線部分や影になっている部分の精度は改善幅が小さく、QAレビューのコスパ悪そう

- 感想
- 得られた結果は直感的にも納得感のある内容だった
- 書類のアノテーションだと
- bboxは矩形なので、ポリゴンよりはバラツキが少ないはず
- 文字 (paragraph) が密集してる場所のアノテーションはQAレビュー的に改善できるかも?
- アノテーションミスの発生しやすい帳票がわかると面白そう(雑)
Ryosuke Fukazawa / qluto
[GitHub repo] ‣
特定のトピックについて関連リポジトリや論文などをまとめた awesome-list を作る風習がありますが、文書理解に関するタグがついているものの中でもいいなと思ったのがこれ。
スター数などで言えば ‣ が一番になっていそうですが、こちらは網羅性の高いリンク集という形でまとめられてます。
データセットをいかにして整えていくかというのを考える際に、今一度世の中のデータセットがどのタスクのためにどのように整備されているかを洗い直してみるのも有用そう。

ドキュメント内で階層構造化された意味をアノテートしているデータセットも存在しており、あらかじめ決まった項目抽出を行うだけの読み取りを超え、レイアウトによる項目間の意味上の繋がりを高度に理解するのを目指すのなら重要性は上がりそう
Yosuke Yoshida




NVIDIA Triton Inference Server 概要
tutorials
triton-inference-server • Updated May 4, 2025
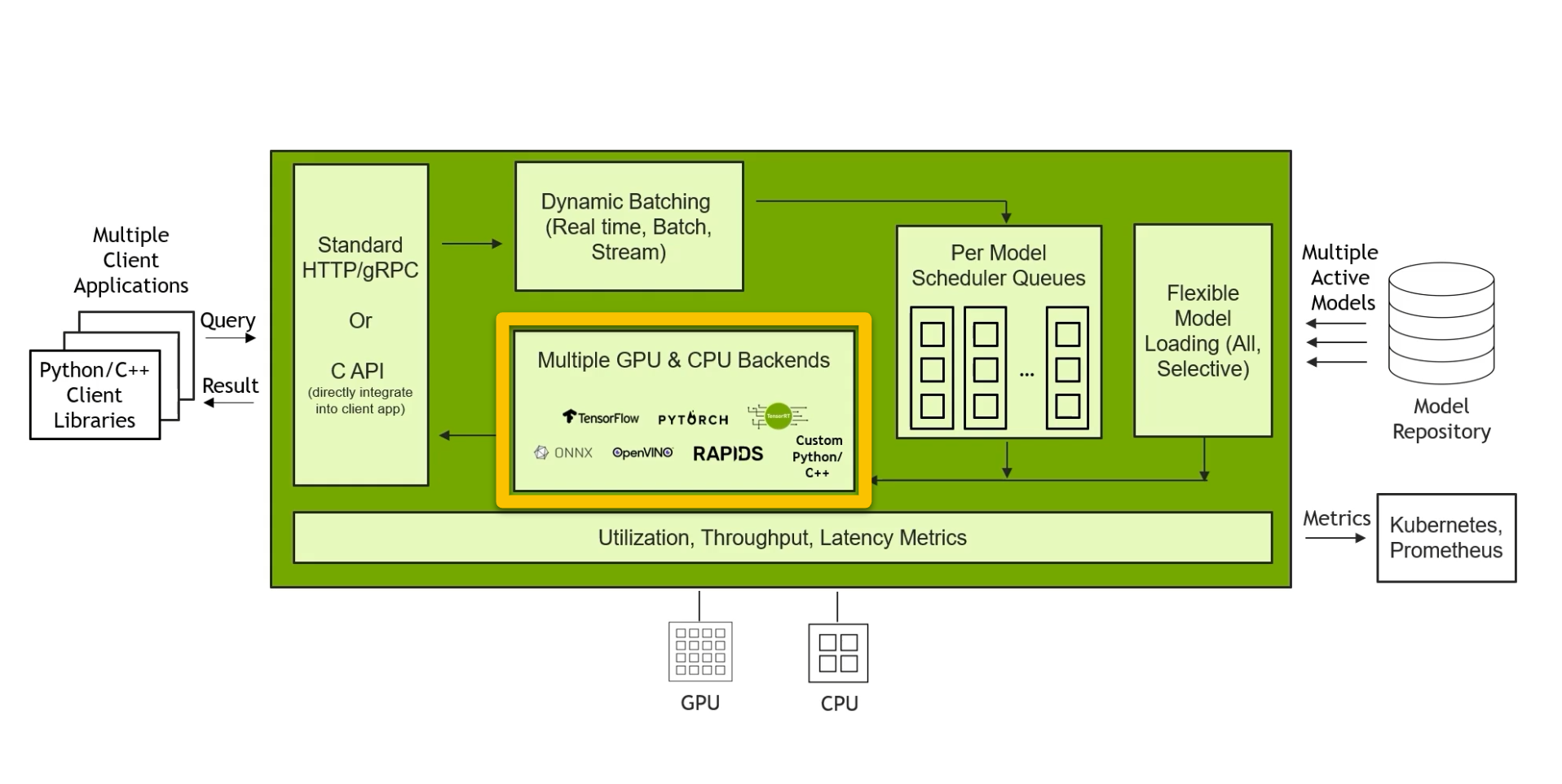
アーキテクチャ
- 推論リクエストはHTTP/REST, gRPC, またはC APIでサーバーに到達し、Tritonのハンドラはそれを要求されたモデルのキューに入れます。
- モデルインスタンスの1つが解放されると、優先バッチサイズに対応するサイズの動的バッチが、クエリ、他の受信クエリ、または既にキューにあるクエリを使用して形成されます。
- このバッチはフレームワークが必要とする形式に変換され、フレームワークのランタイム(PyTorch、TensorFlow、TensorRTなど)に送られます。
- 推論後、これらの結果はクライアントに返されます。
モデルリポジトリ
- モデルリポジトリは、モデルと各モデルに関連するメタデータが含まれ、Tritonサーバの起動時に読み込まれます。
- これらのモデルリポジトリは、ローカルまたはネットワークに接続されたファイルシステム、またはAWS S3、Azure Blob Storage、Google Cloud Storageのようなクラウドオブジェクトストアに置くことができます。
- 例としてtext_detection, text_recognitionと2つのモデルがある場合のモデルリポジトリのディレクトリ階層は以下のようになります
- 各モデルに対して、ユーザーはモデル構成を定義することができます (config.pbtxt)
- 各モデルのディレクトリ配下には、モデルのバージョンを表す数値のサブディレクトリがあり、同じモデルの複数のバージョンを扱うことができます
モデル構成
- 以下はconfig.pbtxtの例です
- name
- 任意のフィールドでモデルのディレクトリ名と一致しなければならない
- backend
- モデルの実行にどのバックエンドが使用されているかを示します。
- max_batch_size
- モデルがサポートできる最大バッチサイズ
- input / output
- 入出力の名前、データ型、形状
モデルのバージョン管理
- version policy
- All
- モデルリポジトリで利用可能なすべてのバージョンのモデルが推論に利用可能です
- Latest
- リポジトリにあるモデルの最新nバージョンのみが推論に利用できます。モデルの最新バージョンは、数値的に最も大きいバージョン番号となります
- Specific
- 具体的に列挙されたバージョンのモデルのみが推論に利用できる
- version_policy が指定されていない場合は、Latest(n=1) がデフォルトとして使用され、モデルの最新バージョンのみが Triton によって使用可能になります
以下の構成は、モデルのすべてのバージョンがサーバーから利用可能になることを指定します。
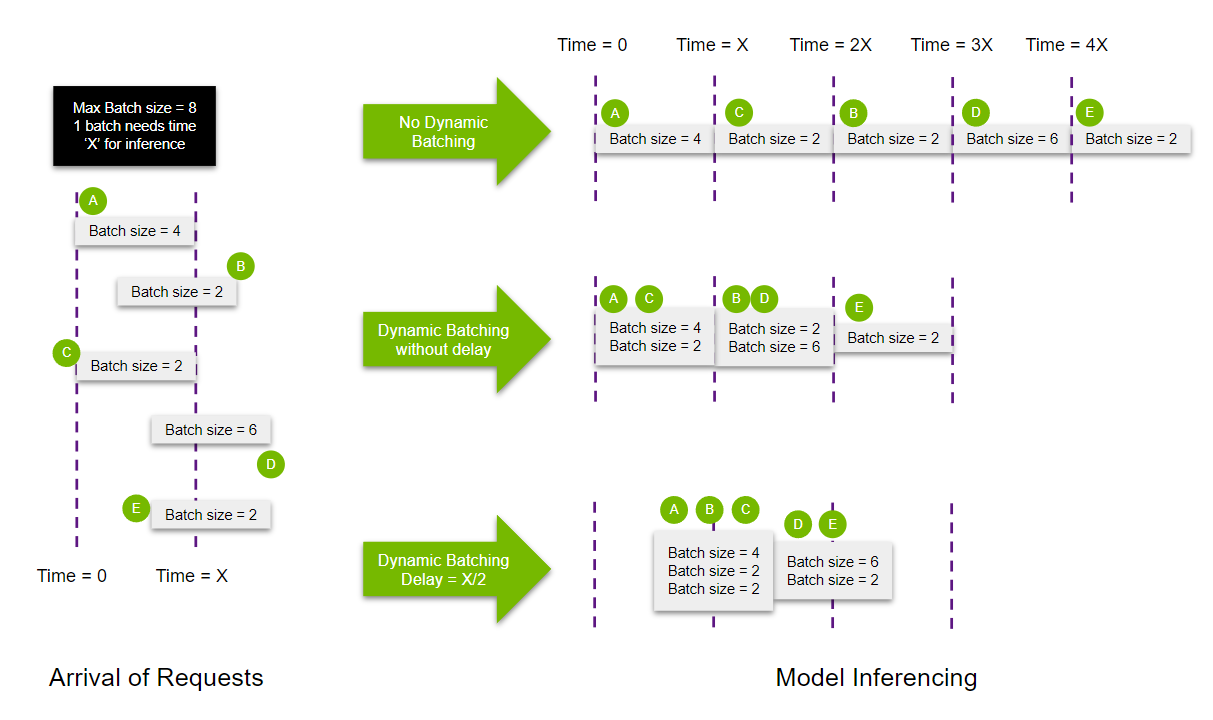
動的バッチ処理
- Triton Inference Serverにおける動的バッチ処理とは、スループットを最大化するために、1つ以上の推論要求を1つのバッチにまとめる機能を指します。
- 動的バッチ処理は、config.pbtxtに下記の記述をすることでモデル単位で有効にすることができます
- Tritonは、これらの受信リクエストを遅延なしでバッチ処理するが、ユーザーは、動的バッチ処理で使用される推論リクエストをより多く収集するために、スケジューラに制限された遅延を割り当てることができます
- 以下の例では動的バッチ処理を使用しない場合、すべてのリクエストを処理するのに5Xms要するが、動的バッチ処理を使用すると3Xmsになります
- (実際はバッチサイズが増えるとレイテンシも増えるのでこんなに単純ではないですね)
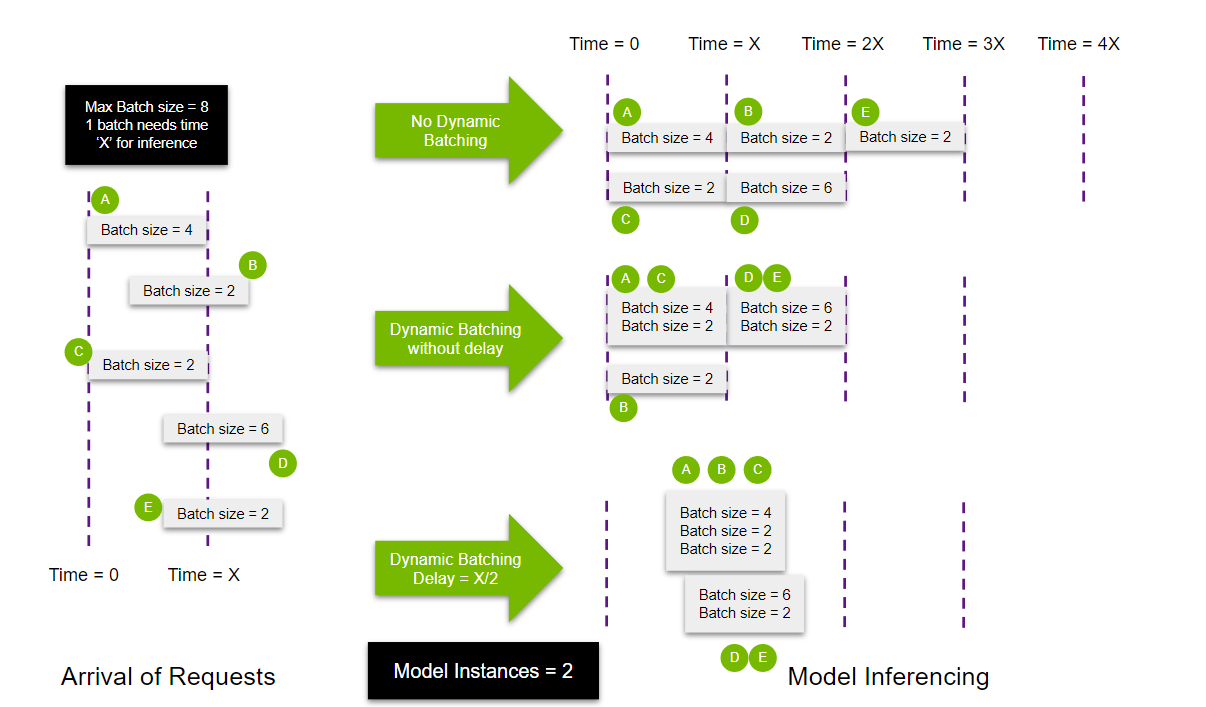
モデルの同時実行
- Triton Inference Serverは、同じモデルの複数のインスタンスを起動し、リクエストを並列処理することができます。
- Tritonは、ユーザーの仕様に応じて、同じデバイス(GPU)、または同じノード上の異なるデバイス上にインスタンスを生成することができます。
- 前の例と同様に並列実行用に複数のモデルを追加した場合、この例では、1 つのモデルで 5 つのクエリを処理する代わりに、2 つのモデルが生成されます。
モデルアンサンブルを使用した複数のモデルの実行
- 推論処理では前処理や後処理、複数モデルの予測値の集約、異なるモデルの異なるタスクの実行など、複数のモデルの実行を伴うケースがあります
- TritonではModel Ensembleを用いることで1回のリクエストで複数のモデルをサーバーサイドでパイプライン実行することができます
- 前処理や後処理をPython backendで記述することは一見便利そうだが、TritonのデフォルトのPythonのバージョンが3.8に固定されているようで、それ以上のバージョンのPythonの場合は独自にビルドする必要がある模様

アンサンブルモデル構成
処理概要
- detection_preprocessing
- python
- 画像のリサイズと切り取り
- text_detection
- onnx
- 文字検出
- detection_postprocessing
- python
- 文字領域の切り取り
- text_recognition
- onnx
- 文字認識
- recognition_postprocessing
- python
- 文字をデコード