
2025-05-12 機械学習勉強会
Title by AI
エージェント推論とツール統合による強化学習を用いた大規模言語モデルの未来
Tags
論文
AI summary
強化学習を用いた新しいフレームワークARTISTを提案し、LLMが外部ツールと動的に相互作用しながら複雑なタスクを自律的に計画・解決する能力を示した。GRPOによる学習で、エージェント推論とツール統合の新しい能力を引き出すことが可能となる。
担当者
 Naoto Shimakoshi
Naoto Shimakoshi今週のTOPIC
Title
Agentic Reasoning and Tool Integration for LLMs via Reinforcement Learning
今週のTOPIC[blog] Group Relative Policy Optimization (GRPO) Illustrated Breakdown[論文] Dated Data: Tracing Knowledge Cutoffs in Large Language Models[論文] ZEROSEARCH: Incentivize the Search Capability of LLMs without Searching[blog] 日本語VLM「Heron-NVILA」公開 ─ Qwen2.5-VL-7B・Gemma3-12Bに匹敵する性能[slide] ここはMCPの夜明けまえ[Survey論文] A Survey of Automatic Prompt Engineering: An Optimization PerspectiveメインTOPICAgentic Reasoning and Tool Integration for LLMs via Reinforcement Learning概要IntroductionARTIST OverviewCase StudyComplex Mathematical ReasoningMulti-Turn Function CallingExperimental SetupComplex Math DatasetMulti turn Dataset結果Complex Math DatasetMulti turn Dataset結論
今週のTOPIC
@Naoto Shimakoshi
[blog] Group Relative Policy Optimization (GRPO) Illustrated Breakdown
- 改めてPPOとGRPOの違いについての復習にちょうどいい記事

- Value Networkが無くなったよね、とかは端的に分かるけど実際生成させているときにどのように計算しているのかまで追えてなかった。

@Shun Ito
[論文] Dated Data: Tracing Knowledge Cutoffs in Large Language Models
- COLM2024
- 「yyyy年mm月 (cutoff) までのデータ」で学習されたLLMが、実際のどの時期の情報に最も適合しているかを調査
- 評価
- データセット: wikipediaの月毎のバージョン履歴(WIKISPAN)
- バージョンごとにperplexityを計算。低いほどその情報に “驚かない” = 適合しているとみなす
- 結果
- RedPajamasの結果
- 本来は図の右端がcutoff
- 2019年4月あたりがもっともperplexityが低くなっている
- 要因
- 学習データには最新データも含まれてはいるが、古いバージョンのデータも一定含まれている。それらのボリュームが大きいところに適合していそう
- 学習データがどの時期のデータかは、WIKISPANのどのバージョンに最も近いかで判断
- 学習時の重複除去 (deduplication) で、中身は全く同じだが表現が微妙に異なるものを排除しきれておらず、古いデータの影響を受けてしまっている

@qluto (Ryosuke Fukazawa)
[論文] ZEROSEARCH: Incentivize the Search Capability of LLMs without Searching
Hao Sun, Zile Qiao†, Jiayan Guo†, Xuanbo Fan, Yingyan Hou
Yong Jiang, Pengjun Xie, Fei Huang Yan Zhang†, Tongyi Lab, Alibaba Group
Search-R1のようにLLMに検索エンジンを活用する能力を獲得させるための強化学習においては外部検索エンジンへの依存がコスト面・品質面で課題になる。
その課題を解決すべく、実際の検索エンジンに依存せず検索能力を獲得させた。先行研究であるSearch-R1の手法でGoogle API連携によって学習させた時より高い精度が得られた。
- 検索エンジンの代わりにLLMを使う
- 軽量なSFT(Supervised Fine-Tuning)で、LLMに検索結果のような文書を生成させる。
- 「正解につながる文書」と「ノイズ文書」の両方を作れるように訓練。
- カリキュラム学習によるロールアウト
- 初期は質の高い文書を与え、徐々にノイズを増やして難易度を上げる。
- モデルの推論能力を徐々に引き出す設計。
- 構造化された出力テンプレート
<think>で推論、<search>で検索、<answer>で答える。- 明示的に思考→検索→回答のプロセスを辿らせる。
比較対象
- CoT、RAG、Search-R1(実検索エンジンと連携)、RA-Agentなどの既存手法。
- 使用モデル:Qwen-2.5(3B/7B)、LLaMA-3.2(3B)など。
主な結果
- ZEROSEARCHはSearch-R1(Google連携)よりも精度が高い。
- 7BのLLMでGoogleと同等、14BでGoogleを上回る性能。
- ベースモデルでも学習が進めばInstructモデルに匹敵。
- APIコストよりもLLMに検索結果をシミュレートさせる方が安くついた

@Yosuke Yoshida
[blog] 日本語VLM「Heron-NVILA」公開 ─ Qwen2.5-VL-7B・Gemma3-12Bに匹敵する性能
モデルアーキテクチャ
- NVIDIAが提案したVLMであるNVILA
- https://arxiv.org/abs/2412.04468
- 論文では、元の画像サイズに加えて (448, 448)、(896, 896)、(1344, 1344) にリサイズした画像でもScale処理を行うマルチスケール対応の
Dynamic-S2が紹介されていますが、Heron-NVILAではこのマルチスケール化を行わないLite方式を採用 - Liteの方がわずかな性能低下はありますが、マルチスケール対応は学習・推論時間が増加するため実用性を重視してLiteを選択
- Heron-NVILAのVision EncoderとLLMは公式リポジトリで使用している以下のモデルを採用
- Vision Encoder: paligemma-siglip-so400m-patch14-448
- LLM:Qwen2.5シリーズ
- 日本語特化のLlama-3.1-Swallow-8Bを用いて少ないステップ数での学習を試しましたが、Heron Benchにおける評価スコアがQwen2.5-7B-Instructを用いた方が高かったためQwen2.5を採用
- 公式のNVILA-Liteの重みは公開されていますが、ライセンスがCreative Commons Attribution-NonCommercial 4.0で商用利用が許可されていません。そのため、公式のNVILA-Liteの重みは使用せず、上記のVision EncoderとLLMから学習を行いました
- NVILAの論文では5ステージの学習(学習データや学習率を段階的に変更し、計5回の学習を実施)を採用していますが、5ステージ学習に対応する日本語データの確保が困難であったため、NVILAの前身であるVILAの3ステージ学習を採用
- データの工夫としては、Stage2のPretrainingにCommon Crawlの日本語データであるMOMIJIを追加した点
- 前処理
- テキスト長フィルタ:本文が 5,000 文字を超えるサンプルを除外
- 画像サイズフィルタ:縦・横いずれかが 10 px 未満、または 16,000 px を超える画像を持つデータを除外
- 画像挿入位置を変更:CLIP ViT-H/14で画像とテキストの類似度を計算し、類似度が最も高いテキストの直前に画像を配置
- H100インスタンス16ノードを使用し、2〜15ノードでマルチノード学習したが、学習ジョブがエラーログも残さず途中で停止
- 数百stepごとにcheckpointを保存
- ストレージ容量
- 画像件数が膨大であることから jpg/png で画像を保持するとinode(ファイル数)上限に達するため、一部の画像は tar/pkl に固めてファイル数を削減
- データだけで50TB程度ストレージ容量が必要
- データライセンス & 取得方法
- データセットは研究目的限定/商用不可のものも多く、画像は URL のみの提供で img2dataset などで自前クロールが必要
- VRAM要件
- マルチ画像入力により VRAM 消費が増大するバッチも発生
- ノード追加・マイクロバッチサイズ削減などで調整
- 学習の安定化
- 画像とテキストの不整合などが原因で発生したと推定される loss spike や 極端に長いテキスト、超高解像度画像を伴うサンプルによって OOM が発生
- 学習中で問題発生 → 問題とおぼしきデータを確認・除去 → 学習やり直し を繰り返す
学習

データ
苦労した点
@Takumi Iida (frkake)
[slide] ここはMCPの夜明けまえ
| スライド | https://speakerdeck.com/nwiizo/kokohamcpnoye-ming-kemae |
|---|---|
| 補足資料 | https://syu-m-5151.hatenablog.com/entry/2025/04/24/113500 |
| 発表動画 | https://www.youtube.com/live/Lp-K-VUriDw?si=GQUrznhZOp-6A-3G&t=1507 |
MCPの概要を解説した発表資料
MCPサーバは以下のものでなりたってる。
ローカルで動かすことも範囲に入れたサーバなことに注意。

今後クライアント側で実装されていくだろう機能についても紹介されていた。
Sampling
サーバーがLLMに補完を要求できる機能です。クラスチートを行うことなく、会話中にLLMの判断を活用できる仕組みを提供します。

Roots
サーバーの操作範囲を定義する機能です。クライアントがサーバーに対して関連リソースとその場所を伝える手段として機能します。
テンプレートや人間による監視などの設定をして、出力を調整し、Human-in-the-Loop的なことができ、エージェンティックなワークフローが構築できるらしい。

@ShibuiYusuke
[Survey論文] A Survey of Automatic Prompt Engineering: An Optimization Perspective
- プロンプトエンジニアリングを自動化する研究のSurvey論文。19ページと読みやすい文量。
- 対象はLLMとVLM。
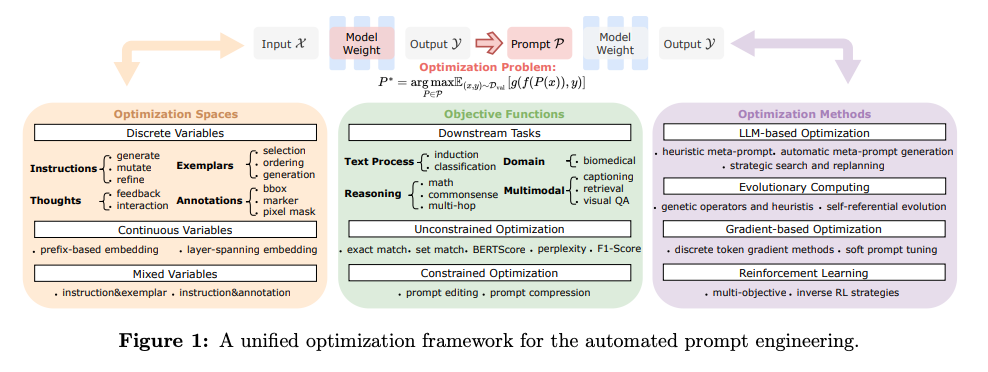
- 最適化空間
- Discrete:人間が理解可能な要素の探索。InstructionやFew-shot等。
- Continuous:学習可能な埋込ベクトル空間。入力表現に付加し、勾配ベースの手法で最適化。
- Hybrid/Mixed:上記の組み合わせ。Discreteの解釈性やドメイン、Continuousの柔軟性を両立。
- 実行するタスク

- 最適化手法
- FM-based optimization:基盤モデルをmeta-optimizerとしてプロンプトを改良。
- Heuristic Meta-Prompt
- Automatic Meta-Prompt Generation
- Strategic Search and Replanning:プロンプトの探索戦略をプロンプト最適化プロセスに組み込む。MCTSによる探索、失敗/成功のマルチブランチ戦略等々。
- Evolutionary computing:プロンプトを有機体とみなして、進化計算を通してsurvival of the fittestを進める。
- Genetic Operators and Heuristics
- Self-Referential Evolution
- Gradient-based optimization:離散トークンをナビゲーするために勾配を近似するか、ソフトプロンプトのコンテクストで連続パラメータを最適化。
- Discrete Token Gradient Methods
- Soft Prompt Tuning
- Reinforcement learning:プロンプトの設計を強化学習的問題として再構築する手法。
- Prompt Editing as RL Action
- Multi-Objective and Inverse RL Strategie

メインTOPIC
Agentic Reasoning and Tool Integration for LLMs via Reinforcement Learning
Joykirat Singh, Raghav Magazine, Yash Pandya, Akshay Nambi (Microsoft Research)
概要
- Microsoft Researchによる外部Toolも含めて強化学習するためのフレームワークARTISTの提案。最終結果のシグナルのみで、いつ、どのように、どのツールを呼び出すかを学習できる。
- 以前勉強会で紹介されたSearch-R1にちょっと似てる
- https://jobs.layerx.co.jp/1dccdd370bae80d8962dccc796a2ea72
- Geminiに生成させたまとめ

Introduction
- 既存のLLMは基本的に内部知識と言語モデリングに依存している。
Agentic Reasoningは、LLMが推論プロセスの際に外部リソースと環境の両方と動的に相互作用することでこれらの制限に対処する。
- 既存の手法は、手作業で作成されたプロンプトや固定ヒューリスティックに左右されるため、複雑なシナリオや未知のシナリオに一般化できない。
- Chain-of-thought
- 外部動作を必要とするタスクや正確な計算を必要とするタスクには不向き。
- Tool-Based Reasoning
- Web検索やコードインタプリタ、APIなどにアクセスすることで能力を拡張させる。
- PAL: 外部実行の際にコードを生成するためにプロンプトを使用。
- ART, ToLA: 推論のプロセスとしてツールを呼び出すように学習させる。
- ARTの場合は、exampleをいくつか準備しておいて、問題文をEmbeddingして似たタスクのexampleを数件ピックアップするなど。
- Toolformer: 自分でAPIをコールする場所を推論させて、そこでAPIをコールするといった自己教師あり的な学習手法
- これらの手法は高品質のラベル付きtrajectoryデータやヒューリスティックなプロンプトに依存していてスケーラビリティがない。
- ツールの使用は、訓練中に推論プロセスから頻繁に切り離されることが多い。
- RL-Based Reasoning
- PPO → DPO → SimPO → GRPOと発展してきた。
- また推論プロセスでツールを組み込むような学習をしている例もあるが、outcomeベースで学習させている例はない。
- R1-Searcher, ReSearch: QAタスクのためのRAGを強くするために検索ツールを組み込む。
- Retool: 数学問題を解くための外部ツールとしてコードインタプリタを活用。
- これらの手法はSFTで追加のアノテーションを必要とするタスク
- ARTIST(Agentic Reasoning and Tool Integration in Self-Improving Transformers)では、強化学習を用いて複雑な環境を相互作用するための最適な戦略を学習できるようにする。
- ツールのクエリとツールの出力を推論過程の最初の段階に組み込む。
- 以下の3つのセグメントを交互に行うようなプロンプトテンプレート
- テキストベースの思考:<think>タグ
- ツールクエリ:<tool_name>タグ
- ツールの出力:<output>タグ
- 学習はGRPOを用いたoutcomeベースの強化学習のみ

- 評価をcomplex mathmatical problemとmulti-turn fuction callingで行った。
- Qwen2.5-Instruct 7B, 14BモデルでARTISTを学習させ、GPT-4oやDeepSeek-R1、OSSのToolを用いたモデルであるToRAやNuminaMath-TIR、promptベースでのツール統合モデル、外部ツールを用いたベースラインモデルなどで比較。
- ARTISTは全てのベースラインを一貫して上回った。
- Agentic ReasoningにおけるRLや動的なツールの利用がLLMの能力のパラダイムシフトを起こすということを示した。
ARTIST Overview
- Methodology
- Reasoning, Tool use, Outputを繰り返して生成する。

- RL Algirithm
- DeepSeek-R1で利用されたGRPOを利用
- clipしているのは、PPOからあった破壊的な方策変更を防ぐため。
- はアドバンテージで、同じプロンプトで複数推論させた上での報酬を で計算しているだけ。
- KLダイバージェンスは元々のSFTモデルなどから逸脱しすぎないようにするための項
- Tool Integrationする際の工夫
- 決定論的なツール出力を模倣することを学習させたいので、損失計算中はツールの出力に関する部分のトークンにはマスキングを行う
- これによって生成されたトークンにのみ学習されるので、Agentの推論と意思決定に最適化を集中させることができる。
- 具体的なアルゴリズムは以下
- 実際には
<think> or <tool_name>なので、<think><think><think>と続くこともあり得そう? → 後段でFormat Rewardで抑制していた。 - Math Reasoning
- Multi-turn Function Calling

実際のプロンプトテンプレート
You are a helpful assistant that can solve complex math problems step
by step with the help of a python executor tool . Given a question ,
you need to first think about the reasoning process in the mind
and then provide the answer . During thinking , you can write python
code , and invoke python tool to execute the code and get back the
output of the code . The reasoning process and answer are enclosed
within < think > and < answer > tags respectively ,
and the python code and the output are enclosed within < python >
and < output > tags respectively . You can
utilize the Sympy library to write the python code and make sure
to print the result at the end of the python code . You can utilize
the python tool as many times as required , however each python
code will be executed separately . For example , < think > reasoning
process here < python > python code here < output >
output of python code here < think > reasoning process
here < answer > final answer here .
You are an expert in composing functions . You are given a question
from a user and a set of possible functions . Based on the question
, you will need to make one or more function / tool calls to achieve
the purpose . If none of the functions can be used , point it out .
If the given question lacks the parameters required by the
function , also point it out .
For each step :
1. Start with a step - by - step thinking process inside < reasoning > tags to think through the problem .
2. If needed , use tools by writing one or more JSON commands as a list
inside < tool > tags . Each item in the list should have a
name and args key , with args being a dictionary .
example : < tool > [ func_name1 ( params_name1 = params_value1 ,
params_name2 = params_value2 ...) , func_name2 ( params ) ]
Tools expect specific JSON input formats . Do not make up tools or
arguments that aren ’ t listed .
3. After you have used the tools , you will see the tool outputs inside
< tool_result > tags in the same order from the
system .
You SHOULD NOT include any other text in the response .
At each turn , you should try your best to complete the tasks requested
by the user within the current turn . Continue to output functions
to call until you have fulfilled the user ’ s request to the best
of your ability . Once you have no more functions to call , the
system will consider the current turn complete and proceed to the
next turn or task .
- 報酬設計
- outcomeベースのGRPOは効率的かつ効果的ではあるが、ARTISTの場合は、推論、ツールの使用などを確実に構造化する必要がある。
- Answer Reward
- モデルが正しい最終回答を生成した時に正の報酬を割り当てる
- Format Reward
- <think> → <tool_name> → <output> の順序がロールアウトの間保たれる
- Tool Execition Reward
- ツールの実行成功回数と総実行回数の比
Case Study
Complex Mathematical Reasoning
- 複素積分などの多段階の計算を必要とする複雑な問題で苦戦
- LLMをPythonのインタプリタで強化した。
- <python>タグでpythonの
sympyなどを実行できるように
- 報酬設計
| 報酬 | 目的 | 重み |
|---|---|---|
| Answer Reward | 最終回答の正誤 | +2 |
| Relaxed Format Reward | 4つの必要な要素が入ってるか <think><python><output><answer> | 一つ当たり0.125 |
| Strict Format Reward | 全てのtagが存在し、tagの開閉の順番が正しく、tag自体の順序が正しい | 0.5 |
| Tool Execition Reward | ツール実行成功率 (pythonがコンパイルエラーを起こすか) | 0〜1 |
Multi-Turn Function Calling
- 複数のFunction Callを使って、中間状態を管理し、ユーザと対話する必要のあるタスク
- <reasoning>tagでplanningなどを行う。
- 報酬設計
| 報酬 | 目的 | 重み |
|---|---|---|
| State Reward | 全状態数に対する正しい状態にいた数 | 0~SRで最大値は調整 (今回は0.5) |
| Function Reward | 期待される呼び出しと一致する数 (関数名と引数を一緒) | 0~FRで最大値は調整 (今回は0.5) |
| Relaxed Format Reward | 4つの必要な要素が入ってるか <reasoning><tool> | 一つ当たり0.025、max0.1 |
| Strict Format Reward | 全てのtagが存在し、tagの開閉の順番が正しく、tag自体の順序が正しい | 0.1 |
Experimental Setup
Complex Math Dataset
| データセット | 件数 | 構成・特徴 |
|---|---|---|
| NuminaMath | 20000 (train) | 初歩的な算術や代数から競技レベルの問題まで。trainにのみ利用 |
| MATH‑500 | 500 (eval) | 学生が数学的スキルを上げるためのリソース。基礎的な算数から高度な数学まで。 |
| AMC | 83 (eval) | 中〜上級高校レベル。 |
| AIME | 90 (eval) | AMC 上位者向け問題。 |
| Olympiad | 8476 (eval) | 多段階推論を必要とするオリンピックレベルの高難易度データセット |
- 評価指標はPass@1 Accで最終回答と一致しているものの割合。
- 実装
Qwen/Qwen2.5-7B-InstructとQwen/Qwen2.5-14B-Instruct- 6個のロールアウトを温度パラメータ1.0で生成
- 最大Responseの長さは8,000 token
- 4xA100 80GBで20時間。100step学習。Adam。batch size 8。learning rate 1.0 x 10^-6。
Multi turn Dataset
| データセット | タスク数 | 構成・特徴 |
|---|---|---|
| BFCL v3 | 100 をtrain、100をeval | 車両制御、トレードbot、旅行予約、ファイルシステム操作、cross-functional API。いくつかのサブカテゴリ - Missing parameter: Agentが欠落した情報を返す - Missing function: ユーザの要求を答えられないことを返す - Long context: 情報量の多いユーザと会話するタスク |
| τ‑bench Airline | 50 (eval) | 航空ドメインにおけるユーザとAgentの会話をシミュレート |
| τ‑bench Retail | 115 (eval) | 小売ドメインにおけるユーザとAgentの会話をシミュレート |
- 評価指標はPass@1 Accで最終回答と一致しているものの割合。
- 実装
Qwen/Qwen2.5-7B-Instructのみ- 8個のロールアウトを温度パラメータ0.9で生成
- 最大Context Windowは16384 tokenで1ロール当たりの最大Responseの長さは2048 token
- 4×A100 80 GBで34時間。Adam。batch size 8。learning rate 1.0 x 10^-6。grad acummulation 4 step。
結果
Complex Math Dataset

- MATH-500は全体的に問題が簡単なので、貢献は小さめ。Olympiadのような難しいタスクほど貢献が大きい。
- Base LLMsからは確かに良くなっているが、DeepSeekに対しては普通に負けてたりする。
- モデルが小さいので仕方ない感はある
- OSSの中では一番強い
- 従来のToRAやPALといった手法より優れたToolの統合と学習方法であることを示した
- Responseの長さは長くなっており、ショートカットせずに多段階の推論をしていることを定量的に示している。

Multi turn Dataset

- Base LLMsからは確かに良くなっているが、GPT-4oに対しては普通に負けてたりする。(Qwen2.5-72Bからの伸びを考えてもそんなにでかいモデルでやっても強くなさそう?データ数が少ないので、増やせばなんとかなるのかも)
- Base ModelからはAirlineなどの難しいタスクで2倍ほどの精度を達成し、訓練も汎用性をちゃんと獲得できていることが分かる。
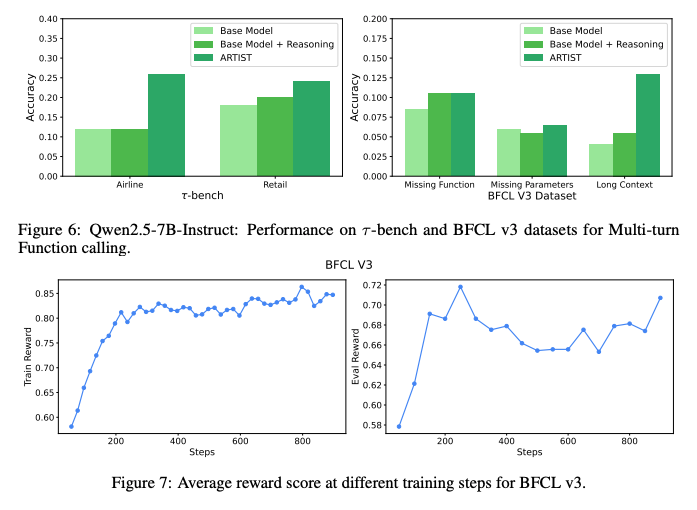
- その他のメトリクス
- ツールの呼び出しごとの推論長:毎回プランニングをしっかりしていることが分かる。
- ツールコールの正解数:正しいツールを呼べている。
- answerまでのステップ数:ツールの呼び出しが多いにも関わらず早めに収束している。無駄な呼び出しが少ない。

結論
- エージェント推論、強化学習、動的にツールを統合し、大規模言語モデルにおける新しい レベルの能力を引き出す新しいフレームワークであるARTISTを紹介した。
- outcomeベースでのGRPOの学習によって、複雑な多段階タスクを自律的に計画、適応、解決することを可能にした。
- さらにより目的を持った形でToolを使用するといった豊かな振る舞いをすることを示した。
- 今後の展望として、人間の嗜好を含むより豊かなFBを統合した学習と安全性と信頼性を兼ね備えたモデルを探求していく。