Lost in the Middle: How Language Models Use Long Contexts

概要
- promptに与える長いコンテキストにおいて、コンテキスト内における場所が性能に影響を与える
- 特に、必要な情報がコンテキストのmiddleに位置する際に著しく性能に影響する
- 言語モデルにより長い入力コンテキストを与えることは常に有益とは限らない
こちらのイベントで紹介されていた論文
実験内容

- input
- 質問文
- wikipediaをソースとした歴史的な質問(アノテーション済み)
- NaturalQuestions-Open (Lee et al., 2019; Kwiatkowski et al., 2019)
- k-1件のドキュメント(そのうち1件のみが質問に答えるための情報を持っている)
- retrieval によって取得された質問文に対して近しいdocument (Contriever, fine-tuned on MS-MARCO; Izacard et al.,2021)
実験結果
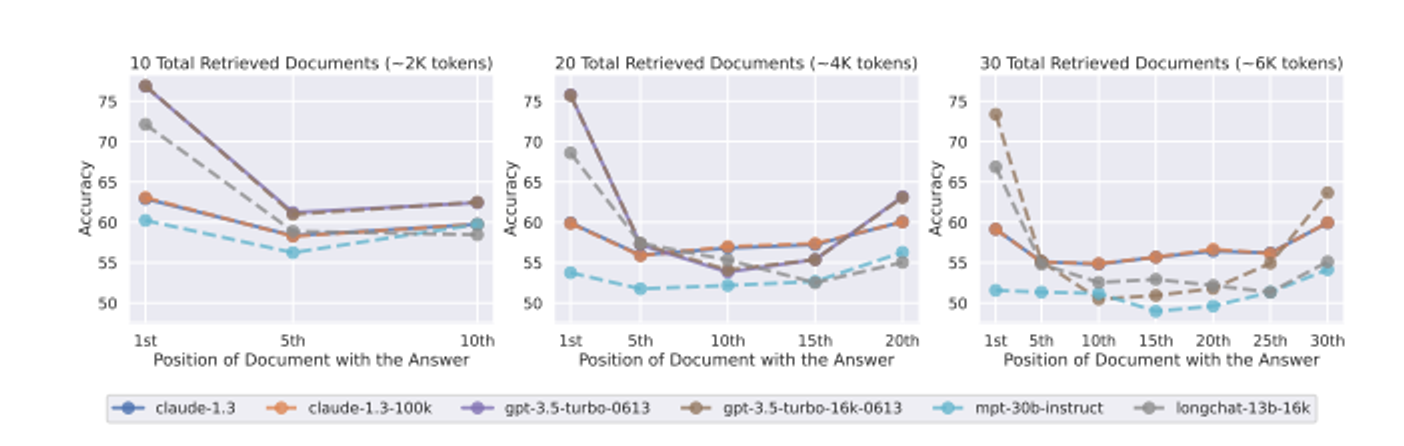
- モデルのパフォーマンスは関連するdocumentがコンテキスト内の序盤または終盤にあれば高くなる傾向にある
- 扱えるトークン数が増えたとて、コンテキストの活用能力が向上しているわけではない
- 10, 20件のdocumentの実験において、GPT-3.5-TurboとGPT-3.5-Turbo-16Kを比較したとき、パフォーマンスがほぼ重なる
実験内容

- 単純なUUIDのretrieveタスクでもやってみる
実験結果

- Claude-1.3とClaude-1.3 (100K)はほぼパーフェクト
- 他のモデルはkey-valueのペア数が増えた時に苦戦
- 140kvのlongchatはvalueではなくkeyを返してパフォーマンスが低い
要因考察
- Model Architecture
- Query-Aware Contextualization
- Instruction Fine-Tuning
コンテキスト情報は多ければ多いほど良いのか?

- 言語モデルにより多くの情報を提供することで、下流のタスクの実行を助ける可能性がありますが、モデルが推論しなければならないコンテンツの量も増加させ、精度が低下する可能性がある
- 言語モデルにより長い入力コンテキストを提示することが常に有益とは限らない
- retrieveのリコールと正解率を入力コンテキストの文書数に対してプロット
- リーダーモデルのパフォーマンスはリトリーバーのパフォーマンスが飽和する前に飽和しており、リーダーが追加のコンテキストを効果的に利用できていない
- retrieverによって返された関連文書の効果的なリランキングや、適切な場合には検索結果の切り捨てなどが、言語モデルベースのリーダーがリretrieveしたコンテキストをより良く利用するためには良い