
2024-08-29 機械学習勉強会
今週のTOPIC[blog] AutoMLOpsを使って機械学習CI/CDパイプラインを組んでみた[blog] 10X の推薦を作るチームと ML platform[サービス] Midship: Extract document data straight into your spreadsheets[library] Cleanlab[論文] Can we trust bounding box annotations for object detection?[論文] DocLLM: A Layout-Aware Generative Language Model for Multimodal Document Understanding[論文] Inversion-Free Image Editing with Natural LanguageメインTOPIC: VerifiNER: Verification-augmented NER via Knowledge-grounded Reasoning with Large Language Models (ACL 2024)概要問題とする対象の特性分析提案手法ExperimentsRQ
今週のTOPIC
@Naoto Shimakoshi
[blog] AutoMLOpsを使って機械学習CI/CDパイプラインを組んでみた

- automlopsというGoogleのOSSがあり、それを使って機械学習のCI/CDを組んでみたという話。
- 基本的にと を使ってpipelineを記述するKFPっぽい使い方
- 上記で定義したpipeineを実際にデプロイを行う。デプロイの種類としては以下
- :各コンポーネントごとに設定や構成情報が記述された YAML ファイルや GCP の各サービスを展開するために必要な CLI コマンドが記述されたスクリプトを自動作成してくれる
- :自動作成されたスクリプトをもとに、Artifact Registory の作成やサービスアカウントの設定等を実施。
- :ビルドや docker image の push を行い、実際にパイプライン処理をデプロイするために使用。
- :エンドポイントにデプロイされたモデルに対して、monitoring job を実行する際に使用。
- :, , の3つの関数を一気に実行。
- :インフラを削除するために使用。 を使ってる場合は使用できる。
- blogとしては基本的にtutorialに従ってやってみたという話。BQ → 決定木で他クラス分類 → 推論エンドポイントを立てるという流れ
- [shima] がpackages_to_installしか使えないっぽくて辛そう。コンテナ実行したい。
- [shima] 自動で結構な数のものがdeployされてしまうので、ちょっと怖みがある?サンプルコードだとシェルスクリプトでdeployしてるが、terraformも対応してるっぽいので、それだったら安心かも?
@Yuya Matsumura
[blog] 10X の推薦を作るチームと ML platform
- 10Xさんが2024年4月からいま(2024年8月)までの5ヶ月間で6つの推薦機能をリリースできた裏側の紹介
- ML開発を支えるML platformとそれを活かすことのできるチームによるもの。
- お客さま体験チーム
- ML と検索で合わせて2人、アプリエンジニア 1人、デザイナー 1人、PM(プロダクトマネージャ)1人、QA(品質保証)1人の合計6人チームで、ものを出すのに十分かつ最小構成のチーム
- ML platform
- ‣
- ML 機能開発では定性評価が重要だと信じて、シュッとデプロイできる社内環境で推薦結果のデモを見れるようにしている。
- 社内に(CEO をはじめとする)ヘビーユーザからライトユーザまでいる環境は ML 機能開発にとってかなり便利です。
- 定性評価には落とし穴があります。それは、悪い推薦がひとつでも見つかったときに直したくなってしまうことです。
- 「デモは改善のためのものであり、ダメなところを洗い出すのが目的ではありません」だとか「厳密な評価は本番での定量評価を実施するため、デモ時点ではゆるめにリリース判断を実施しましょう」などの共通認識をチームで持つことが有効です。
- 現状は基本dailyでバッチ推論してデータストアに突っ込んでプロダクトから読み込む形
- また、ネットスーパー、ネットドラッグストアではひとりのお客さまが高々一日一回しか購入しない点も特殊です。この性質のおかげで、トレーニング、推論は高々一日一回だけでよいことが多いです。
- KPI
- ネットスーパー、ネットドラッグストアでは、少量の買い物をたくさんの人がしてくれるよりも、大量の買い物を少人数がしてくれる方が利益が出やすい構造になっているため、カート内商品点数の増加は重要です
- 検索技術と推薦技術は互いにもとの境界を超えており、それにともない技術者たちも両方の知識を得る必要があるわけです。
@Tomoaki Kitaoka
[サービス] Midship: Extract document data straight into your spreadsheets
- YCombinator W24
- Midshipは、複雑なドキュメントから情報を抽出し、それを数分でスプレッドシート・JSONなど好みな形式として出力することで、手作業によるデータ入力を大幅に削減する
- Custom-Trained Recognitionによって顧客の特定のドキュメントレイアウトを訓練することができるらしい


- demo動画
- 明細データをスプレッドシートに書き起こしてくれる
- 元データのテーブルとスプレッドシートのヘッダーは完全一致してないが、自動で対応するカラム判定をしてくれる
- 処理には30分くらいかかると言っている?数分って言ってなかったけ?
@Yuta Kamikawa
[library] Cleanlab
- データの品質を改善するためのライブラリ
- confident learningを用いて、データセット内の誤ったラベルを自動的に見つけて、修正することができる

- 対応しているタスク一覧
- 二値分類(バイナリ分類)
- 多クラス分類(複数のクラスへの分類)
- マルチラベル分類(例: 画像や文書のタグ付け)
- トークン分類(例: テキスト内のエンティティ認識)
- 回帰(データセットの数値カラムの予測)
- 画像セグメンテーション(ピクセルごとにアノテーションされた画像)
- 物体検出(バウンディングボックスでアノテーションされた画像)
- 複数のアノテーターによるデータラベル付きの分類
- 複数のアノテーターを使ったアクティブラーニング(モデルの性能を最も向上させるために、どのデータをラベル付けまたは再ラベル付けするかを提案)
- 異常検知(外れ値の検出: 分布外の異常なデータの特定)
- Cleanlab関連のブログ
- ‣
- ‣
@Shun Ito
[論文] Can we trust bounding box annotations for object detection?
- CVPR2022
- bboxアノテーションのズレを調査した論文
- 調査方法: アノテーションされたbbox (AHBB) と、segmentationから生成されたbbox (SHBB) を比較する

- ズレの傾向
- AHBB vs. SHBB のIoUを計算: 小さい物体ほどズレが顕著になる
- 斜めの物体でもズレが大きくなる


- 学習するラベルに実際の物体とのズレがあると、精度検証の正しさに影響する。
- 物体の大きさや複雑さを考慮した評価
- 1つの画像に対して複数のアノテータによるラベル付け
@qluto (Ryosuke Fukazawa)
[論文] DocLLM: A Layout-Aware Generative Language Model for Multimodal Document Understanding
pre-print は1月ごろに出ていましたが、ACL 2024 で正式発表されたもの
以前紹介されたLayoutLLMと近しいモチベーションで、BoundingBoxとTextとでDocument Understandingを行おうというもの。
- 提案手法概要
- DocLLMは従来のLLMを拡張し、テキストの意味だけでなく文書のレイアウト情報も考慮できるようにしたモデルです。
- 画像エンコーダーを使用せず、OCRで抽出したテキストの境界ボックス情報のみを利用してレイアウト構造を捉えます。
- テキストと空間情報のモダリティを別々に扱う「disentangled spatial attention」メカニズムを導入しています。
- 事前学習では、文書の一部を穴埋めする「block infilling」タスクを採用し、不規則なレイアウトや異種コンテンツへの対応力を高めています。


- 評価
- 様々なドキュメント理解タスク(VQA、KIE、NLI、分類)に対応したインストラクションチューニングデータセットを作成・使用しています。
- 評価実験では、多くのタスクと公開データセットでSoTA(State-of-the-Art)モデルを上回る性能を示しました。
- 特に、Key Information Extraction(KIE)や文書分類タスクで高い性能を発揮しています。
- 視覚的な要素を必要とするタスクでは、画像エンコーダーを持つモデルには及ばない面もありますが、全体的に競争力のある性能を示しています。

- モデルサイズは1Bパラメータと7Bパラメータの2種類を検証しており、小さいモデルでも高い性能を示しています。
@Masamune Ishihara
[論文] Inversion-Free Image Editing with Natural Language
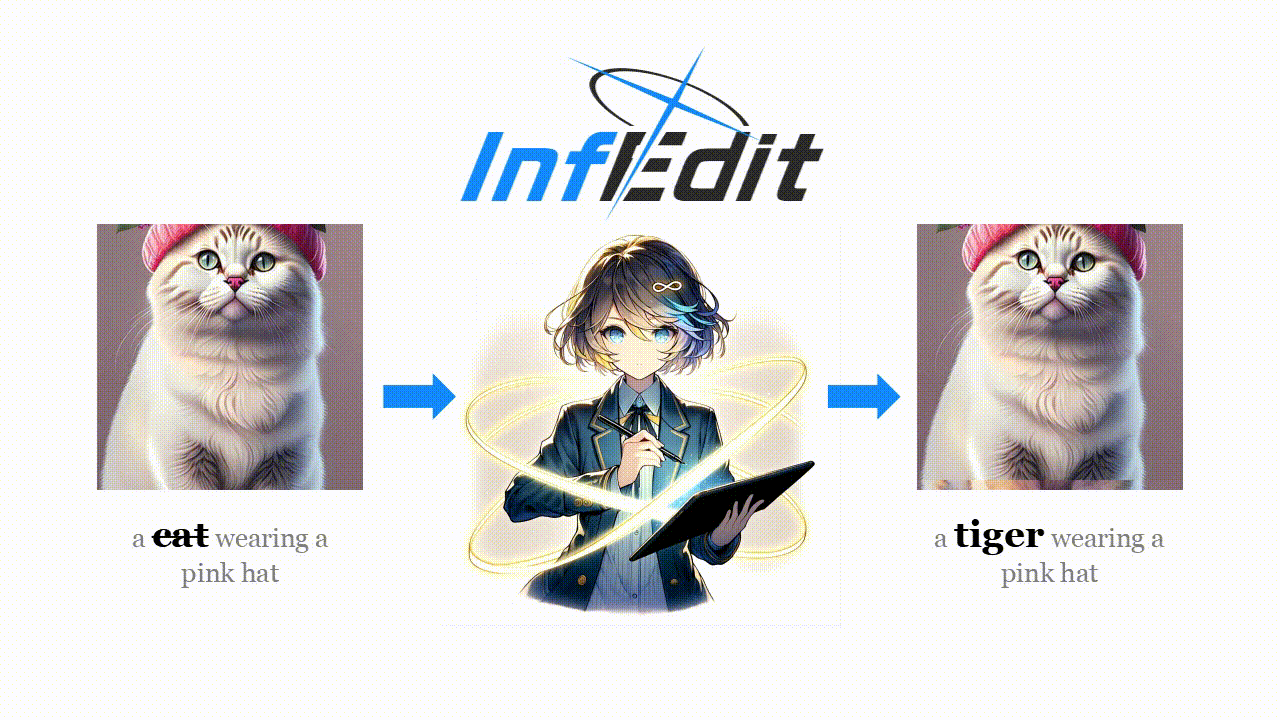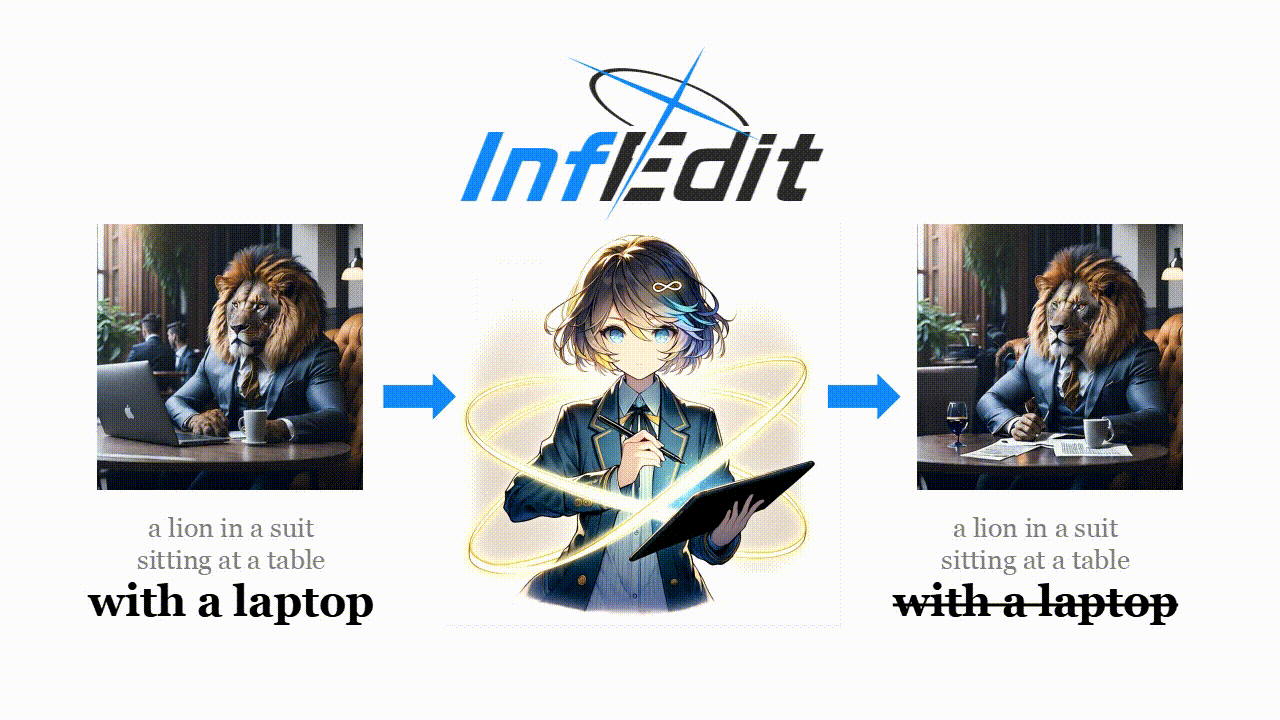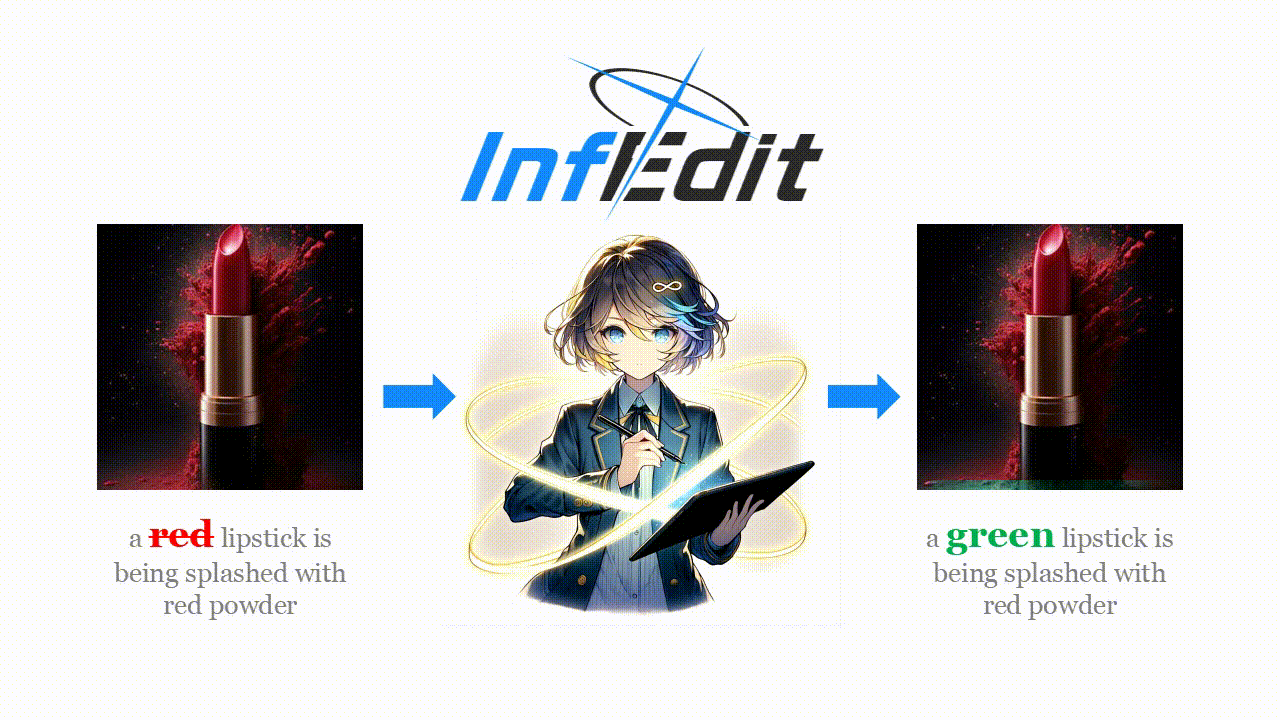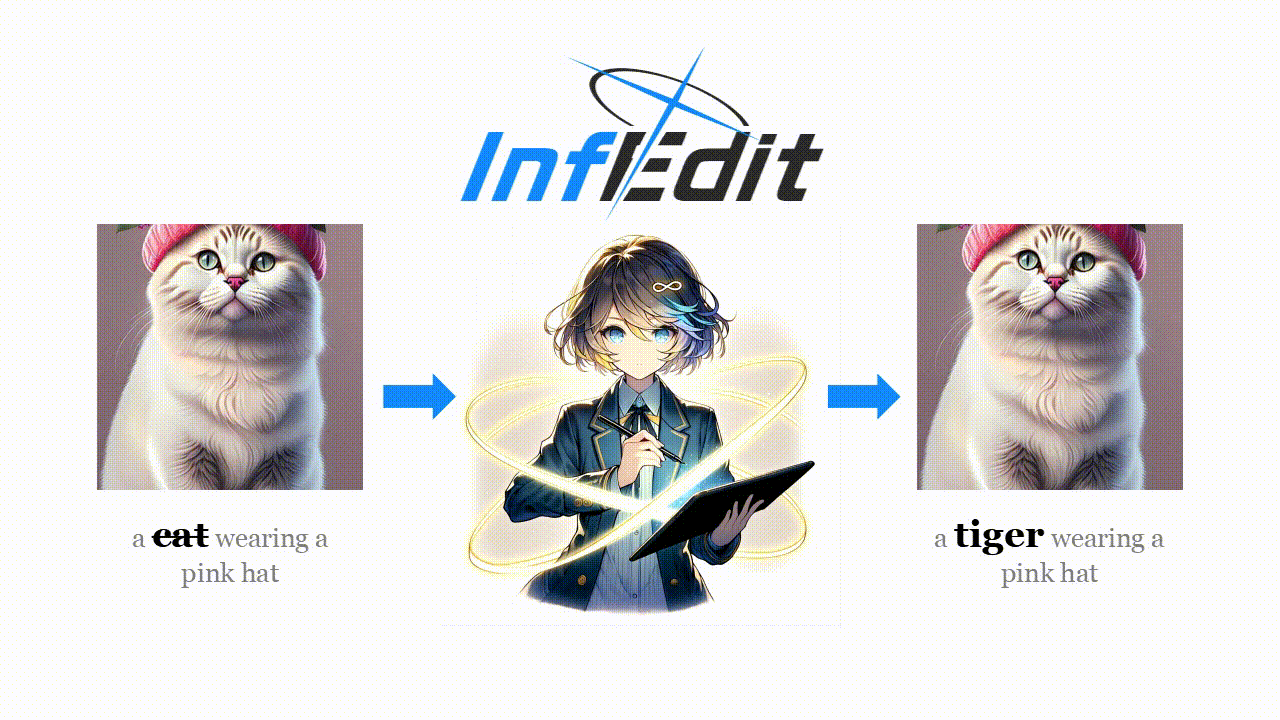
CVPR 2024に採択された論文
自然言語で指示を書くと、画像の編集をしているような画像を生成し直す技術。
Img2ImgやControlNetなどで、似たような画像を生成しなおす技術はあったが、この論文だと、入力の画像と、プロンプトのembeddingsの差分をベースに生成している。
‣
メインTOPIC: VerifiNER: Verification-augmented NER via Knowledge-grounded Reasoning with Large Language Models (ACL 2024)
概要
ドメイン特化型の固有表現認識(NER)、特にバイオメディカルNERにおいて、エンティティに関する知識が予測の正確さを向上させるフレームワークを提案。
提案されているのは「VerifiNER」という、既存のNER手法によるエラーを外部知識を用いて識別し、より信頼性の高い予測に修正するための事後検証フレームワーク。
問題とする対象の特性分析

NERのミスは上記パターンに分類されるが、既存のNERモデルの性能評価を行ったところ、以下のようにFP (False -Positive) が特定のモデルに対しては多くを占めるということがわかった。

スパンの間違い時のトークン数のズレも1、2トークンの範囲で起きている事例が多く、元のNERの結果を全て破棄するのではなく検証・修正するのが精度向上に寄与すると判断した

提案手法

Verify と銘打たれているが、提案手法では検証と同時に修正を行う。
エンティティのスパンを定めてからタイプを定めるというコンセプトにしている。
これは以下の理由による。
For example, the type of “PEBP2” is “protein”, but a longer span, “PEBP2 site”, is classified as “DNA”; thus, we first identify spans and then proceed to determine types.
- step 1 (Figure 4 の a)
- 予測されたエンティティスパンに対し、αによる調整を行った候補セットを生成
- [xbeg−α : xend+α] (アルファはハイパーパラメータ)
- 各候補がKnowledge Baseに存在するかをチェックし、このチェック時点でKBに全く存在しない候補は削除
- step 2 (Figure 4 の b)
- step 1 で得られた候補たちについて、以下のようなプロンプトによりLLMを用いてラベル付けを行う
- このように行うのは下記の例から分かる通り、KBに記された情報が直接的にラベルに結びついているわけではないため

- step 3
- 複数の理由付けによる投票制を敷いたプロンプトにて最終的に適合するエンティティを特定する

Experiments
- データセット
- BC5CDR という、Chemical と Disease という問題領域で cell_line, cell_type, DNA, RNA and protein の5つのタイプによるアノテーションが行われたデータセット
- GENIAという、同様に5つのタイプによるアノテーションが行われたデータセット
- Knowledge Base
- UMLS (Unified Medical Language System)という200万以上の生物医学用語の定義、意味タイプ、語彙関係を含むデータベース
- 改善元のNERモデル
- ConNER
- BioBERT
- GPT-NER
- Baseline Methods
- Manual Mapping: 予測を検証するために外部の知識を利用する。KBで見つかった意味タイプを定義済みのラベルに手動でマッピングすることで、エンティティタイプを再割り当てする
- LLM-revision:LLMを使った単純な修正。モデルは入力コンテキストを再調査し、マークされた予測エンティティに基づいて修正コンテキストを生成する
- LLM-revision w/ CoT: LLM修正にゼロショットCoTを加える

RQ
- RQ1:VERIFINERは誤差を忠実に識別し修正できるか?
- 全てのNERモデルにおいて、VERIFINERは一貫して、両データセットの初期予測値に対して大幅な改善を達成した。これは我々のモデルに依存しない検証手法の有効性を示している。
- また、他の修正ベースラインを顕著なマージンで上回る。LLM-revisionとw/ CoTを我々のものと比較すると、LLMの内部知識のみに依存すると性能が低下し、エンティティ予測を忠実に検証するためには信頼できる外部知識源が必要であることがわかる。
- 検証には信頼できる知識を取り入れることが不可欠であるが、Manual Mappingの性能低下は、さらに、検索された知識とモデル予測とのギャップを埋める中間推論プロセスの必要性を浮き彫りにしている。
- 提案手法はエンティティの述語を正確に修正することを目的としているため、必然的にリコールが低下することが予想される。しかし、すべてのNERモデルにおいて、リコールを大きく低下させることなく、かなりの精度の向上を達成していることに我々は気づく。全てのデータセットとモデルにおいて、精度の平均向上は20.03%である一方、想起の低下はわずか1.09%である。
- RQ2:VERIFINERは様々なテスト分布で微調整されたモデルへの汎化性を誘導できるか?
- ファインチューニングするデータセットと評価するデータセットを違えて評価
- ソースデータセットとターゲットデータセットの間でエンティティの種類が異なることになるモデルは検証に相応しくないため N/A とした
- プロンプティングベースのLLM(GPT-NER)よりもはるかに優れた性能を発揮し、ターゲットデータセットで訓練したベースラインと同等の性能さえ達成した。このことは、VERIFINERが、訓練データセットにアクセスできない未知のデータセットにおいて、微調整されたNERモデルの性能を高めることができることを示唆している
- データシフトを想定したデータセット分割による学習と評価
- BioBERTとCONNERの両方において、我々のアプローチは、ターゲット分布で訓練された分布内集合と同等でさえある。特に、VerifiNERはGENIAのターゲットデータセットで訓練されたBioBERTをF1スコアで14.59%も上回っている。これは、VERIFINERが信頼できる外部の知識ソースに基づく予測を検証することで、ソース分布にオーバーフィットすることなく汎化する能力を強調している。


- RQ3:VERIFINERはドメイン固有NERにおける低リソースの課題を効果的に軽減できるか?
- 学習データの量を5%から100%まで段階的に変化させたときの性能変化
- BioBERTとCONNERの性能が、両データセットで検証されたすべての低リソースシナリオにおいて顕著に向上することを示している。
