
2024-04-25 機械学習勉強会
今週のTOPIC
※ [論文] [blog] など何に関するTOPICなのかパッと見で分かるようにしましょう。
出典を埋め込みURLにしましょう。
@Naoto Shimakoshi
[blog] Kaggle LLM Prompt Recoveryコンペまとめ

- original_textとrewritten textが与えられて、promptを当てるコンペ
- 正解のpromptと提出したpromptをsentence-t5-baseに入れて、Cosine Similarityを3乗したものの平均値が評価指標
- アプローチ
- LLM:LLMに直接聞いてpromptを教えてもらう
- mean prompt:全てのサンプルについて固定の文字列を予測するアプローチ
- 解法
- 上位はMistral 7Bを使っている + Magicを使っている場合が多い
- Magic: という文字列を入れるとt5-baseのコサイン類似度がめちゃくちゃ上がるらしい
- 工夫
- mean promptをビームサーチで探索
- mean promptだけでも金メダル取れたり
- LLMとmean promptのアンサンブル
- 単純にconcat
- その他にも色々な工夫がblogにはまとめられている
- magicを見つけられたのかを検証した実験をされていて、個人的に面白かった
- 参加者が公開したデータセットのrewrite_promptをt5-baseでembeddingにしてからその平均を計算して、一つの768次元の埋め込みを得る(mean embeddingとします)
- で得られる単語32100個について、mean embeddingとのSCSを計算する
- SCSで降順ソートすると、は約40位(上位0.13%)に入っている。これ以外の上位の単語を見ると、"essay", "summarize", "narrative"などいかにもrewrite_promptの文言に入りそうなものが並んでいるため、は非常に浮いている。
@Yuya Matsumura
「AI事業者ガイドライン(第1.0版)」を取りまとめました
- AIがもたらす社会的リスクの低減を図りつつも、AIのイノベーション及び活用を促進していく目的で作成されたガイドライン
- これまで総務省や経済産業省の主導で作成されてきた3つのガイドラインを統合・見直しつつ、諸外国の動向や新技術の状況を考慮しつつ作成された。

- 総務省、経済産業省および教育・研究機関や民間企業等で構成されるマルチステークホルダーで議論、検討を重ねて作成されたガイドライン
- 「AI を活用する事業者(政府・自治体等の公的機関を含む)が安全安心な AI の活用のための望ましい行動につながる指針(Guiding Principles)を確認できるものとしている。」

- AI活用に関わる主体を3つに分けた上で、「ステークホルダーからの期待を鑑みつつどのような社会を目指すのか(「基本理念」 = why)」や「AI に関しどのような取組を行うべきか(指針 = what)」、留意点を解説している。
- AI開発者(AI Developer):AIシステムを開発する事業者
- AI提供者(AI Provider):AIシステムをアプリケーション、製品、既存のシステム、ビジネスプロセス等に組み込んだサービスとしてAI利用者、場合によっては業務外利用者に提供する事業者
- AI利用者(AI Business User):事業活動において、AIシステムまたはAIサービスを利用する事業者
- 3つの基本理念


@Tomoaki Kitaoka
[blog]アノテーションにおけるUIの工夫
- 作業手順
- 図面中に矩形領域(バウンディングボックス)を作成する
- バウンディングボックスに対してテキストを入力するGoogle Cloud
- バウンディングボックスに対してラベル(テキストの種別となるカテゴリ値)を付与する

- 便利機能
- テキストの自動入力
- バウンディングボックスを作成したときにOCRモデルによってテキストを推論し、自動入力している
- バウンディングボックスの自動スナップ
- 手動で作成されたバウンディングボックスの中からテキスト自体のbboxを作成(紫部分)

@Yuta Kamikawa
[blog]銀行データのような合成データを人工的に作ってみた
概要
機密性の高い銀行データは、データ数不足や外部に共有する際のプライバシー保護の課題があり、それをクリアするために人工データを作ってみたというブログ
まとめ
- 合成データの生成は、特に機密性の高いデータの扱いにおいて重要な技術。
- 機密性データはデータ不足になりやすいし、外部と共同開発や発表ができない。
- プライバシーを保護しつつ、実データと性質の似た合成データで代替したい。
- 実験の結果、合成データが実データの有用な代替となり得ることが示されたが、モデルによってはプライバシー保護の強度やデータの再現性に差があることも明らかになった。
- 使用する合成データ生成モデルを選択する際には、その目的と要求されるプライバシー保護のレベルを慎重に考慮する必要がある。
合成データとは
- 実際のデータ (実データ) の統計的性質を反映しつつも、実データとは異なる、人工的に生成されたデータ。
- 機密性の高いデータを、セキュリティが比較的厳重でない環境や、外部と共有された環境で利用して機械学習モデルを開発する場合に、合成データの内容から実データの内容を推定できないようにすることで、実データのプライバシーを保護しつつ利用することができるデータ。
合成データの意義
- 実データの性質を反映した合成データを用いることで、他社やアカデミアとデータの共有や共同開発、研究発表が可能になる
- クラスのimbalanceが大きい場合、少ないクラスのサンプルを人工的に生成することで、モデルの性能が向上する可能性がある
- 実データに不公平性が存在したとしても,公平なデータを人工的に生成することでモデルの予測を公平にする
- 例えば、銀行のデータに対しては,過去の融資データから学習したモデルが人種や性別などに関するバイアスを元に融資の判断をしてしまうことを防ぐ
プライバシー保護
- 合成データを安全に使用するためには、生成過程で差分プライバシーやIdentifiability Scoreなどのプライバシー保護技術が用いられるる。
- もしデータが漏洩しても実データを特定できないように保護される
合成データの生成モデル
- 統計値をベースにした手法、Baysian Network,、VAE (Variational Autoencoder)、GAN (Generative Adversarial Network)、Normalizing Flow、Diffusion Modelをもとにした手法などがある
実験
- 実験目的は,銀行のデータに近いデータを用い,プライバシーを保護する生成モデルの中で最良の合成データを生成するモデルを明らかにすること
- 生成モデルとしてDP-GAN, PATE-GAN, ADS-GANを比較
- 合成データを評価する観点は、実データと似た性質を持っているか、実データのプライバシーが保護されているかという2点
- 実データで学習を行った場合と、合成データで学習を行った場合で、定期預金加入有無を予測するモデルの訓練とテストを行った際のROC AUCが近いかどうか
- プライバシーを保護できているかのIdentifiability Score
実験結果
- PATE-GANがプライバシーを保ちつつ、実データに近い性質を持つ合成データの生成に成功していた
@Shun Ito
[blog]AIを使った論文の読み方
- ChatGPT, Calude, Readableを使った論文の読み方紹介
- LLMに要約してもらえるのは便利。(5歳児は個人的にはあまりわかりやすくない気がする…)
- Readableお世話になっています
@qluto (Ryosuke Fukazawa)
[blog] Chronon, Airbnb’s ML Feature Platform, Is Now Open Source
Airbnb が構築した、特徴量エンジニアリングまで含めた機械学習パイプラインプラットフォーム
Stripe との共同開発もされており、追いかけで発信された記事がこちら。
Shepherd: How Stripe adapted Chronon to scale ML feature development
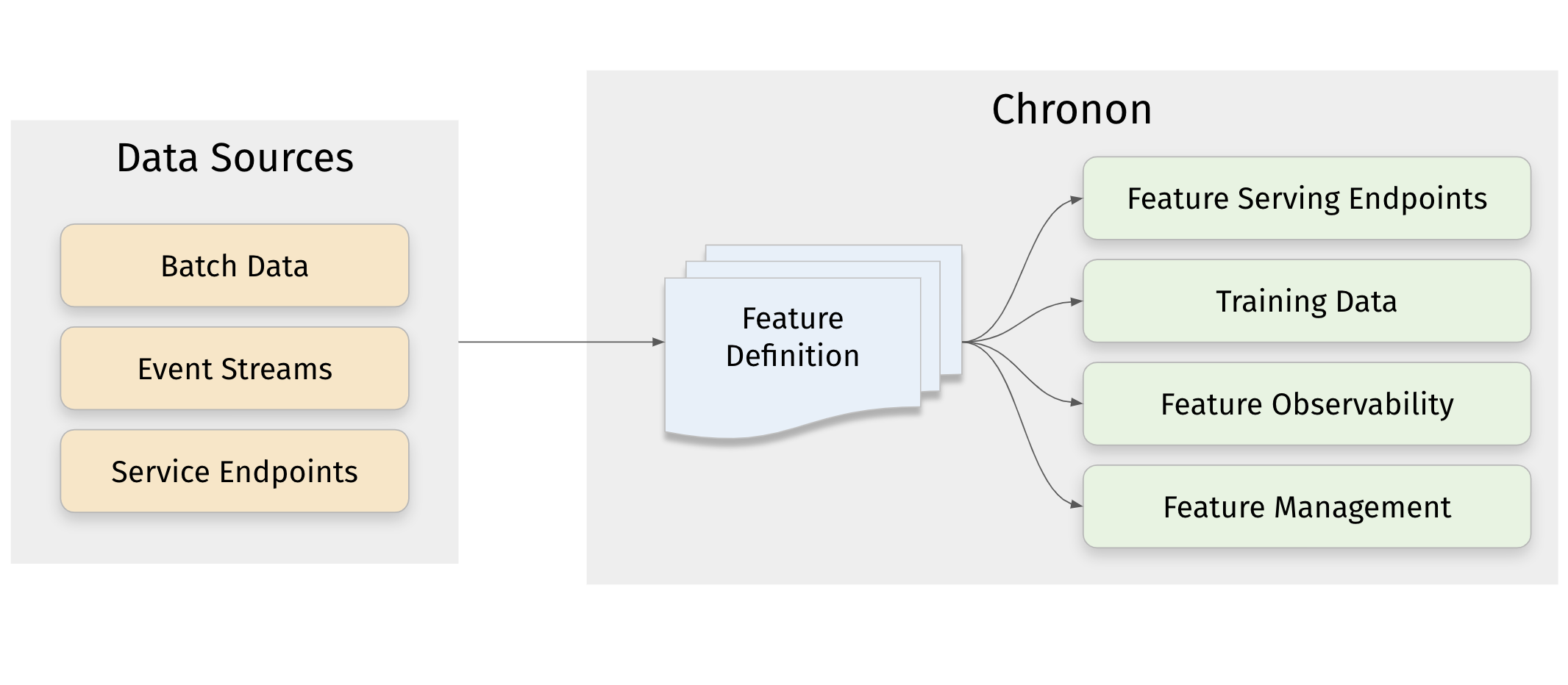
Key feature
- データをさまざまなソースから取り込む ― イベントストリーム、DBテーブルのスナップショット、変更データストリーム、サービスエンドポイント、および、スローリーチェンジングディメンション、ファクトテーブル、またはディメンションテーブルとしてモデル化されたウェアハウステーブル
- オンラインとオフラインのコンテキストの両方で結果を生成 ― オンラインでは、機能提供のためのスケーラブルな低遅延エンドポイントとして、オフラインでは訓練データ生成のためのハイブテーブルとして。
- リアルタイムまたはバッチ精度 ― 結果を時間的またはスナップショット精度のいずれかに設定できます。時間的精度とは、オンラインコンテキストでリアルタイムに機能値を更新し、オフラインコンテキストで時点正確な機能を生成することを指します。スナップショット精度とは、特徴が毎日真夜中に一度更新されることを指します。
- 生データから訓練セットのバックフィル ― モデルを訓練するために機能ログが蓄積されるのを何ヶ月も待つ必要はありません。
- 強力なPython API ― データソースの種類、新鮮さ、およびコンテキストはAPIレベルの抽象化であり、group-by、join、selectなどの直感的なSQLプリミティブとともに、強力な機能強化を組み合わせて使用します。
- 自動化された機能モニタリング ― 訓練データの品質を理解し、訓練と提供の偏りを測定し、機能のドリフトを監視するためのモニタリングパイプラインを自動生成します。
裏に Apache Spark, Apache Flink, MongoDB, Apache Airflow がいる。それらをインテグレートしてモデル開発者の負担を下げるのが目的と言える。
データ処理を一段抽象化して扱うことができるので、Key feature に取り上げたような機械学習モデル開発・運用で生まれてくる細かな差異を吸収することができる。
いきなりこのOSSを組み入れる前提とはせずとも、ハイレベルでの設計を参考にして自分たちの処理フローを組み上げるという目的でキャッチアップするといいことがありそう。
メインTOPIC
A Comparative Survey of Deep Active Learning
- Deep Active Learningに関するサーベイ論文
- Active Learning
- Pool-based AL: ラベル付けされていないデータの中から、アノテーションや学習のためのサンプルを選択
- 学習器がある程度の性能に達するか、一定の予算を使い果たしたら反復終了
- Deep Active Learning
- Deep Learning with Active Learning
- 古典的なALとの違い
- DNNの学習に伴ってfeature mapの表現も変化していく → stepごとにALに入力される特徴量が変化する
- DNNの出力スコアは自信過剰になりがちなので、ラベル無しデータに対する出力を不確実性として扱うのは信頼性が低くなる場合がある

- この論文の意義
- 異なるデータセット・タスク間のDALアルゴリズムの比較
- 19のDAL手法を実装し、DeepALというツールキットを作成
手法の分類

Uncertainty-based(不確実性)
- 古典的なMLタスクにも適用されている手法
- Maximum Entropy: 予測スコアのエントロピーが最大のデータを選択
- Margin: 予測スコアの大きい2つの差が小さいデータを選択
- Least Confidence: 最大スコアが最も小さいデータを選択
- Bayesian Active Learning by Disagreements (BALD): ベイズ的にモデルのパラメータが得られる情報量が最も多いデータを選択
- Mean Standard Deviation: 各クラスの予測確率の標準偏差をクラス全体で平均し、最も大きいデータを選択
- 標準偏差はMonte Carlo Dropoutでランダムにドロップアウトしたモデルで予測を繰り返して計算する?
- adversarial attacksを利用
- AdvDeepFool: DeepFool Active Learning
- 最も小さい摂動でラベルが変化するデータをサンプリング
- 二値分類問題だと、決定境界までの距離が最も近いデータ
- データ生成
- GAAL: Generative Adversarial Active Learning
- アノテーションするデータをGANで生成する
- 生成されたデータが決定境界に近すぎると、人間でも判断できなくなるのが課題
- BGADL: Bayesian Generative Active Deep Learning
- BALDとVAE-ACGANを組み合わせてデータ生成
- ACGAN: discriminatorがデータ判別だけでなくクラスラベル分類も行う
- GAALよりも目的のクラスに該当する画像を生成できるようになった

- その他
- Wang et al: 勾配のノルムが大きいデータを選択
- BADGE: Batch Active Learning with Diverse Gradient Embeddings
- 出力層のパラメータに対する勾配が大きいデータを選択
- LPL: Loss Prediction Loss
- あるデータに対するlossを予測するモデルを同時に学習
- 予測lossの大きいデータを選択

Representative/Diversity-based(多様性)
- ラベル付けされていない集合を代表するサンプルのバッチを選択する(少ないデータで全体を表現する)
- クラスタリングベースの手法: k-means等をかけてクラスタごとにデータを選択
- CoreSet: 最終層空間 h(x) で最近傍への距離が最も大きい(近くにラベル付きデータが無い)ラベル無しデータを選択
- VAAL: Variational Adversarial AL
- VAE (encoder) でラベル付きデータの潜在空間を学習し、敵対的ネットワーク (discriminator) でラベル無し・ありデータを見分ける
- ラベル無しと判定されたデータを選択
- “ラベル付きデータと似ていない”データを選べる
- WAAL: Wasserstein Adversarial AL
- H-divergenceを使ってラベル付きデータよりも多様性の高いラベル無しデータバッチを作成する
Hybrid/combined strategy
- weighted-sum optimization
- シンプルな方法: 不確実性・多様性の2つのスコアを重み付けする
- 多様性(代表性)が行列形式(2つのデータ間の距離など)で表されるので、不確実性と合わせて単体のデータに対する指標として落とし込みづらい
- two-stage optimization
- 異なる基準を使用して、前の段階の選択をより洗練させる
- WAAL: discriminative featuresの学習 → データ選択の2段階
- BADGE: 最終層の各パラメータについての勾配を計算(不確実性ベース) → k-means++でクラスタリング(多様性ベース)
Enhancing of DAL Methods
- limitation: どのAL手法も、サンプリングすると全部のデータで学習した精度を下回ってしまう
- データ観点の手法
- データ拡張や擬似ラベルの利用
- CEAL: Cost-Effective Active Learning
- あるステップで確信度の高い予測ラベルを次のステップの擬似ラベルにする

- モデル観点の手法
- ネットワーク追加、損失関数変更、アンサンブル
- LPL: 対象のモデルと損失予測モデルを同時に学習し、対象モデルがどういうデータに間違えやすいか予測できるようにしている
- WAAL: ラベル無しデータを使ったmin-max loss
- Gal et al.: Monte-Carlo Dropoutによるアンサンブル
- Beluch et al.: 不確実性スコアの計算では、複数の分類器使う方がMC Dropoutより良い
比較実験
データ
- image classification taskに限定
- MNISTやCIFAR10など一般的なデータ、医療画像
DAL methods
- random, entropy, margin, leastconf, それらのMC Dropout version
- BALD, MeanSTD, VarRation, CEAL, KMeans, KMeansGPU, CoreSet (greedy version)
- BADGE, AdversarialBIM, WAAL , VAAL, LPL
結果

- 全体的な精度・パフォーマンスの傾向は、Enhance > 不確実性 > 多様性
- カテゴリ数が多すぎると、LPLの損失予測やWAALの特徴抽出がうまくいかない
- LPLは特定のデータセット(EMNIST, Tiny ImageNet)で顕著に悪くなる
- WAALもTiny ImageNetで顕著に悪い