
2024-08-15 機械学習勉強会
今週のTOPIC[論文] JaColBERTv2.5: Optimising Multi-Vector Retrievers to Create State-of-the-Art Japanese Retrievers with Constrained Resources[blog] 今だからこそ、Sansanで挑戦するデータ活用の最前線[blog] Improving Retrieval on Ramp with Transaction Embeddings[論文] Training object class detectors with click supervision[blog] A Visual Guide to Quantization[blog] 運転版の"Sora"を作る: 動画生成の世界モデルTerraの開発背景[論文] Robustness of Structured Data Extraction from In-plane Rotated Documents using Multi-Modal Large Language Models (LLM) (arXiv)[論文] Visual Data-Type Understanding does not emerge from scaling Vision-Language Models(ICLR2024)[論文]Frequency Masking for Universal Deepfake Detection[blog]「AIサイエンティスト」: AIが自ら研究する時代へ[論文]Long-CLIP: Unlocking the Long-Text Capability of CLIP [ECCV24]Majority or Minority: Data Imbalance Learning Method for Named Entity Recognition(Practical ML for Low Resource Settings@ICLR2024)概要データの不均衡問題データの不均衡問題とは一般的な解決策固有表現認識(Named Entity Recognition)におけるデータの不均衡問題提案手法MoM(Majority or Minority) Loss実験設定結果考察結論
今週のTOPIC
※ [論文] [blog] など何に関するTOPICなのかパッと見で分かるようにしましょう。
出典を埋め込みURLにしましょう。
@Naoto Shimakoshi
[論文] JaColBERTv2.5: Optimising Multi-Vector Retrievers to Create State-of-the-Art Japanese Retrievers with Constrained Resources
概要
- ニューラル情報検索では、日本語のような低リソースな言語だとデータ不足などの理由によって発展が妨げられてきており、その結果、計算効率が悪く言語のニュアンスを捉えられないにも関わらず、多言語モデルが日本語検索を支配してきた。
- 低リソース環境におけるマルチベクトル検索器の学習方法について、日本語に焦点を当てて取り組む。
- JaColBERTv2.5は、わずか1億1,000万のパラメータを持ち、4つのA100 GPUで15時間未満で学習され、すべての一般的なベンチマークにおいて、すべての既存手法を大幅に上回り、平均スコアは0.754に達し、これまでの最高である0.720を大幅に上回った。
背景
- 英語の場合、多言語モデルよりも単言語モデルの方が一貫して強い。
- 日本語の場合、単言語モデルは多言語モデルから平均40%の性能低下を示すことが多く、大規模なベンチマークではさらに顕著な劣化を示す。
手法
- ColBERT
- 各文書に対して単一のベクトルを作成することは情報損失になっているのでマルチベクトルを用いる。
- Query Augmentation:クエリは基本的に文書に比べて短いので、Paddingを行う。この際、[PAD]でpaddingするのではなく[MASK]でpaddingした方が良い。
- マスクトークンの正確な影響や、それを使用する最良の方法は、十分に研究されていないらしい。単純に8個つけたり、除去したりなど様々な研究がある。
- MaxSim:クエリのすべてのベクトルとDocumentのすべてのベクトルとのcos類似度を計算し、各クエリに対する最も類似度の高いDocumentのベクトルの類似度を計算した上で、クエリに対してsumを取る。

- ColBERTV2
- in-batch negativeやknowledge distillationを導入
- トークン表現をクラスタリングしてベクトルを2bitに圧縮し、6倍のインデックスサイズ削減
- JaColBERT, JaColBERTv2
- ColBERTとColBERTv2を日本語に適用したが、まだ大規模な検索データセットでは多言語検索モデルには負けている
実験
- Kaggle的に様々なアプローチを系統的に評価
- 訓練データ
- MS Marcoを機械翻訳した大規模なIRデータセットであるMMarcoを利用
- 1 queryに対して、32 documentを引っ張ってくるtriplet lossで学習
- その他データ削減など
- Baselines
- SoTAの多言語モデルであるBGE-M3との比較 (JaColBERTの5.11倍)
- LUKEベースのGLuCoSEや名古屋大学のSUP-SIMCSEなども
- Dynamic Query Length
- [MASK]パディングを実行する前に、最大クエリ長を32の最も近い倍数(ColB ERTの元の最大クエリ長)に設定すること。
- Dynamic Query Lengthが一番いい

- 訓練設定
- In-Batch Negative
- バッチ内の他のクエリの正例を負例として扱うこと
- 英語以外のデータ制約のある環境では不要ではないかと仮説を立てた。
- データセット作成時に32個の負例をサンプリングしているので、そちらの負例のシグナルの方が重要
- Scheduler
- Annealingなどを行う場合に最適なステップ数を探すのは計算効率を考えると大変。
- スケジュールフリーな手法を試した
- 知識蒸留のロス
- maxsimの出力が生徒モデルのスコアとして使用される。
- 上記は0以上の値であるが、logitで学習させると負の数も含むので正規化 (min-max-normalize)
- loss
- MarginMSEとKL-Divergenceの二つを試した
- 結果


- その他教師モデルをどうするのか、checkpoint平均化などのなどの実験も
- 最終的な設定


@Yuya Matsumura
[blog] 今だからこそ、Sansanで挑戦するデータ活用の最前線
- Sansanさんでのデータに関連する取り組み
- 4つの技術テーマの整理、良いなと思った。
- データ化する:アナログな情報をデジタルデータに変換する
- 内製Vision & Languageモデル(Viola)のデモが今年のMIRUであったらしい。
- データを集める:多様なソースからデータを効率的に集約する
- グローバル!
- データをつなぐ:異なるデータセット間のデータを関連付ける(名寄せする)
- 高度なマッチングアルゴリズム:高度なマッチングアルゴリズムを導入し、異なるデータソース間での正確なマッチングを実現します。
- 正規化技術の開発:異なる表記やスペルミス、略称などを正規化することで、同一企業・組織・住所などを正確に特定します。
- 企業データの更新:企業データが日々変化する中で、常に最新の情報を提供できるようにするために、データの更新を行っています。これにより、企業の新規設立、合併、廃止、拠点増設などの情報を迅速に反映します。
- データを活用する:収集・連携されたデータの効果的な利用を実現して促進する
@Tomoaki Kitaoka
[blog] Improving Retrieval on Ramp with Transaction Embeddings
- 会計コードの分類という難題
- 会計コードの分類とは各企業のERPで定義されたコードに基づいて取引を分類するプロセスだが、これは金融に詳しくない従業員にとって混乱を招く難しい作業
- 実際に決済を行った従業員は取引のコンテキストの情報は十分にあるが、会計知識やポリシーに関する知識は不十分である。一方で経理担当者はポリシーや会計知識はあるが取引のコンテキストまでは把握できていない。
- → 類似した取引データをグループ化し、それらの取引を意味的に検索する方法を模索することで、類似した取引に付随する会計コードを基に新しい取引に対してGLカテゴリを予測できることを目指した。

- アプローチ
- 取引データをクラスタリングし、新たな取引に対して適切なGLカテゴリを予測するために、トリプレットロス関数を使用してモデルをトレーニングした。トリプレットロス関数は、トリプレットトレーニングサンプルを通じて、embeddingモデルに潜在空間を学習させる手法。
- 具体的には、トランザクションをアカウントコード(勘定科目コード)のラベルが付与された文書として表現し、トレーニングデータセットは各GLカテゴリに関連付けられた3つの文書で構成されたトリプレットサンプルによって作成した。
- トリプレットロスを活用することで、モデルは類似した文書と非類似な文書の違いを効果的に学習し、それぞれのGLカテゴリに基づいて取引をクラスタリングする能力を獲得できる。このアプローチにより、新しい取引に対しても、類似性に基づいて正確にGLカテゴリを予測することが可能となる。

- モデルアーキテクチャ
- モデルは埋め込みモデルのトレーニングと高密度ベクトルテキスト表現の計算に広く用いられているPythonライブラリ「sentence transformers」を使用。まず、事前にトレーニングされたエンコーダをベースモデルとして採用し、それをRampの取引データに対してトリプレットロスを用いてファインチューニングした。
- 学習された潜在空間において、2つの取引間の類似性を定量化するために、距離計量としてコサイン類似度を使用して取引間の関係性を効果的に把握し、GLカテゴリの予測精度を向上させた。
- 多くのembeddingモデルやモデルをトレーニングするためのさまざまなアプローチが存在する中で、Ramp上の多様な取引に対応できるスケーラブルなアーキテクチャを選択した。また、これらの取引に対する検索は、後続のアプリケーションに迅速に応答できる必要があるため、クイックリトリーバルを実現できるより小さな埋め込みサイズを選択した。

- トリプレットロス
- トリプレットロスは、アンカー、ポジティブサンプル、およびネガティブサンプルからなる三つの組を用いて学習を行う手法です。
- アンカー: 特定のラベルが付与された文書。
- ポジティブサンプル: アンカーと同一のラベルを持つ文書。
- ネガティブサンプル: アンカーとは異なるラベルを持つ文書。
- 例
- 「7000 個人経費」というGLアカウントでラベル付けされたアンカー文書を考えます。この場合、ポジティブサンプルも同じ「7000 個人経費」というラベルを持ち、一方でネガティブサンプルは「6300 光熱費」といった異なるラベルを持つ可能性があります。
- トリプレットロスは、アンカーとポジティブサンプルの類似性を強調し、同時にアンカーとネガティブサンプルの違いを明確にするようにモデルを訓練します。具体的には、アンカーとポジティブサンプル間の距離を最小化し、アンカーとネガティブサンプル間の距離をマージンと呼ばれるハイパーパラメータによって最大化するようにembeddingを調整します。これにより、ネガティブサンプルをアンカーから遠ざけ、ポジティブサンプルをアンカーに引き寄せることが可能となります。
- コントラストロスとの比較
- コントラストロスも類似性をモデル化するための代表的な損失関数ですが、ペア単位でデータを処理します。コントラストロスでは、各ペアに対してポジティブまたはネガティブのラベルが付与され、ポジティブなペアは近づけ、ネガティブなペアは指定されたマージンで距離を取らせることを目的としています。
- トリプレットロスとコントラストロスの主な違いは、マージンの扱い方にあります。コントラストロスは、ポジティブペアの評価時にマージンを考慮しないため、ベクトル空間内でのクラスタリングが十分に行われず、ポジティブとネガティブのペアを区別することには成功するものの、クラス内の細かなクラスタリングには適していません。
- この違いは、コントラストロスとトリプレットロスによって生成された埋め込みを比較することで明確になります。トリプレットロスは、より多様なクラスタリングを可能にし、クラス内のばらつきに対しても耐性を持たせることができます。
- トリプレットロス実装の課題と戦略
- トリプレットロスを実装する際の主要な課題の一つは、効果的なトリプレットサンプルのマイニングです。ランダムにトリプレットを選択すると、「旅行」と「修理・保守」などの区別が容易なカテゴリ間の違いはすぐに学習されてしまい、学習プロセスが停滞しやすくなります。
- しかし、「旅行: 営業」と「旅行: 技術」といった、より微細なカテゴリ間の違いを学習することは、会計において極めて重要です。これを実現するには、「ハード」または「インフォーマティブ」なトリプレットを重点的にサンプリングする高度な戦略が求められます。


- embeddingの前処理
- モデルのトレーニングに先立ち、取引データをどのように文字列として表現し、その後embeddingに変換するかを理解する必要がありました。そこで、取引データをコンテキストに基づいて強化し、取引の会計分類に最も関連する特徴を組み合わせた「コンテキスト取引」として表現しました。これらの特徴には、以下のものが含まれます。
- Merchant name
- Merchant category name (MCC): 取引の一般的な「カテゴリ」を表します。
- Department name
- Location name
- Amount
- Memo
- Spend program name: この取引に割り当てられた特定の支出制限を表します。
- Trip name: 取引が旅行中に行われた場合、その旅行を表します。
- これらの情報以外にも、取引データをさらに豊富にすることは可能ですが、埋め込みが汎用性を持つようにする必要がありました。具体的には、すべてのRampの顧客が持っているわけではない特徴で取引を強化しないようにすることで、これらの埋め込みがあらゆる規模や業界のRamp利用企業にとって関連性のあるものになるようにしました。また、汎用的な取引の埋め込みを持つことで、外部の取引や他のユースケース(例えば、ERPから同期されたRamp以外の取引のコーディング)にも対応できるようになります。
- 最終的に、これらの埋め込みのラベルは対応するGLカテゴリであり、各取引に割り当てられた会計コードを表しています。これらの特徴とラベルを使用して、取引をカスタム埋め込みモデルに入力するための文字列化されたプロンプトとして表現し、クエリ取引をすでにコーディングされた類似の取引と照合することが可能となりました。

取引データの埋め込み表現の前処理
- 最終的な画面


@Shun Ito
[論文] Training object class detectors with click supervision

- CVPR2017
- 1クリックだけのbboxアノテーション手法
- 物体の中心をクリック
- クリック位置を元に、物体を囲むbboxを推定
- Multiple Instance Learning (MIL)
- 物体検出の弱教師あり学習手法
- ある物体が含まれている (positive) 画像と含まれていない (negative) 画像を同時に入力
- それぞれの入力画像にEdge-Boxesを適用し、オブジェクトらしい部分集合 (proposal) に分割
- (re-localization) positive 内の proposal を分類モデルに入力し、一番スコアの高いものを選ぶ
- (re-training) 一番スコアの高いものを正例、それ以外(negativeのproposalは全て)を負例として分類モデルを再学習
- re-localizationとre-trainingを繰り返す

- クリックの組み込み
- クリックした位置に対して、Box Center Score を計算
- re-localizationの部分で、分類モデルのスコアにBox Center Scoreを掛け合わせる
- 最終的なbboxはFast R-CNNで予測
- MILの学習は、クラウドソーシングで集めたクリックデータを使う

- 2人分のクリックを利用する手法もある
- 実験結果

- test 4952枚
- drawingと同等の精度をより短い時間でアノテーションできる
@qluto (Ryosuke Fukazawa)
[blog] A Visual Guide to Quantization
数値表現のためのコンピュータサイエンス基礎から、量子化の方法について図解。
量子化は、通常、32ビット浮動小数点(FP32)で表現されるパラメータを、16ビット(FP16)や8ビット整数(INT8)に変換することでメモリ効率を向上させるもの。これにより、計算速度が向上し、メモリ使用量が大幅に減少しますが、精度の低下や量子化誤差が発生する可能性がある。
そういった問題に対応するために、対称量子化や非対称量子化、外れ値に対応する手法があり、それぞれ異なる方法で数値をマッピングする。
Post-Training Quantization(学習後に量子化を行う)の代表的な手法としてGPTQ、GGUFを取り上げ、Quantization Aware Training(学習・ファインチューニング中に量子化を行う)の新進気鋭な手法として1bit量子化であるBitNetを取り上げている。
@Yosuke Yoshida
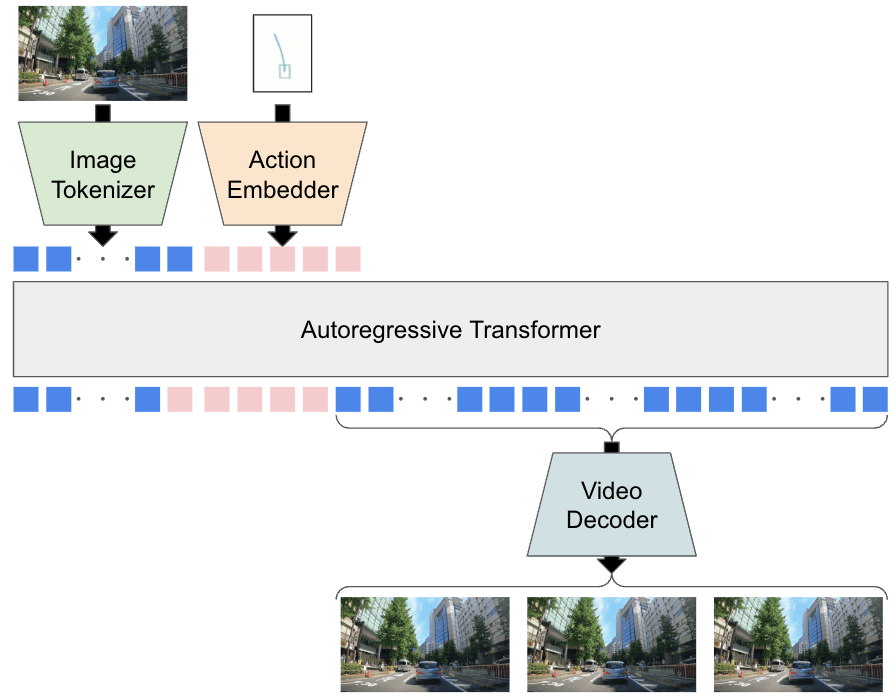
[blog] 運転版の"Sora"を作る: 動画生成の世界モデルTerraの開発背景
- Turing社が開発している動画生成モデルTerra
- Terraができることは2つ
- video rollout
- 最初の10フレーム(赤枠がついているフレーム)を入れて続く45フレームを生成
- action-conditioned generation
- 短い動画とそのあとになぞって欲しい軌跡(trajectory)を与えて、その軌跡に沿って進んだ場合の動画を生成



- Terraのアーキテクチャ
- Image Tokenizer
- 画像フレームを離散トークンに変える
- Lookup Free Quantization(LFQ)
- トークンの語彙数が262,144と桁違いに多く非常に高い表現力
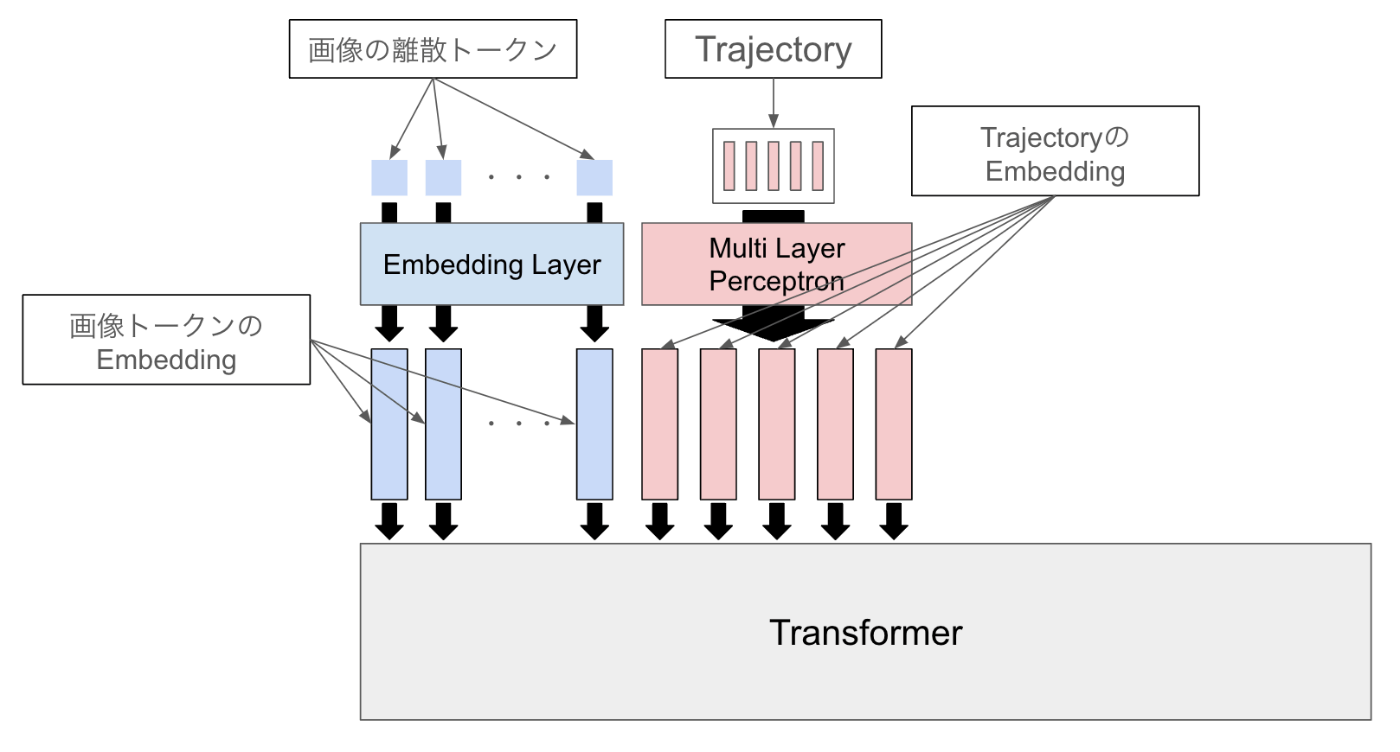
- World Model
- 画像フレーム列を離散化したトークン列と条件付けのトークン列を受け取り、未来の画像トークン列を予測する
- 一つのtrajectoryを3次元のベクトル(x, y, 時刻t)が5つ連なっているデータ構造と定義し、それぞれのベクトルをprojectorでトランスフォーマーの入力の次元に変換した上で一つずつトークンとして入力
- 学習
- Next Token Prediction
- 損失はCross Entropy Error
- Trajectoryトークンの部分は損失計算を行わず、画像トークンの予測に対してのみ損失計算
- 推論
- 自己回帰的に画像トークンを予測
- 1フレーム分の画像トークンは576にしているため、576回分の推論で1フレーム分が生成
- 1フレーム分生成が行われた後は、Trajectoryトークンを挿入した上で次のフレームの画像トークンの生成を自己回帰的に行う
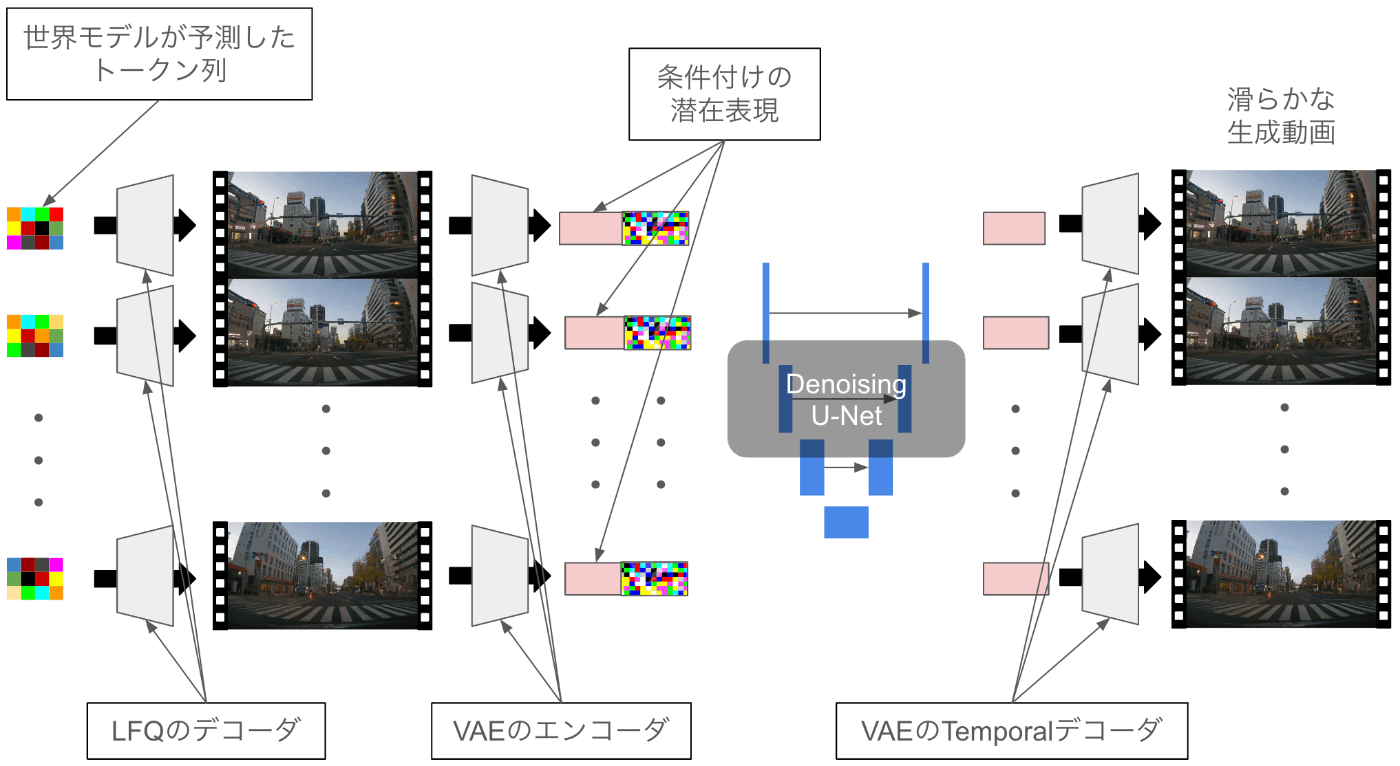
- Video Decoder
- 予測された未来の画像トークン列を入力してフレーム列を出力
- LFQは画像のトークナイザーのためデコードするとちらつきが多く低品質
- LFQのデコーダ
- 動画対応のデコーダを用いた場合
- 動画に対応したdecoderは例えば、Stable Video Diffusionなどで使われているTemporal Decoderが挙げられますが、これは離散値の潜在表現には非対応
- Stable Video Diffusion(SVD)をファインチューンし、画像のトークナイザのデコーダでデコードした画像を時系列的に滑らかに接続するようなモデルを作成


@Ryuhei Kawabata
[論文] Robustness of Structured Data Extraction from In-plane Rotated Documents using Multi-Modal Large Language Models (LLM) (arXiv)
- マルチモーダル大規模言語モデル(LLM)が傾いた文書からデータを抽出する際のロバスト性を評価
- 5°, 10°, 15°, …, 355° に文書を回転させ性能評価
- 傾きの異なる合成文書を用いて、LLMのデータ抽出精度をテストし、傾きによる影響を定量化
- 使用した指標: レーベンシュタイン距離
- 使用したモデル: GPT-4, Claude V3, and Llava



- 安全な回転角度(SIPRA)をモデルごとに特定
- Claude V3 Sonnet(青) の方が GPT-4-Turbo(緑) より性能良い体感があるが、 傾きに対する頑健性でいくとGPT-4-Turbo の方がよさそう?

[論文] Visual Data-Type Understanding does not emerge from scaling Vision-Language Models(ICLR2024)
Abstract




@Shuitsu Koyama
[論文]Frequency Masking for Universal Deepfake Detection
概要
- 周波数に注目してマスキングするData Augmentation
- ディープフェイク検出モデルの汎化に使える
提案
(a) 実空間におけるマスキング
(1) pixel masking
1ピクセル単位でランダムにマスキング
(2) patch masking
p*pの正方領域をランダムにマスキング
(b) 周波数空間におけるマスキング
FFTして特定の周波数範囲を(今回はlow,mid,high,all)ランダムにマスキング, つまり強度を0にする.

実験比較
ディープフェイクの検知

フェイク検知のSoTAのモデルにこの手法を適応すると以下の結果が得られた

関連を調べていると以下のような論文もあり, 周波数は生成画像検知において重要だと示唆されていることがよくわかる。
GANによる生成画像の周波数特徴

余談
aiが論文を書ける時代到来?
@NishimuraTakayuki
[blog]「AIサイエンティスト」: AIが自ら研究する時代へ
- そして今回は、「LLMを使って、研究開発プロセスならではの自動化する」という革新的な技術を開発しました。ブリティッシュ・コロンビア大学との共同研究により、「The AI Scientist: Towards Fully Automated Open-Ended Scientific Discovery」という論文にまとめてソース公開しました。コードもオープンソース化しています。
AIサイエンティストは、アイデア創造、実験の実行と結果の要約、論文の執筆及びピアレビューといった科学研究のサイクルを自動的に遂行する新たなAIシステムです。
- diffusionに関する論文を執筆
- caution this paper was autonomously generatedが透かされている、、

@NagashimaShunya
[論文]Long-CLIP: Unlocking the Long-Text Capability of CLIP [ECCV24]
- 著者: Beichen Zhang1,2, Pan Zhang1, Xiaoyi Dong1,3, Yuhang Zang1, Jiaqi Wang1
- 所属: 1Shanghai AI Laboratory, 2Shanghai Jiao Tong University, 3The Chinese University of Hong Kong
- CLIP(Contrastive Language-Image Pre-training) [Radford+, ICML21]
- CLIP は、画像とテキストのペアを用いて、それぞれのモダリティを接地させる視覚言語基盤モデル
- 主にゼロショット分類、テキスト-画像検索、テキスト-画像生成のタスクで使用され、画像と言語の理解を統合する強力な手法
- CLIPの問題点
- CLIPは、77トークンに制限された絶対位置埋め込みを採用
- CLIPのテキストエンコーダの実際の有効長は20トークン未満であり、詳細な説明文を扱うことができない

- 提案手法Long-CLIP
- 以下2つの新規性により、長文のテキスト入力が可能に
- 位置埋め込みの知識保持を考慮した拡張
- 主成分マッチング
- Long textを用いたfine-grainedな言語特徴とfine-grained視覚特徴のalignment
- Short textを用いたCoarse-grainedな言語特長とcoarse-grained視覚特徴のalignment


- 結果
- Long-CLIPは、短文のテキスト-画像検索タスクにおいても性能を維持しつつ長文のテキスト入力に対して大幅な改善
- ゼロショット分類タスクにおいても、従来のCLIPと同等の性能を維持

- 結論
- Long-CLIPは、テキスト入力を248トークンまでサポート
- 詳細な属性をより効果的に捉えることで、画像検索やテキストからの画像生成タスクにおいて大幅な改善
- 今後は、より多くのデータを使用してモデルをスケールアップすることによる更なる性能向上
Majority or Minority: Data Imbalance Learning Method for Named Entity Recognition(Practical ML for Low Resource Settings@ICLR2024)
概要
- 固有表現認識(NER)におけるデータの不均衡問題に関する論文
- 固有表現クラス間の不均衡というよりも固有表現クラスとその他(Others)クラスに焦点を当て、固有表現クラスがOthersクラスと誤認識されないように学習する手法
データの不均衡問題
データの不均衡問題とは
- 機械学習において、データセットの分布が偏っていること
- データの不均衡には以下の2パターンが考えられる
- クラスの不均衡
- 例1. 不正検知
- 多数の「正常」クラスと少数の「不正」クラス
- 例2. 医療診断
- 多数の「健康」クラスと少数の「疾患」クラス
- 問題点
- モデルが多数クラスに偏って学習
- 少数クラスが重要なのに、少数クラスの予測精度が低下
- 性質の不均衡
- 例1. 顔認識
- 学習データのほとんどが特定の人種や年齢層に偏っている
- 例2. AI-OCR
- 学習データのほとんどが同じようなフォーマット
- 学習データのほとんどが日本語
- 問題点
- 特定の性質を持ったデータに対する認識精度が低下
- 請求書ばかりで学習してたら、領収書は苦手になったり
- 場合によってはシステムとしての公平性が下がったり偏見が助長されたり
一般的な解決策
- オーバー・アンダーサンプリング
- 少数クラスはたくさんサンプリング、多数クラスは少なめにサンプリング
- cost sensitive learning
- コストを定義して、そのコストを用いて仮説を得る手法
- 損失関数の重み付け
- 少数クラスの誤分類コストを定義し、少数クラスの重みを大きく、多数クラスの重みを小さく
- focal loss
- 物体検出タスクにおいて、背景と前景の不均衡性に着目
- dice loss
- 評価指標のF1スコアに近いダイス係数を使うことで間接的に不均衡性に対処
固有表現認識(Named Entity Recognition)におけるデータの不均衡問題
- 固有表現認識(NER)とは
- 定義: テキスト中の固有表現(名前付きエンティティ)を認識し分類するタスク
- テキストという系列に逐次ラベルをつける系列ラベリングタスク
- 固有表現の例: 人名、組織名、地名、日付、時間、金額など
- NERにおけるデータの不均衡問題
- NERタスクに用いるデータセットにおいて、固有表現クラスに比べOthers(その他)クラスが圧倒的に多数であることがしばしば
- 見逃しコストの高い少数の固有表現クラスを見逃してしまう傾向がある
- NERにデータ不均衡問題への一般的な解決策を適用する際の問題点
- ある一つのサンプルに複数のクラスラベルがついているので、オーバー・アンダーサンプリングや、損失関数の重み付けをサンプルごとに行うことができない
- focal lossやdice lossは2クラス分類には適用可能だが、マルチクラス分類には適用が困難
提案手法
- NERタスクにおけるデータの不均衡問題のための損失関数であるMoM(Majority or Minority) Lossを提案
- MoM lossは元の損失関数に多数クラス(Others)を対象とする損失を追加するだけというシンプルかつ汎用的な手法
- 既存手法は全体に対する少数クラスの比重をあげることで不均衡問題に対処していたが、提案手法は多数クラスに関する損失を追加するということで、既存手法と比べて直感的ではない印象
- 提案手法の狙いとしては、少数クラスから多数クラスへの誤認識によるPrecisionの低下を防ぐこと
- 少数クラスに着目した場合(既存手法)、少数クラスから少数クラスの誤認識と少数クラスから多数クラスへの誤認識を区別することができない
- これはデータの不均衡問題への対策としては厳密ではない
- 多数クラスに着目し、多数クラスなのか少数クラスなのかに特化した損失を追加することでデータの不均衡問題に対処
MoM(Majority or Minority) Loss
- 元々の損失関数に多数(Others)クラスに着目した損失関数を追加するというシンプルで汎用的な損失関数
- 実装 w/ Claude 3.5 Sonnet(texのsourceから95%くらい自動で書いてくれた)
(1) 多数クラス(Others)に着目した損失
- の部分は今回はクロスエントロピーだがなんでもいい
- 実装上は元々の関数から多数クラスだけマスクして計算
(2) 全体の損失は、元々の損失とMoM Lossの加重平均
- はハイパラ
(3) データセット全体を、予測確率をとし、全体の損失を最小化
実験
設定
- タスク
- 固有表現認識(NER)
- 機械読解(MRC)
- モデル
- BERT
- データセット
- 英語:CoNLL2003, OntoNotes5.0
- 日本語:KWDLC, NER wiki
- 比較対象
- Weighted Cross Entropy(WCE-1, WCE-2)
- Focal Loss(FL)
- Dice Loss(DL)
以上の設定でそれぞれ10個のランダムシードの結果の平均に基づいて評価
結果
- NERタスクの結果
- 全てのデータセットで提案手法が一番良かった
- 次点のFocal Lossと比較して、統計的に有意な改善
- WCEは意外と性能が低下

- NERタスクにおける固有表現別の結果
- 提案手法を用いることで固有表現の性能が改善した

- MRCタスクの結果
- 提案手法が一番良かった
- 次点のDice Lossと比較して、統計的に有意な改善

考察
- NERにおける評価指標の重要性
- NERではよく全体のスコアが報告されるが固有表現クラスの性能が特に重要
- 提案手法によって、多数(Others)クラスの性能は維持しつつ固有表現クラスの性能が上がった
- 提案手法の効果
- MRCタスクにおいて顕著な改善
- 固有表現の境界部分の検出に有効
- 言語ドメインに依存性しない
- 英語のデータセットでも日本語のデータセットでも精度が改善した
結論
- 提案手法
- シンプルかつ効果的
- タスクや言語に非依存
- 固有表現クラスの性能向上に特化
- NERタスクの実用的な課題に対応