
2024-06-13 機械学習勉強会
今週のTOPIC[slide] 独立成分分析を用いた埋め込み表現の視覚的な理解[blog]Doing RAG? Vector search is *not* enough[blog] 大公開!バッチアプリケーションの品質を高めるZOZOの『バッチ開発ガイドライン』[やってみた] mmdetectionを使ってdocument layout analysis!![記事] Introducing Apple’s On-Device and Server Foundation Models[blog] A Visual Guide to Evolution StrategiesEvolutionary Optimization of Model Merging Recipes概要モチベーション関連研究モデルマージの概要言語モデルのマージ手法ニューラルアーキテクチャ検索 (NAS) との比較手法パラメータ空間 (PS) でのマージデータフロー空間 (DFS) でのマージ両方の空間でのマージ実験日本語数学LLM日本語VLM
今週のTOPIC
@Naoto Shimakoshi
[slide] 独立成分分析を用いた埋め込み表現の視覚的な理解
- 独立成分分析 (ICA)の方がPCAなどより解釈性が高いという話。
- スパース性かつ解釈可能性が高い
- 次元を減らしても加法構成性が崩れていない (非ゼロ成分が10個でも意味の演算の精度が落ちづらい)


- 異なる言語の単語埋め込みは回転で重なるという研究がある。
- ICAだと異なる言語の埋め込みでも形と意味が共通のものになる。(PCAだとめちゃくちゃ)

- モデルやドメインにもよらず解釈可能性が高い

- なぜうまくいくのか?
- ICAはPCA + 直交変換
- 直交変換することで「尖った形状」を見つけられ、「尖った形状」が解釈可能

- ICAが取り除けない高次相関
- ICAの仮定として独立成分が線形に分離できるというものがあるが、これが強い仮定で高次相関が生じてしまう。
- 例) 3人の合成音声を3つに線形分離できる
- 高次相関が強いと、意味の関連性が高い


@Yuya Matsumura
[blog]Doing RAG? Vector search is *not* enough
- RAGにおいてベクトル検索のみでは不十分だよねという記事。
- (それはそう、というかなんでみんなベクトル検索という難しいところからやるんや。)
- それはそうというのをMSさんとかが発信してくれることには価値がありますね。
- ベクトル検索に全文検索とrerankを組み合わせたハイブリッド検索を推奨
- Azure AI Searchを利用したハイブリッド検索の実装を説明。
@Tomoaki Kitaoka
[blog] 大公開!バッチアプリケーションの品質を高めるZOZOの『バッチ開発ガイドライン』
- ZOZO社のバッチアプリケーションを開発するためのガイドライン
- 大事なことがまとまっている
- バッチ処理の品質はデータの品質に大きく関わるので大事にしたい
- 一部抜粋
- 依存関係があるバッチにはワークフローエンジンを利用する(RECOMMENDED)
- 処理ごとにコンピュートリソース(CPU/メモリ/ストレージ)を選択できる(RECOMMENDED)
- 処理ワーカーが自動スケールされる(RECOMMENDED)
- リトライはツール・ライブラリに任せる(RECOMMENDED)
- 処理を冪等にする(MUST)
- 現在日時に依存する処理を入れない(NOT RECOMMENDED)
- ひとつひとつの処理を小さくする(RECOMMENDED)
- ワーカーを増やせば処理性能が線形に伸びるように実装する(RECOMMENDED)
- 早い段階でValidationを行う(RECOMMENDED)
- 処理失敗時に通知する(MUST)
- 処理時間のSLAを設ける(MUST)
- バッチ処理が適切に動作を開始しているかを監視する(MUST)
- 月1回など実行頻度の少ないバッチは極力避け、原則デイリー実行にする(RECOMMENDED)
@Yuta Kamikawa
[やってみた] mmdetectionを使ってdocument layout analysis!!
document layout analysisはobject detectionやinstance segmentationでdocumentから項目抽出するタスク。
これをmmdetectionでやってみる。
- データセット
- document layout analysisのデータセットである‣を用いた
- 他のデータセットに比べ、請求書などのさまざまな書類が含まれており、汎用的なdocment layout analysisのモデルの学習を行うことができる
- COCOフォーマット
- 学習
- ‣の学習スクリプトを使って、公式チュートリアルに倣って学習
- configファイルを学習スクリプトに渡すだけで学習を回すことができる
- 学習スクリプト
自前データセットで学習する場合は、mmdetectionリポジトリのyoloxのconfigファイルを修正して使う()
- 推論

@qluto (Ryosuke Fukazawa)
[記事] Introducing Apple’s On-Device and Server Foundation Models
WWDCにて発表された内容のうち、LLM周りの話に踏み込んだ発信。
日本語翻訳&ハイライトをまとめた記事はこれがちょうど良さそう → ‣
Appleの「Apple Intelligence」は、iOS 18、iPadOS 18、macOS Sequoiaに統合された個人用インテリジェンスシステムです。3Bパラメータのオンデバイスモデルと、Apple Siliconサーバー上で動作するサーバーモデルが含まれ、日常タスクの効率化に特化しています。ユーザーの活動に合わせて適応し、テキストの作成や通知の要約、画像生成などを行います。さらに、Xcode向けのコーディングモデルや、メッセージアプリでの表現を支援する拡散モデルも提供されます。
Appleの「Foundation Models」では、オンデバイスとプライベートクラウドでの高速かつ効率的な最適化が行われています。両モデルは、メモリと推論コストを削減するために、グループ化クエリ注意機構と共有ボキャブラリ埋め込みテーブルを使用しています。オンデバイスモデルは49K、サーバーモデルは100Kの語彙サイズです。低ビットパレット化やLoRAアダプターを用いた新フレームワークで、圧縮モデルと同等の精度を実現。iPhone 15 Proでは、約0.6ミリ秒の初期トークンレイテンシーと30トークン/秒の生成率を達成しています。

Appleの「Foundation Models」は、ユーザーの日常タスクに合わせて動的に特化します。アダプターと呼ばれる小さなニューラルネットワークモジュールを使い、注意行列や完全連結層を微調整。これにより、基礎モデルの一般知識を維持しつつ、特定のタスクに適応。アダプターパラメータは16ビットで表現され、オンデバイスモデルでは数十メガバイトのメモリを使用。アダプターは動的に読み込まれ、メモリ効率を保ちながら迅速な適応が可能です。
@Yosuke Yoshida
[blog] A Visual Guide to Evolution Strategies
Simple Evolution Strategy
- 平均 と固定された標準偏差 を持つ正規分布から一連の解をサンプリング
- 適応度の結果が評価された後、 は集団の中で最良の解に設定され、次の世代の解をこの新しい平均の周りでサンプリングする
- 下記のビジュアライゼーションでは、緑の点が各世代の分布の平均を示し、青い点がサンプリングされた解、赤い点がこれまでにアルゴリズムが見つけた最良の解を示しています
- この単純なアルゴリズムは、一般的に単純な問題にのみ効果的です。その貪欲な性質により、最良の解以外はすべて捨ててしまい、より複雑な問題では局所的な最適解に陥りやすくなります。次の世代を、現在の世代の最良の解だけでなく、より多様なアイデアを表す確率分布からサンプリングすることが有益です
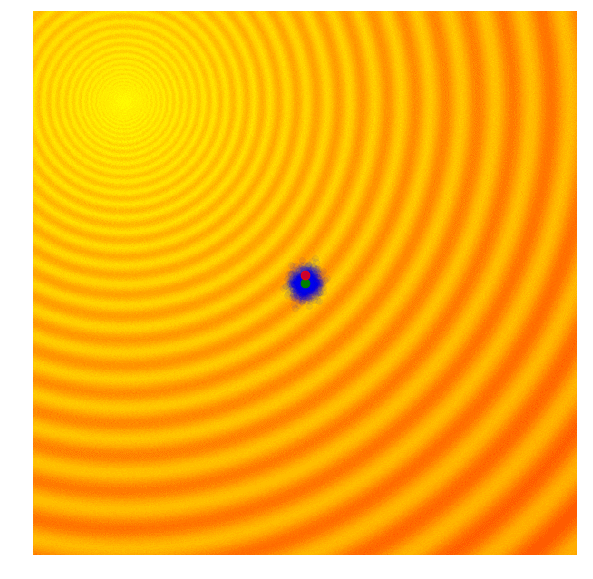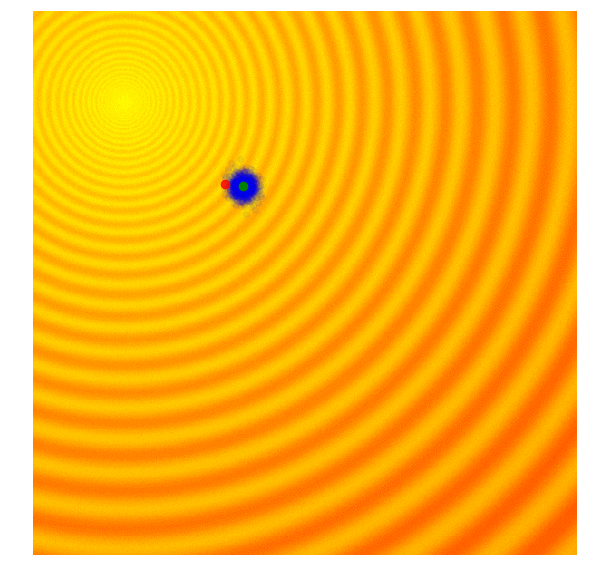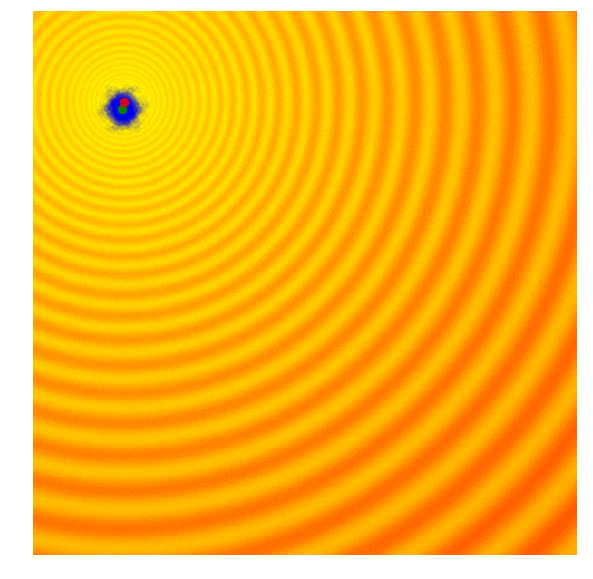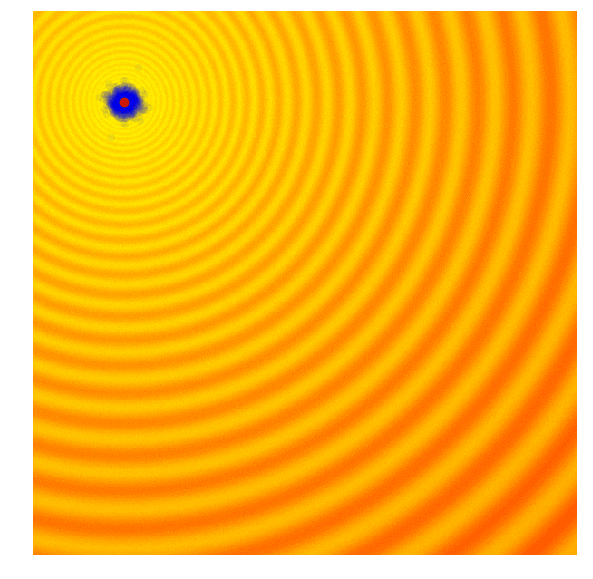
Simple Genetic Algorithm
- 現在の世代の上位10%の解だけを保持し、残りの個体はすべて死滅させます。
- 次の世代では、新しい解をサンプリングするために、前の世代の生存者からランダムに2つの解を選び、そのパラメータを再結合して新しい解を形成します。
- このクロスオーバー再結合プロセスでは、コイントスを使用して各パラメータをどちらの親から取るかを決定します。我々の2次元の単純な関数の場合、新しい解は50%の確率でどちらかの親から または を継承し、新しい解には固定された標準偏差のgaussian noiseも与えられます
- 緑の点は前の世代のエリート個体を表し、青の点は候補解のセットを形成する子孫を示し、赤の点は最良の解を示しています。
- 遺伝的アルゴリズムは、次世代を再生するために多様な候補解のセットを追跡することで多様性を助けます。しかし、実際にはエリート生存個体のほとんどの解が時間とともに局所的最適解に収束する傾向があります。GAのより高度なバリエーションとして、CoSyNe、ESP、NEATなどがあり、これらは集団内の類似した解を異なる種にクラスター化し、時間とともにより良い多様性を維持することを目的としています。
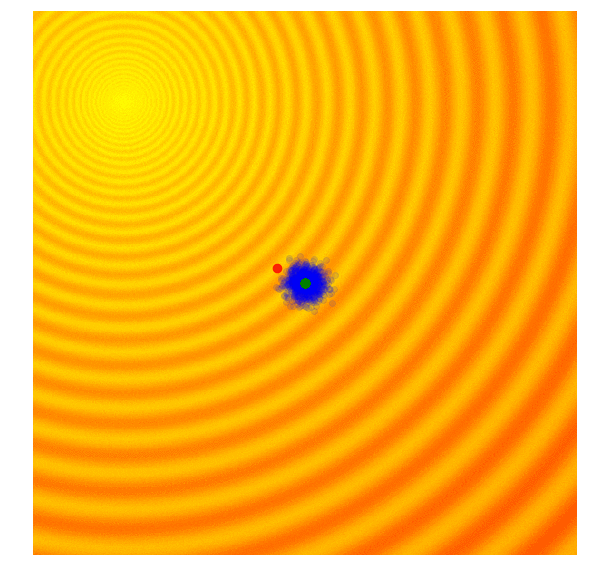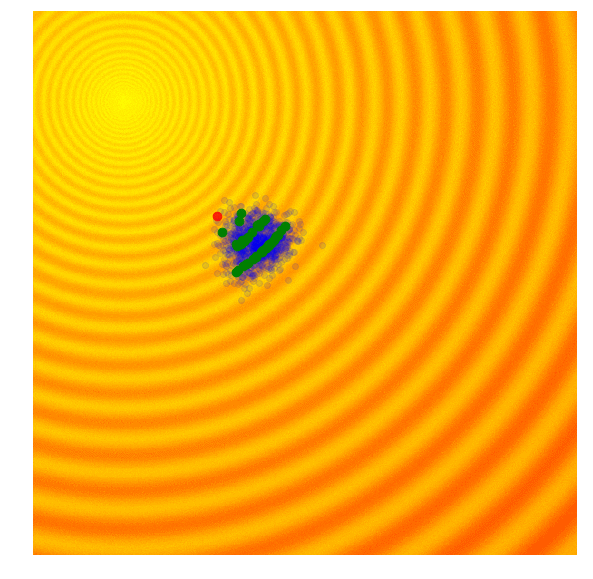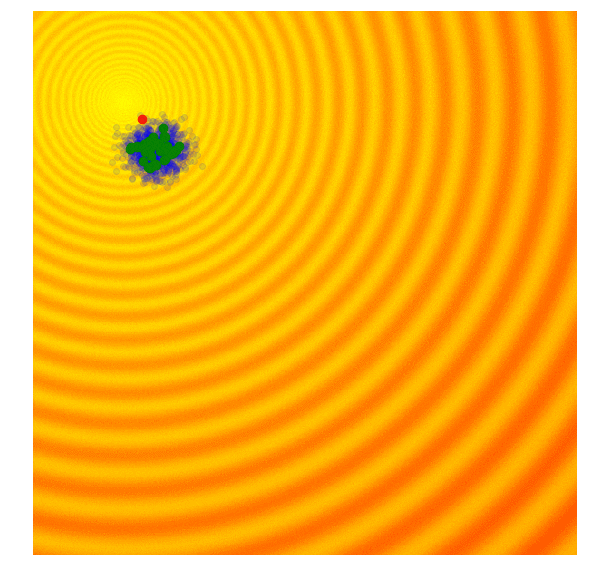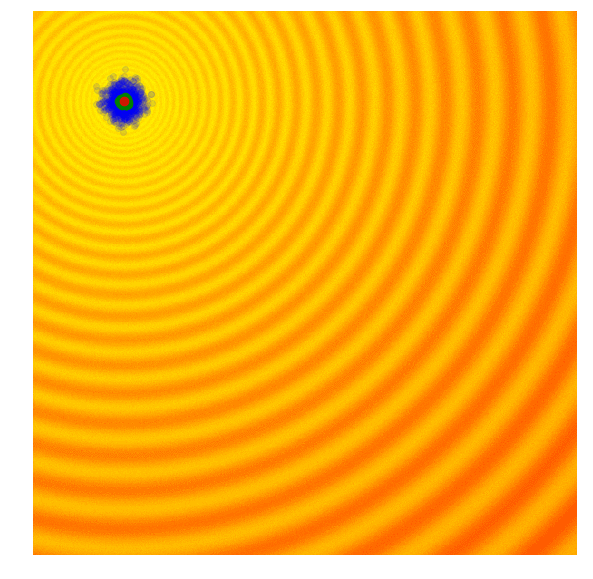
Covariance-Matrix Adaptation Evolution Strategy (CMA-ES)
- シンプルなESとシンプルなGAの両方の欠点は、標準偏差ノイズパラメータが固定されていることです。探索範囲を広げて標準偏差を増やしたい時もあれば、良い最適解に近いと確信して微調整したい時もあります
- CMA-ESは、各世代の結果を取り、次世代の探索空間を適応的に増減することができるアルゴリズムです
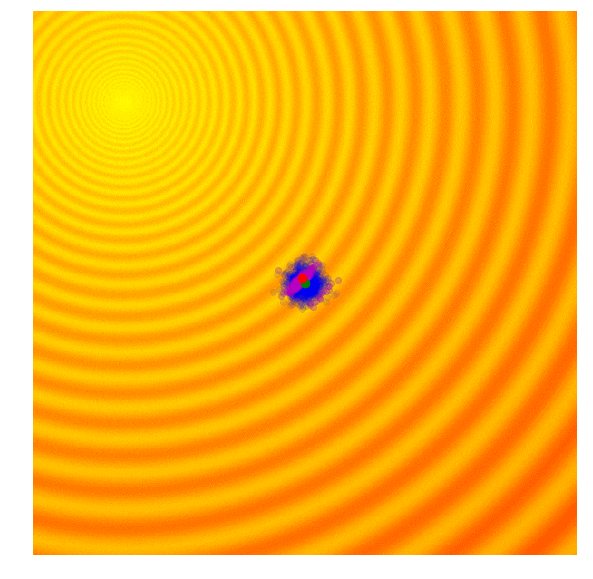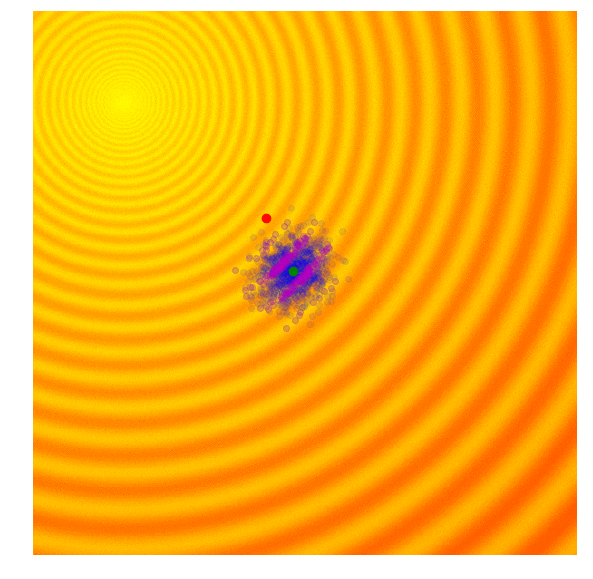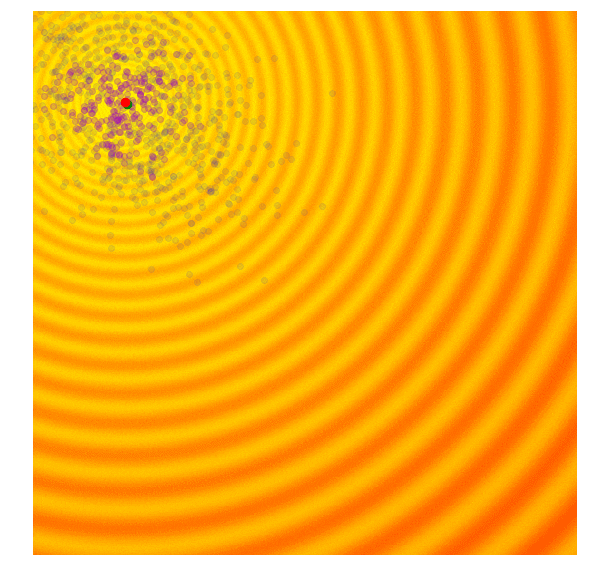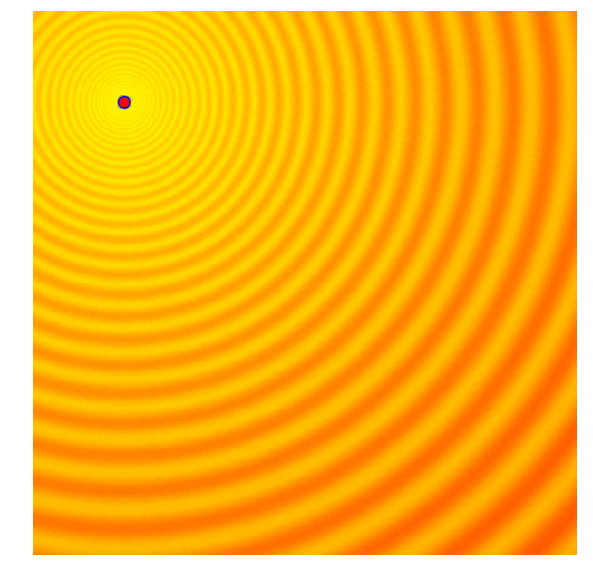

- 各候補解の適応度スコアを計算 (g世代)
- g世代の集団の上位25%を紫色で隔離
- g世代の平均(緑の点)と上位25%の集団を用いてg+1世代の共分散行列を計算
- g+1世代の平均(g世代の上位25%)と共分散行列を用いて新しい候補解のセットをサンプリング
Evolutionary Optimization of Model Merging Recipes
- Takuya Akiba, Makoto Shing, Yujin Tang, Qi Sun, David Ha
- Sakana AI
概要
- 基盤モデルを自動的に作成するための新しいパラダイムである進化型モデルマージを紹介
- 既存のOSSモデルを進化的アルゴリズムを用いて組み合わせることで、大規模なトレーニングデータや計算資源を必要とせずに、ユーザーが指定した能力を持つ新しいモデルを生成
- パラメータ空間とデータフロー空間の両方でモデルマージを最適化できることを示し、従来の手法では達成が困難なクロスドメインマージを実現
- 日本語LLM + 英語の数学LLM = 日本語の数学LLM
- 日本語LLM + 英語VLM = 日本語VLM
- これらのモデルは、さまざまなベンチマークでSOTAを達成し、進化型モデルマージの有効性と汎用性の高さを示した
モチベーション
- モデルマージは、複数のLLMを組み合わせて単一のモデルにすることで、追加のトレーニングを必要とせずに新しいモデルを開発できる、費用対効果の高いアプローチとして注目されている
- しかし、現状では、どのモデルをどのように組み合わせるかは、モデル作成者の直感や専門知識に大きく依存している
- 進化的アルゴリズムを用いることで、人間の直感では見つけるのが難しい、より効果的なモデルのマージ方法を自動的に発見すること、英語以外の言語や数学、視覚など、異なる分野のモデルを組み合わせることで、従来の人間による設計では実現が難しかった能力を持つモデルを生成する
関連研究
モデルマージの概要
- 転移学習との比較
- 転移学習では、事前学習済みモデルを新しいタスクに対してファインチューニングし、結果として得られるモデルは通常単一のタスクに限定
- 一方、モデルマージは、複数の事前学習済みモデルの知識を組み合わせることで、様々なタスクに対応可能な多用途かつ包括的なモデルの作成を目指す
- モデルマージの最も単純な方法 model soup approach
- 同じモデルからファインチューニングされた複数のモデルの重みを平均化
- 大規模画像分類モデルや画像生成モデルにおいて顕著な改善を示した
言語モデルのマージ手法
- Task Arithmetic
- 事前学習済みモデルからファインチューニングされたモデルの重みを引くことでタスクベクトルを作成し、算術操作を通じてマージモデルの動作を制御
- https://arxiv.org/abs/2212.04089
- TIES-Merging
- weight interpolationの主要な問題は、パラメータの干渉を無視することによる性能の低下
- TIES-Mergingでは干渉の2つの主な原因となる冗長なパラメータ値とパラメータ値の符号の不一致を特定し、マージすることで性能を向上
- https://arxiv.org/abs/2306.01708
- DARE
- 事前学習済みモデルのパラメータとファインチューニングされたパラメータと間の差異(デルタパラメータ)を効果的に削減
- デルタパラメータをランダムにドロップ(値をゼロに設定)、残りのパラメータをリスケールすることで元の埋込を近似し、モデルの性能を維持
- https://arxiv.org/abs/2311.03099
- Frankenmerging
- ‣ に実装されている複数のモデルから異なる層を積み重ねて新しいモデルを作成する手法
- この手法は、特定のアーキテクチャのモデルファミリーに限定されず、全く異なるモデルをマージして新しいアーキテクチャを作成できるという利点
- Frankenmergingの新しいレシピを発見することは、コミュニティにとって課題であり、試行錯誤が必要
ニューラルアーキテクチャ検索 (NAS) との比較
- 類似点
- 進化的アルゴリズムを用いて、最適なモデル構造を探索
- 人間の直感では発見困難な、新規かつ非自明な組み合わせを発見できる可能性
- 相違点
- 進化型モデルマージは、既存のTransformerブロックを活用することで、NASのようにモデルを訓練する必要がなく計算資源を節約できる一方、従来のNAS手法では、各候補モデルアーキテクチャの訓練に膨大な計算資源が必要
- NASは新しいアーキテクチャを探索するのに対し、進化型モデルマージは既存のモデルの組み合わせを最適化
手法

パラメータ空間 (PS) でのマージ
- PSマージは、複数の基盤モデルの重みを同じニューラルネットワークアーキテクチャを持つ単一のエンティティに統合
- DAREを使用してTIES-Mergingを強化し、より細かいレイヤ (入力/出力埋め込み層またはtransformerブロック) 単位でのマージを可能にする
- 入力と出力の埋め込みを含む各レイヤでのスパース化と重み付けといったマージパラメータを、CMA-ES などの進化的アルゴリズムを使用して、タスク固有のメトリクスによって最適化
データフロー空間 (DFS) でのマージ
- PSマージとは異なり、DFSマージでは、トークンがNN内をどのように通過するかという推論経路を最適化する
- 個のモデル、予算 (推論パスの総数)が与えられた場合、この手法は、特定のタスクに対してすべてのトークンがたどるべきパスを表すレイヤのシーケンスを探索する
- 全モデルのレイヤの総数を とすると、探索空間のサイズは と膨大になる (+1はpass-through layer)
- 探索空間を抑えるために、すべてのレイヤを順番に配置し(つまり、 番目のモデルのすべての層の後に 番目のモデルの層が続く)、それを 回繰り返し、各レイヤを含めるか含めないかを最適化 (探索空間は に縮小)
- DFSマージでは、推論パスのみが最適化され、パラメータはそのまま残されるので、レイヤが入力を受け取る際に、元のモデルとは異なる分布となり、予期しない出力が生成される可能性がある
- この問題を軽減するために、層 から へ移動する入力を で適切にスケーリングすることが有効であることを発見
- ここで はインジケータ配列 (各レイヤを含める or 含めない)とともに進化的アルゴリズムによって最適化される行列で、 のサイズはレイヤの数が増えると二次的に増加してしまう
- 探索空間を抑えるためのアプローチとしてNNを用いて をパラメータ化
- レイヤとステップに応じたスケーリングの重み を出力するFFNを最適化する。 が進化パラメータであり、 が増加してもサイズは不変
両方の空間でのマージ
- PSマージとDFSマージは、それぞれ独立しており、これらの方法を組み合わせることで、マージされたモデルの性能をさらに向上させることが可能
- 順番としては、まず複数のモデルに対してPSマージを行い、このPSマージされたモデルと他のソースモデルを合わせたコレクションに対してDFSマージを適用する
実験
日本語数学LLM
日本語で数学の問題を解くことができるモデルを開発するために、日本語LLMと数学LLMを含むソースモデルセットに対して進化的モデルマージを適用
ソースモデル
- shisa-gamma-7b-v1 (日本語LLM)
- WizardMath-7B-V1.1
- Abel-7B-002
データセット
- テスト
- MGSMデータセット (GSM8kデータセットの一部を多言語に翻訳)
- 最終評価
- 250サンプルからなるMGSMの日本語テストセット
- 進化的検索 (トレーニング)
- MGSMテストセットに含まれないGSM8kテストセットの残りの1069サンプルを日本語に翻訳
評価
- 日本語の数学問題に対する日本語の回答を生成する能力を評価
- 回答が正しいと見なされる条件
- 最終的な数値が正しいこと
- 推論のテキストが日本語で書かれていること
- 出力の言語を判定するためにfasttext を利用
- 出力に現れる最後の数値を回答として扱う
- 異なるフォーマットで訓練された複数のモデルを統合するため、出力フォーマットを修正するのが困難だった
- 生成にはgreedy samplingを使用し、Zero-shot pass@1 accuracy で評価
最適化
- PS
- TIES-MergingとDAREのパラメータを最適化
- CMA-ESを用いて1000回試行し、1069のトレーニングサンプル全体の精度に対して、最良の試行を最終モデルとして選択
- DFS
- トレーニングデータの最後の200例を検証セットとして保持し、残りのデータをバッチサイズ200で最適化 (CMA-ES)
- 最終モデルがひとつのGPUで実行できるように2つのモデルに限定
- A) PSマージの結果作成されたモデル
- B) shisa-gamma-7b-v1 (日本語LLM)
- トークナイザーと入力/出力埋め込み、推論パスの最初と最後のtransformer layerはモデルAを使用
結果
- モデル1~3はソースモデル、モデル4~6は最適化されたマージモデル、モデル7~11は参考値
- MGSM-JAは日本語の数学能力を、JP-LMEHは一般的な日本語能力を評価
- モデル1は数学能力が低い一方、モデル2, 3は数学能力は優れているものの、日本語の理解が不十分
- Ours(7~10B)はソースモデルおよび70Bパラメータ日本語LLMを上回るなど、非常に高いスコアを達成している

- 以下は数学の問題に対する5つのモデルの正解した箇所を色付けしたもの
- マージモデルはソースモデルの基礎知識を保持しながら、ソースモデルが解決できなかった問題を解決する新たな能力を獲得している

分析
- 以下はPSマージ後のパラメータ構成
- Weightの均一性から3つのモデルすべてが重要であることを示し、日本語LLM(Shisa Gamma 7B v1)のDensityの高さはタスクを解決するうえでの重要な貢献を示唆

- 以下の3つの図は、MGSM-JAタスクにおけるDFSマージの推論パスの進化を示す
- y軸: レイヤインデックス、x軸: 推論パスインデックス
- 青いマーカーはモデルA(PSマージ)のレイヤを利用するパスステップを示し、赤いマーカーはモデルB(日本語LLM)のレイヤを示す
- マーカーのサイズはスケーリング係数 の大きさを反映
- 進化的検索結果は、初期段階でモデルAのほとんどのレイヤを含み、その後、両モデルのレイヤが交互に使用されることを示す
- 特に、スケーリングパラメータWijは重要な要素として浮上し、アブレーションスタディでは、これらを進化モデルから除去する(例:Wij = 1と設定する)と、パフォーマンスが20%以上低下することが明らかになり、その重要性が強調されました

日本語VLM
- VLMのアーキテクチャは以下の三つのコンポーネントで構成
- 画像特徴を抽出するためのvision encoder
- 画像を説明するためのテキストを生成するためのLLM
- 画像特徴をLLMの埋め込み空間にマッピングするためのprojection network
- vision encoderとprojection networkを固定し、LLMコンポーネントのみに焦点を当てることで、拡張された能力を持つ新しいLLMを生成
ソースモデル
- shisa-gamma-7b-v1 (日本語LLM)
- LLaVA-1.6-Mistral-7B (英語VLM)
データセット
- テスト
- JA-VG-VQA-500
- Japanese Visual Genome VQAデータセットから抽出された500サンプル
- JA-VLM-Bench-In-the-Wild
- LLaVA-Bench-In-the-Wildの日本語版
- 日本の文化的要素や日本で見られるさまざまな物体を特徴とする合計50の質問を伴う42枚の画像のコレクション
- 進化的検索
- Japanese Visual Genome VQAデータセットのテストとは別のサブセットを使用
最適化
- PS
- 日本語数学LLMと同じくTIES-MergingとDAREを使用
- DFS
- 無し
結果
- 実験では、以下の二つのベースラインを考慮しました
- LLaVA-1.6-Mistral-7B
- Japanese Stable VLM
- 日本語データセットからスクラッチで訓練された日本語VLM
- JA-VG-VQA-500データセットで訓練されている
- JA-VG-VQA-500ベンチマークでの我々のVLMの性能向上は、日本語における熟練度を示しており、進化的統合を通じてソース日本語LLMと元のVLMのLLMコンポーネントの統合に成功したことを強調しています
- さらに、JA-VLM-Bench-In-the-Wildでの我々のVLMの優れた結果は、文化特有のコンテンツをナビゲートする能力の高さを示しています。
